 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
Aug 21, 2024Video saliency prediction aims to identify the regions in a video that attract human attention and gaze, driven by bottom-up features from the video and top-down processes like memory and cognition. Among these top-down influences, language plays a crucial role in guiding attention by shaping how visual information is interpreted. Existing methods primarily focus on modeling perceptual information while neglecting the reasoning process facilitated by language, where ranking cues are crucial outcomes of this process and practical guidance for saliency prediction. In this paper, we propose CaRDiff (Caption, Rank, and generate with Diffusion), a framework that imitates the process by integrating a multimodal large language model (MLLM), a grounding module, and a diffusion model, to enhance video saliency prediction. Specifically, we introduce a novel prompting method VSOR-CoT (Video Salient Object Ranking Chain of Thought), which utilizes an MLLM with a grounding module to caption video content and infer salient objects along with their rankings and positions. This process derives ranking maps that can be sufficiently leveraged by the diffusion model to decode the saliency maps for the given video accurately. Extensive experiments show the effectiveness of VSOR-CoT in improving the performance of video saliency prediction. The proposed CaRDiff performs better than state-of-the-art models on the MVS dataset and demonstrates cross-dataset capabilities on the DHF1k dataset through zero-shot evaluation.
Modular Blind Video Quality Assessment
Mar 13, 2024



Blind video quality assessment (BVQA) plays a pivotal role in evaluating and improving the viewing experience of end-users across a wide range of video-based platforms and services. Contemporary deep learning-based models primarily analyze the video content in its aggressively downsampled format, while being blind to the impact of actual spatial resolution and frame rate on video quality. In this paper, we propose a modular BVQA model, and a method of training it to improve its modularity. Specifically, our model comprises a base quality predictor, a spatial rectifier, and a temporal rectifier, responding to the visual content and distortion, spatial resolution, and frame rate changes on video quality, respectively. During training, spatial and temporal rectifiers are dropped out with some probabilities so as to make the base quality predictor a standalone BVQA model, which should work better with the rectifiers. Extensive experiments on both professionally-generated content and user generated content video databases show that our quality model achieves superior or comparable performance to current methods. Furthermore, the modularity of our model offers a great opportunity to analyze existing video quality databases in terms of their spatial and temporal complexities. Last, our BVQA model is cost-effective to add other quality-relevant video attributes such as dynamic range and color gamut as additional rectifiers.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021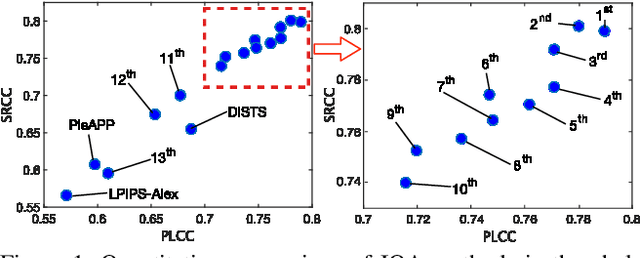
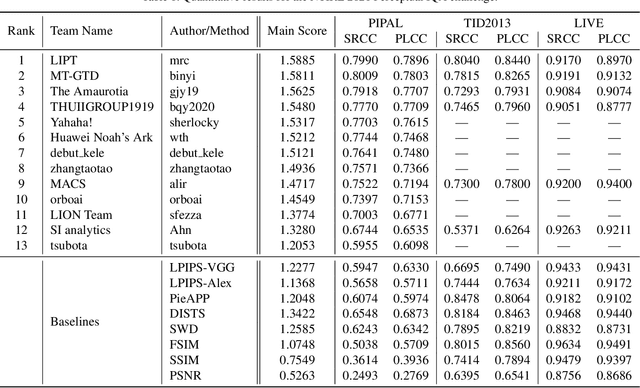

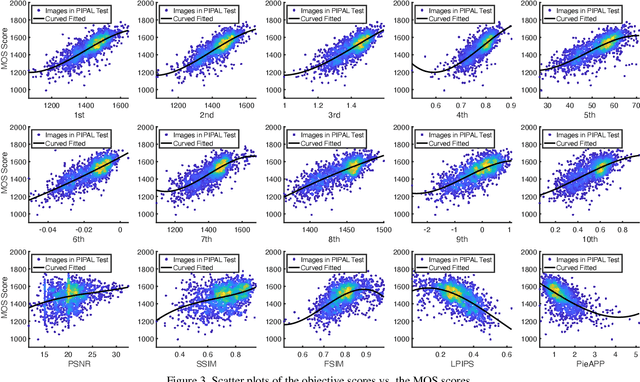
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021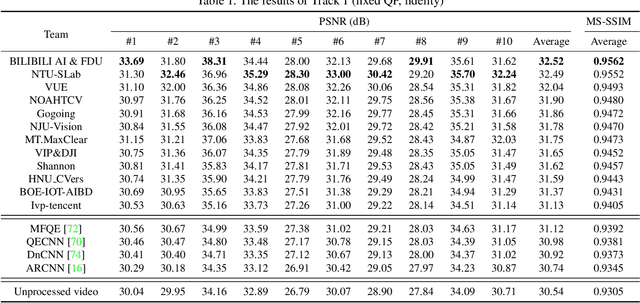
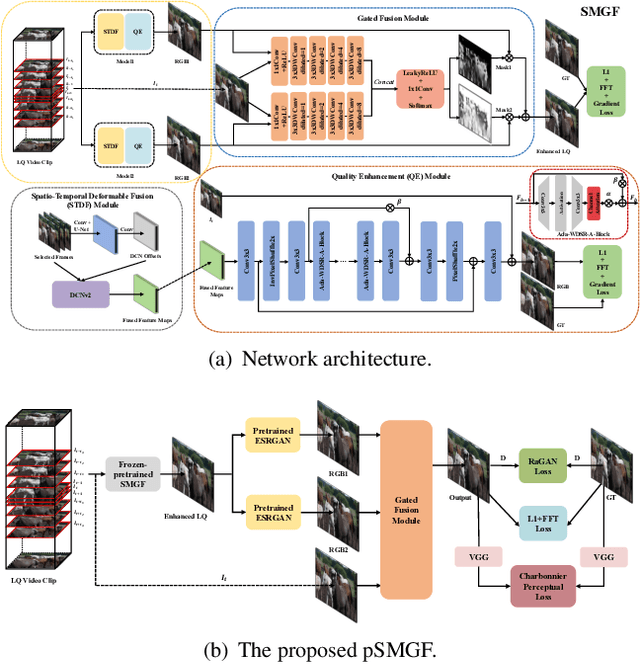
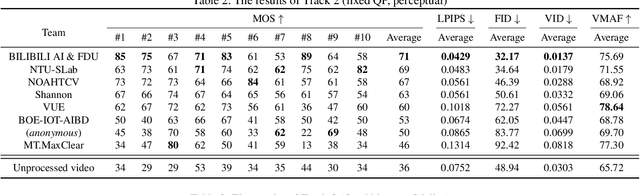
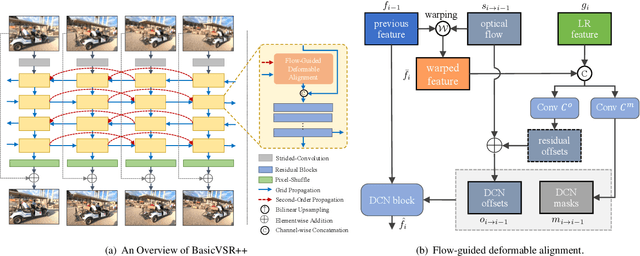
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh