 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Differential Diagnosis with Large Language Models
Nov 30, 2023



An accurate differential diagnosis (DDx) is a cornerstone of medical care, often reached through an iterative process of interpretation that combines clinical history, physical examination, investigations and procedures. Interactive interfaces powered by Large Language Models (LLMs) present new opportunities to both assist and automate aspects of this process. In this study, we introduce an LLM optimized for diagnostic reasoning, and evaluate its ability to generate a DDx alone or as an aid to clinicians. 20 clinicians evaluated 302 challenging, real-world medical cases sourced from the New England Journal of Medicine (NEJM) case reports. Each case report was read by two clinicians, who were randomized to one of two assistive conditions: either assistance from search engines and standard medical resources, or LLM assistance in addition to these tools. All clinicians provided a baseline, unassisted DDx prior to using the respective assistive tools. Our LLM for DDx exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% vs 33.6%, [p = 0.04]). Comparing the two assisted study arms, the DDx quality score was higher for clinicians assisted by our LLM (top-10 accuracy 51.7%) compared to clinicians without its assistance (36.1%) (McNemar's Test: 45.7, p < 0.01) and clinicians with search (44.4%) (4.75, p = 0.03). Further, clinicians assisted by our LLM arrived at more comprehensive differential lists than those without its assistance. Our study suggests that our LLM for DDx has potential to improve clinicians' diagnostic reasoning and accuracy in challenging cases, meriting further real-world evaluation for its ability to empower physicians and widen patients' access to specialist-level expertise.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Mu$^{2}$SLAM: Multitask, Multilingual Speech and Language Models
Dec 19, 2022



We present Mu$^{2}$SLAM, a multilingual sequence-to-sequence model pre-trained jointly on unlabeled speech, unlabeled text and supervised data spanning Automatic Speech Recognition (ASR), Automatic Speech Translation (AST) and Machine Translation (MT), in over 100 languages. By leveraging a quantized representation of speech as a target, Mu$^{2}$SLAM trains the speech-text models with a sequence-to-sequence masked denoising objective similar to T5 on the decoder and a masked language modeling (MLM) objective on the encoder, for both unlabeled speech and text, while utilizing the supervised tasks to improve cross-lingual and cross-modal representation alignment within the model. On CoVoST AST, Mu$^{2}$SLAM establishes a new state-of-the-art for models trained on public datasets, improving on xx-en translation over the previous best by 1.9 BLEU points and on en-xx translation by 1.1 BLEU points. On Voxpopuli ASR, our model matches the performance of an mSLAM model fine-tuned with an RNN-T decoder, despite using a relatively weaker sequence-to-sequence architecture. On text understanding tasks, our model improves by more than 6\% over mSLAM on XNLI, getting closer to the performance of mT5 models of comparable capacity on XNLI and TydiQA, paving the way towards a single model for all speech and text understanding tasks.
MAGVIT: Masked Generative Video Transformer
Dec 10, 2022



We introduce the MAsked Generative VIdeo Transformer, MAGVIT, to tackle various video synthesis tasks with a single model. We introduce a 3D tokenizer to quantize a video into spatial-temporal visual tokens and propose an embedding method for masked video token modeling to facilitate multi-task learning. We conduct extensive experiments to demonstrate the quality, efficiency, and flexibility of MAGVIT. Our experiments show that (i) MAGVIT performs favorably against state-of-the-art approaches and establishes the best-published FVD on three video generation benchmarks, including the challenging Kinetics-600. (ii) MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60x against autoregressive models. (iii) A single MAGVIT model supports ten diverse generation tasks and generalizes across videos from different visual domains. The source code and trained models will be released to the public at https://magvit.cs.cmu.edu.
Mastering Autonomous Assembly in Fusion Application with Learning-by-doing: a Peg-in-hole Study
Aug 24, 2022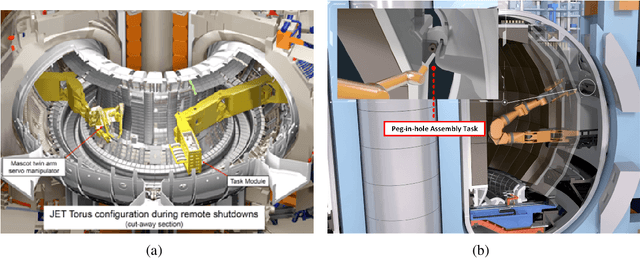

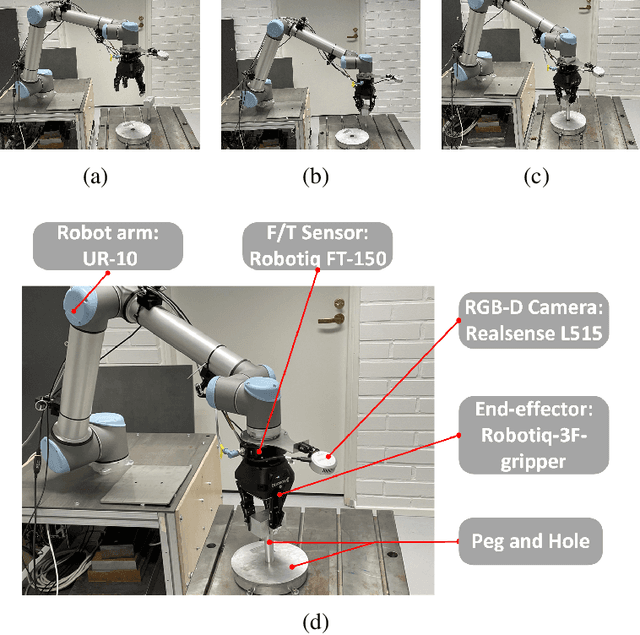
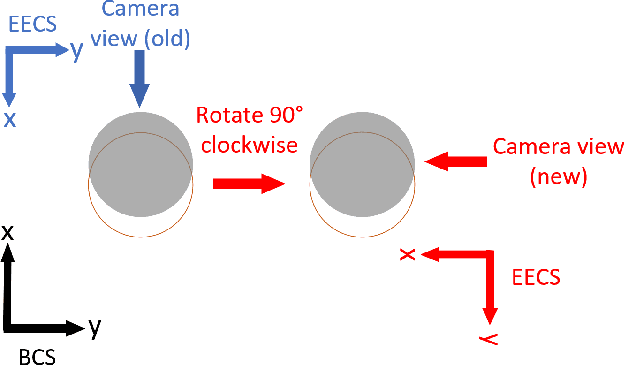
Robotic peg-in-hole assembly is an essential task in robotic automation research. Reinforcement learning (RL) combined with deep neural networks (DNNs) lead to extraordinary achievements in this area. However, current RL-based approaches could hardly perform well under the unique environmental and mission requirements of fusion applications. Therefore, we have proposed a new designed RL-based method. Furthermore, unlike other approaches, we focus on innovations in the structure of DNNs instead of the RL model. Data from the RGB camera and force/torque (F/T) sensor as the input are fed into a multi-input branch network, and the best action in the current state is output by the network. All training and experiments are carried out in a realistic environment, and from the experiment result, this multi-sensor fusion approach has been shown to work well in rigid peg-in-hole assembly tasks with 0.1mm precision in uncertain and unstable environments.
BlindFL: Vertical Federated Machine Learning without Peeking into Your Data
Jun 16, 2022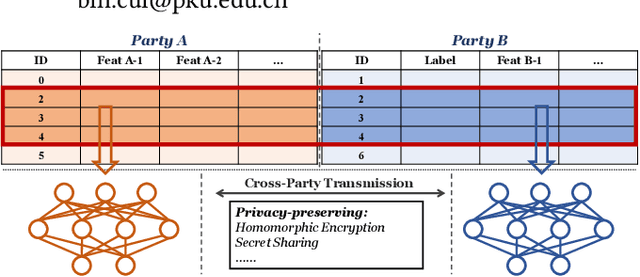
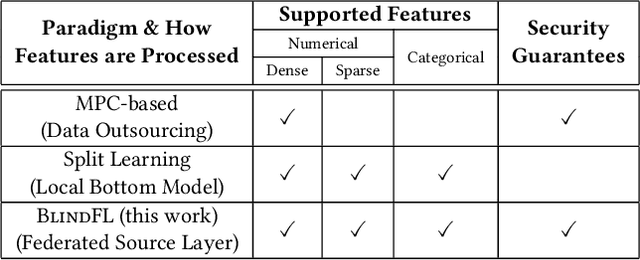


Due to the rising concerns on privacy protection, how to build machine learning (ML) models over different data sources with security guarantees is gaining more popularity. Vertical federated learning (VFL) describes such a case where ML models are built upon the private data of different participated parties that own disjoint features for the same set of instances, which fits many real-world collaborative tasks. Nevertheless, we find that existing solutions for VFL either support limited kinds of input features or suffer from potential data leakage during the federated execution. To this end, this paper aims to investigate both the functionality and security of ML modes in the VFL scenario. To be specific, we introduce BlindFL, a novel framework for VFL training and inference. First, to address the functionality of VFL models, we propose the federated source layers to unite the data from different parties. Various kinds of features can be supported efficiently by the federated source layers, including dense, sparse, numerical, and categorical features. Second, we carefully analyze the security during the federated execution and formalize the privacy requirements. Based on the analysis, we devise secure and accurate algorithm protocols, and further prove the security guarantees under the ideal-real simulation paradigm. Extensive experiments show that BlindFL supports diverse datasets and models efficiently whilst achieves robust privacy guarantees.
Semi-Supervised Cross-Silo Advertising with Partial Knowledge Transfer
May 31, 2022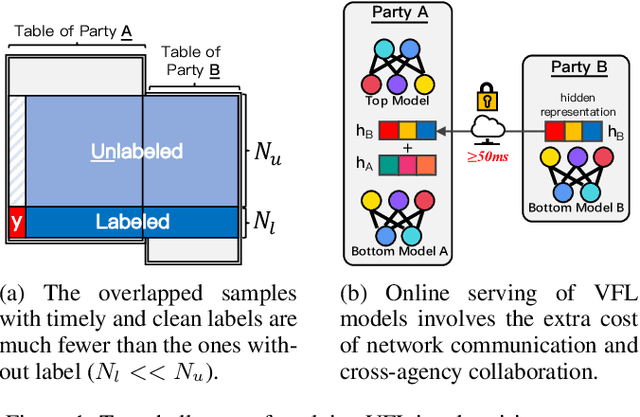
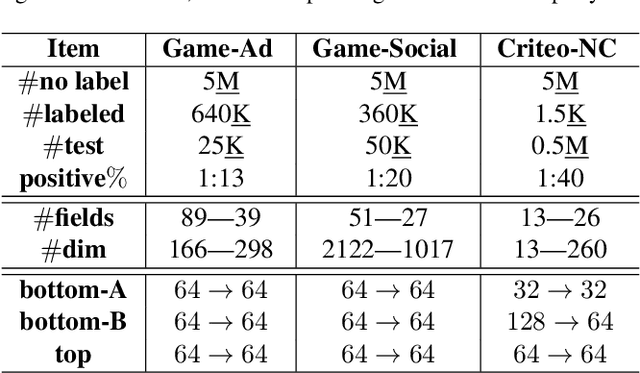
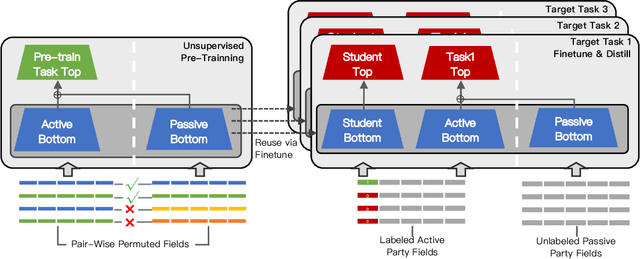
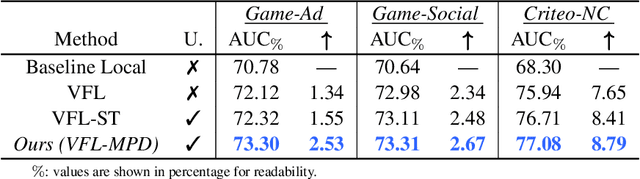
As an emerging secure learning paradigm in leveraging cross-agency private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, there are two key challenges in applying it to advertising systems: a) the limited scale of labeled overlapping samples, and b) the high cost of real-time cross-agency serving. In this paper, we propose a semi-supervised split distillation framework VFed-SSD to alleviate the two limitations. We identify that: i) there are massive unlabeled overlapped data available in advertising systems, and ii) we can keep a balance between model performance and inference cost by decomposing the federated model. Specifically, we develop a self-supervised task Matched Pair Detection (MPD) to exploit the vertically partitioned unlabeled data and propose the Split Knowledge Distillation (SplitKD) schema to avoid cross-agency serving. Empirical studies on three industrial datasets exhibit the effectiveness of our methods, with the median AUC over all datasets improved by 0.86% and 2.6% in the local deployment mode and the federated deployment mode respectively. Overall, our framework provides an efficient federation-enhanced solution for real-time display advertising with minimal deploying cost and significant performance lift.
Multilingual Mix: Example Interpolation Improves Multilingual Neural Machine Translation
Mar 15, 2022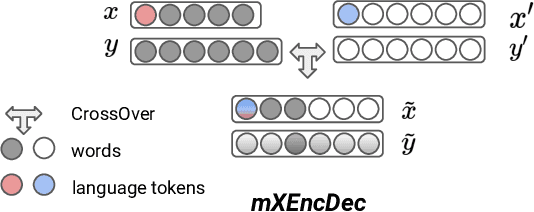
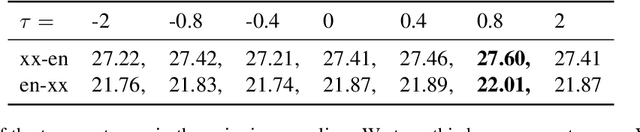
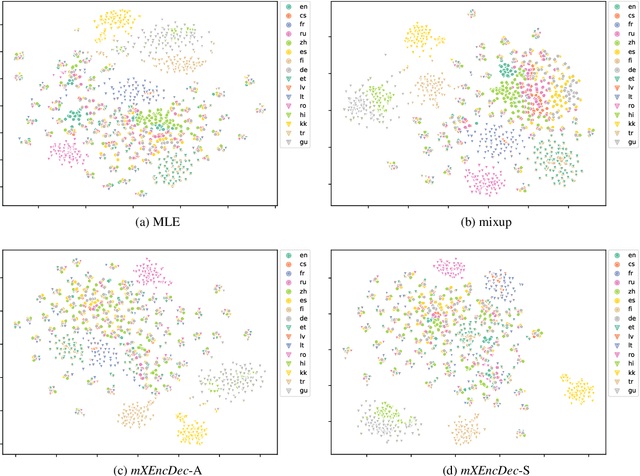
Multilingual neural machine translation models are trained to maximize the likelihood of a mix of examples drawn from multiple language pairs. The dominant inductive bias applied to these models is a shared vocabulary and a shared set of parameters across languages; the inputs and labels corresponding to examples drawn from different language pairs might still reside in distinct sub-spaces. In this paper, we introduce multilingual crossover encoder-decoder (mXEncDec) to fuse language pairs at an instance level. Our approach interpolates instances from different language pairs into joint `crossover examples' in order to encourage sharing input and output spaces across languages. To ensure better fusion of examples in multilingual settings, we propose several techniques to improve example interpolation across dissimilar languages under heavy data imbalance. Experiments on a large-scale WMT multilingual dataset demonstrate that our approach significantly improves quality on English-to-Many, Many-to-English and zero-shot translation tasks (from +0.5 BLEU up to +5.5 BLEU points). Results on code-switching sets demonstrate the capability of our approach to improve model generalization to out-of-distribution multilingual examples. We also conduct qualitative and quantitative representation comparisons to analyze the advantages of our approach at the representation level.