 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainCQA: Crafting Expert-Level QA from Domain-Specific Charts
Mar 25, 2025



Chart Question Answering (CQA) benchmarks are essential for evaluating the capability of Multimodal Large Language Models (MLLMs) to interpret visual data. However, current benchmarks focus primarily on the evaluation of general-purpose CQA but fail to adequately capture domain-specific challenges. We introduce DomainCQA, a systematic methodology for constructing domain-specific CQA benchmarks, and demonstrate its effectiveness by developing AstroChart, a CQA benchmark in the field of astronomy. Our evaluation shows that chart reasoning and combining chart information with domain knowledge for deeper analysis and summarization, rather than domain-specific knowledge, pose the primary challenge for existing MLLMs, highlighting a critical gap in current benchmarks. By providing a scalable and rigorous framework, DomainCQA enables more precise assessment and improvement of MLLMs for domain-specific applications.
A Survey of AI-Generated Video Evaluation
Oct 24, 2024



The growing capabilities of AI in generating video content have brought forward significant challenges in effectively evaluating these videos. Unlike static images or text, video content involves complex spatial and temporal dynamics which may require a more comprehensive and systematic evaluation of its contents in aspects like video presentation quality, semantic information delivery, alignment with human intentions, and the virtual-reality consistency with our physical world. This survey identifies the emerging field of AI-Generated Video Evaluation (AIGVE), highlighting the importance of assessing how well AI-generated videos align with human perception and meet specific instructions. We provide a structured analysis of existing methodologies that could be potentially used to evaluate AI-generated videos. By outlining the strengths and gaps in current approaches, we advocate for the development of more robust and nuanced evaluation frameworks that can handle the complexities of video content, which include not only the conventional metric-based evaluations, but also the current human-involved evaluations, and the future model-centered evaluations. This survey aims to establish a foundational knowledge base for both researchers from academia and practitioners from the industry, facilitating the future advancement of evaluation methods for AI-generated video content.
ChartKG: A Knowledge-Graph-Based Representation for Chart Images
Oct 13, 2024



Chart images, such as bar charts, pie charts, and line charts, are explosively produced due to the wide usage of data visualizations. Accordingly, knowledge mining from chart images is becoming increasingly important, which can benefit downstream tasks like chart retrieval and knowledge graph completion. However, existing methods for chart knowledge mining mainly focus on converting chart images into raw data and often ignore their visual encodings and semantic meanings, which can result in information loss for many downstream tasks. In this paper, we propose ChartKG, a novel knowledge graph (KG) based representation for chart images, which can model the visual elements in a chart image and semantic relations among them including visual encodings and visual insights in a unified manner. Further, we develop a general framework to convert chart images to the proposed KG-based representation. It integrates a series of image processing techniques to identify visual elements and relations, e.g., CNNs to classify charts, yolov5 and optical character recognition to parse charts, and rule-based methods to construct graphs. We present four cases to illustrate how our knowledge-graph-based representation can model the detailed visual elements and semantic relations in charts, and further demonstrate how our approach can benefit downstream applications such as semantic-aware chart retrieval and chart question answering. We also conduct quantitative evaluations to assess the two fundamental building blocks of our chart-to-KG framework, i.e., object recognition and optical character recognition. The results provide support for the usefulness and effectiveness of ChartKG.
Large Language Models for Robotics: A Survey
Nov 13, 2023



The human ability to learn, generalize, and control complex manipulation tasks through multi-modality feedback suggests a unique capability, which we refer to as dexterity intelligence. Understanding and assessing this intelligence is a complex task. Amidst the swift progress and extensive proliferation of large language models (LLMs), their applications in the field of robotics have garnered increasing attention. LLMs possess the ability to process and generate natural language, facilitating efficient interaction and collaboration with robots. Researchers and engineers in the field of robotics have recognized the immense potential of LLMs in enhancing robot intelligence, human-robot interaction, and autonomy. Therefore, this comprehensive review aims to summarize the applications of LLMs in robotics, delving into their impact and contributions to key areas such as robot control, perception, decision-making, and path planning. We first provide an overview of the background and development of LLMs for robotics, followed by a description of the benefits of LLMs for robotics and recent advancements in robotics models based on LLMs. We then delve into the various techniques used in the model, including those employed in perception, decision-making, control, and interaction. Finally, we explore the applications of LLMs in robotics and some potential challenges they may face in the near future. Embodied intelligence is the future of intelligent science, and LLMs-based robotics is one of the promising but challenging paths to achieve this.
Can We Edit Multimodal Large Language Models?
Oct 13, 2023



In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
Improving Knowledge Distillation via Regularizing Feature Norm and Direction
May 26, 2023



Knowledge distillation (KD) exploits a large well-trained model (i.e., teacher) to train a small student model on the same dataset for the same task. Treating teacher features as knowledge, prevailing methods of knowledge distillation train student by aligning its features with the teacher's, e.g., by minimizing the KL-divergence between their logits or L2 distance between their intermediate features. While it is natural to believe that better alignment of student features to the teacher better distills teacher knowledge, simply forcing this alignment does not directly contribute to the student's performance, e.g., classification accuracy. In this work, we propose to align student features with class-mean of teacher features, where class-mean naturally serves as a strong classifier. To this end, we explore baseline techniques such as adopting the cosine distance based loss to encourage the similarity between student features and their corresponding class-means of the teacher. Moreover, we train the student to produce large-norm features, inspired by other lines of work (e.g., model pruning and domain adaptation), which find the large-norm features to be more significant. Finally, we propose a rather simple loss term (dubbed ND loss) to simultaneously (1) encourage student to produce large-\emph{norm} features, and (2) align the \emph{direction} of student features and teacher class-means. Experiments on standard benchmarks demonstrate that our explored techniques help existing KD methods achieve better performance, i.e., higher classification accuracy on ImageNet and CIFAR100 datasets, and higher detection precision on COCO dataset. Importantly, our proposed ND loss helps the most, leading to the state-of-the-art performance on these benchmarks. The source code is available at \url{https://github.com/WangYZ1608/Knowledge-Distillation-via-ND}.
Continual Multimodal Knowledge Graph Construction
May 15, 2023



Multimodal Knowledge Graph Construction (MMKC) refers to the process of creating a structured representation of entities and relationships through multiple modalities such as text, images, videos, etc. However, existing MMKC models have limitations in handling the introduction of new entities and relations due to the dynamic nature of the real world. Moreover, most state-of-the-art studies in MMKC only consider entity and relation extraction from text data while neglecting other multi-modal sources. Meanwhile, the current continual setting for knowledge graph construction only consider entity and relation extraction from text data while neglecting other multi-modal sources. Therefore, there arises the need to explore the challenge of continuous multimodal knowledge graph construction to address the phenomenon of catastrophic forgetting and ensure the retention of past knowledge extracted from different forms of data. This research focuses on investigating this complex topic by developing lifelong multimodal benchmark datasets. Based on the empirical findings that several state-of-the-art MMKC models, when trained on multimedia data, might unexpectedly underperform compared to those solely utilizing textual resources in a continual setting, we propose a Lifelong MultiModal Consistent Transformer Framework (LMC) for continuous multimodal knowledge graph construction. By combining the advantages of consistent KGC strategies within the context of continual learning, we achieve greater balance between stability and plasticity. Our experiments demonstrate the superior performance of our method over prevailing continual learning techniques or multimodal approaches in dynamic scenarios. Code and datasets can be found at https://github.com/zjunlp/ContinueMKGC.
SimCGNN: Simple Contrastive Graph Neural Network for Session-based Recommendation
Feb 08, 2023



Session-based recommendation (SBR) problem, which focuses on next-item prediction for anonymous users, has received increasingly more attention from researchers. Existing graph-based SBR methods all lack the ability to differentiate between sessions with the same last item, and suffer from severe popularity bias. Inspired by nowadays emerging contrastive learning methods, this paper presents a Simple Contrastive Graph Neural Network for Session-based Recommendation (SimCGNN). In SimCGNN, we first obtain normalized session embeddings on constructed session graphs. We next construct positive and negative samples of the sessions by two forward propagation and a novel negative sample selection strategy, and then calculate the constructive loss. Finally, session embeddings are used to give prediction. Extensive experiments conducted on two real-word datasets show our SimCGNN achieves a significant improvement over state-of-the-art methods.
Ensemble Clustering via Co-association Matrix Self-enhancement
May 12, 2022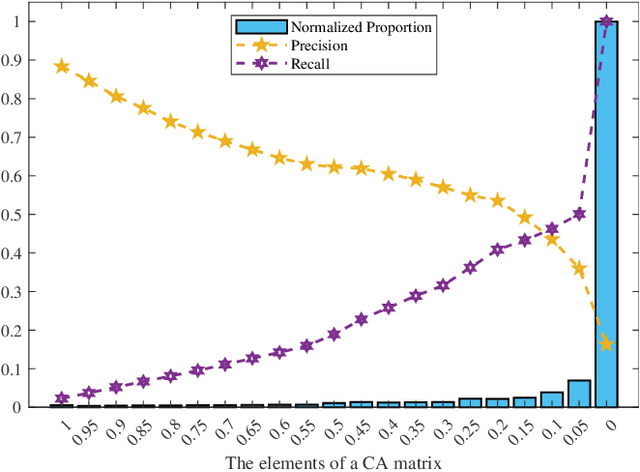
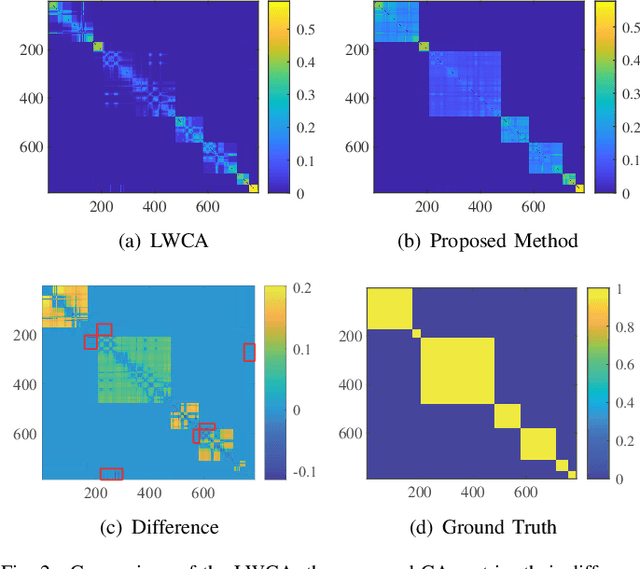
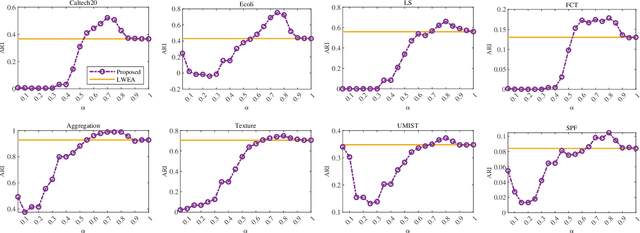
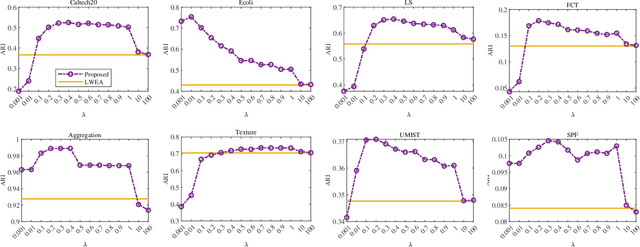
Ensemble clustering integrates a set of base clustering results to generate a stronger one. Existing methods usually rely on a co-association (CA) matrix that measures how many times two samples are grouped into the same cluster according to the base clusterings to achieve ensemble clustering. However, when the constructed CA matrix is of low quality, the performance will degrade. In this paper, we propose a simple yet effective CA matrix self-enhancement framework that can improve the CA matrix to achieve better clustering performance. Specifically, we first extract the high-confidence (HC) information from the base clusterings to form a sparse HC matrix. By propagating the highly-reliable information of the HC matrix to the CA matrix and complementing the HC matrix according to the CA matrix simultaneously, the proposed method generates an enhanced CA matrix for better clustering. Technically, the proposed model is formulated as a symmetric constrained convex optimization problem, which is efficiently solved by an alternating iterative algorithm with convergence and global optimum theoretically guaranteed. Extensive experimental comparisons with twelve state-of-the-art methods on eight benchmark datasets substantiate the effectiveness, flexibility and efficiency of the proposed model in ensemble clustering. The codes and datasets can be downloaded at https://github.com/Siritao/EC-CMS.