 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation from First Principles: Integrating Core Information Extraction and Purposeful Learning
Sep 02, 2024



Dataset distillation (DD) is an increasingly important technique that focuses on constructing a synthetic dataset capable of capturing the core information in training data to achieve comparable performance in models trained on the latter. While DD has a wide range of applications, the theory supporting it is less well evolved. New methods of DD are compared on a common set of benchmarks, rather than oriented towards any particular learning task. In this work, we present a formal model of DD, arguing that a precise characterization of the underlying optimization problem must specify the inference task associated with the application of interest. Without this task-specific focus, the DD problem is under-specified, and the selection of a DD algorithm for a particular task is merely heuristic. Our formalization reveals novel applications of DD across different modeling environments. We analyze existing DD methods through this broader lens, highlighting their strengths and limitations in terms of accuracy and faithfulness to optimal DD operation. Finally, we present numerical results for two case studies important in contemporary settings. Firstly, we address a critical challenge in medical data analysis: merging the knowledge from different datasets composed of intersecting, but not identical, sets of features, in order to construct a larger dataset in what is usually a small sample setting. Secondly, we consider out-of-distribution error across boundary conditions for physics-informed neural networks (PINNs), showing the potential for DD to provide more physically faithful data. By establishing this general formulation of DD, we aim to establish a new research paradigm by which DD can be understood and from which new DD techniques can arise.
PatternPaint: Generating Layout Patterns Using Generative AI and Inpainting Techniques
Sep 02, 2024



Generation of VLSI layout patterns is essential for a wide range of Design For Manufacturability (DFM) studies. In this study, we investigate the potential of generative machine learning models for creating design rule legal metal layout patterns. Our results demonstrate that the proposed model can generate legal patterns in complex design rule settings and achieves a high diversity score. The designed system, with its flexible settings, supports both pattern generation with localized changes, and design rule violation correction. Our methodology is validated on Intel 18A Process Design Kit (PDK) and can produce a wide range of DRC-compliant pattern libraries with only 20 starter patterns.
CinePreGen: Camera Controllable Video Previsualization via Engine-powered Diffusion
Aug 30, 2024With advancements in video generative AI models (e.g., SORA), creators are increasingly using these techniques to enhance video previsualization. However, they face challenges with incomplete and mismatched AI workflows. Existing methods mainly rely on text descriptions and struggle with camera placement, a key component of previsualization. To address these issues, we introduce CinePreGen, a visual previsualization system enhanced with engine-powered diffusion. It features a novel camera and storyboard interface that offers dynamic control, from global to local camera adjustments. This is combined with a user-friendly AI rendering workflow, which aims to achieve consistent results through multi-masked IP-Adapter and engine simulation guidelines. In our comprehensive evaluation study, we demonstrate that our system reduces development viscosity (i.e., the complexity and challenges in the development process), meets users' needs for extensive control and iteration in the design process, and outperforms other AI video production workflows in cinematic camera movement, as shown by our experiments and a within-subjects user study. With its intuitive camera controls and realistic rendering of camera motion, CinePreGen shows great potential for improving video production for both individual creators and industry professionals.
Criticality Leveraged Adversarial Training (CLAT) for Boosted Performance via Parameter Efficiency
Aug 19, 2024



Adversarial training enhances neural network robustness but suffers from a tendency to overfit and increased generalization errors on clean data. This work introduces CLAT, an innovative approach that mitigates adversarial overfitting by introducing parameter efficiency into the adversarial training process, improving both clean accuracy and adversarial robustness. Instead of tuning the entire model, CLAT identifies and fine-tunes robustness-critical layers - those predominantly learning non-robust features - while freezing the remaining model to enhance robustness. It employs dynamic critical layer selection to adapt to changes in layer criticality throughout the fine-tuning process. Empirically, CLAT can be applied on top of existing adversarial training methods, significantly reduces the number of trainable parameters by approximately 95%, and achieves more than a 2% improvement in adversarial robustness compared to baseline methods.
LaMAGIC: Language-Model-based Topology Generation for Analog Integrated Circuits
Jul 19, 2024



In the realm of electronic and electrical engineering, automation of analog circuit is increasingly vital given the complexity and customized requirements of modern applications. However, existing methods only develop search-based algorithms that require many simulation iterations to design a custom circuit topology, which is usually a time-consuming process. To this end, we introduce LaMAGIC, a pioneering language model-based topology generation model that leverages supervised finetuning for automated analog circuit design. LaMAGIC can efficiently generate an optimized circuit design from the custom specification in a single pass. Our approach involves a meticulous development and analysis of various input and output formulations for circuit. These formulations can ensure canonical representations of circuits and align with the autoregressive nature of LMs to effectively addressing the challenges of representing analog circuits as graphs. The experimental results show that LaMAGIC achieves a success rate of up to 96\% under a strict tolerance of 0.01. We also examine the scalability and adaptability of LaMAGIC, specifically testing its performance on more complex circuits. Our findings reveal the enhanced effectiveness of our adjacency matrix-based circuit formulation with floating-point input, suggesting its suitability for handling intricate circuit designs. This research not only demonstrates the potential of language models in graph generation, but also builds a foundational framework for future explorations in automated analog circuit design.
MonoSparse-CAM: Harnessing Monotonicity and Sparsity for Enhanced Tree Model Processing on CAMs
Jul 12, 2024



Despite significant advancements in AI driven by neural networks, tree-based machine learning (TBML) models excel on tabular data. These models exhibit promising energy efficiency, and high performance, particularly when accelerated on analog content-addressable memory (aCAM) arrays. However, optimizing their hardware deployment, especially in leveraging TBML model structure and aCAM circuitry, remains challenging. In this paper, we introduce MonoSparse-CAM, a novel content-addressable memory (CAM) based computing optimization technique. MonoSparse-CAM efficiently leverages TBML model sparsity and CAM array circuits, enhancing processing performance. Our experiments show that MonoSparse-CAM reduces energy consumption by up to 28.56x compared to raw processing and 18.51x compared to existing deployment optimization techniques. Additionally, it consistently achieves at least 1.68x computational efficiency over current methods. By enabling energy-efficient CAM-based computing while preserving performance regardless of the array sparsity, MonoSparse-CAM addresses the high energy consumption problem of CAM which hinders processing of large arrays. Our contributions are twofold: we propose MonoSparse-CAM as an effective deployment optimization solution for CAM-based computing, and we investigate the impact of TBML model structure on array sparsity. This work provides crucial insights for energy-efficient TBML on hardware, highlighting a significant advancement in sustainable AI technologies.
ARTIST: Improving the Generation of Text-rich Images by Disentanglement
Jun 17, 2024



Diffusion models have demonstrated exceptional capabilities in generating a broad spectrum of visual content, yet their proficiency in rendering text is still limited: they often generate inaccurate characters or words that fail to blend well with the underlying image. To address these shortcomings, we introduce a new framework named ARTIST. This framework incorporates a dedicated textual diffusion model to specifically focus on the learning of text structures. Initially, we pretrain this textual model to capture the intricacies of text representation. Subsequently, we finetune a visual diffusion model, enabling it to assimilate textual structure information from the pretrained textual model. This disentangled architecture design and the training strategy significantly enhance the text rendering ability of the diffusion models for text-rich image generation. Additionally, we leverage the capabilities of pretrained large language models to better interpret user intentions, contributing to improved generation quality. Empirical results on the MARIO-Eval benchmark underscore the effectiveness of the proposed method, showing an improvement of up to 15\% in various metrics.
PhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Jun 17, 2024
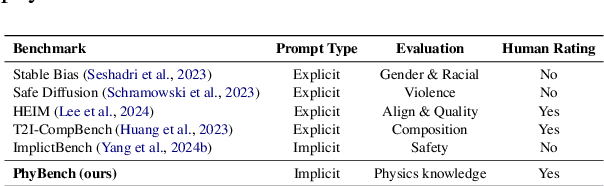

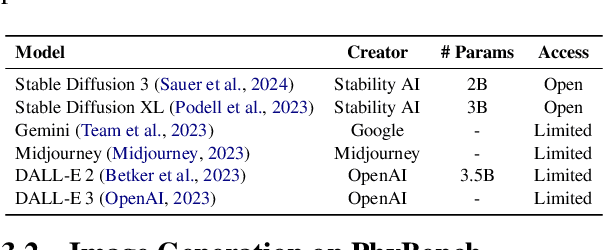
Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.
Can Dense Connectivity Benefit Outlier Detection? An Odyssey with NAS
Jun 04, 2024



Recent advances in Out-of-Distribution (OOD) Detection is the driving force behind safe and reliable deployment of Convolutional Neural Networks (CNNs) in real world applications. However, existing studies focus on OOD detection through confidence score and deep generative model-based methods, without considering the impact of DNN structures, especially dense connectivity in architecture fabrications. In addition, existing outlier detection approaches exhibit high variance in generalization performance, lacking stability and confidence in evaluating and ranking different outlier detectors. In this work, we propose a novel paradigm, Dense Connectivity Search of Outlier Detector (DCSOD), that automatically explore the dense connectivity of CNN architectures on near-OOD detection task using Neural Architecture Search (NAS). We introduce a hierarchical search space containing versatile convolution operators and dense connectivity, allowing a flexible exploration of CNN architectures with diverse connectivity patterns. To improve the quality of evaluation on OOD detection during search, we propose evolving distillation based on our multi-view feature learning explanation. Evolving distillation stabilizes training for OOD detection evaluation, thus improves the quality of search. We thoroughly examine DCSOD on CIFAR benchmarks under OOD detection protocol. Experimental results show that DCSOD achieve remarkable performance over widely used architectures and previous NAS baselines. Notably, DCSOD achieves state-of-the-art (SOTA) performance on CIFAR benchmark, with AUROC improvement of $\sim$1.0%.
Knowledge Graph Tuning: Real-time Large Language Model Personalization based on Human Feedback
May 30, 2024



Large language models (LLMs) have demonstrated remarkable proficiency in a range of natural language processing tasks. Once deployed, LLMs encounter users with personalized factual knowledge, and such personalized knowledge is consistently reflected through users' interactions with the LLMs. To enhance user experience, real-time model personalization is essential, allowing LLMs to adapt user-specific knowledge based on user feedback during human-LLM interactions. Existing methods mostly require back-propagation to finetune the model parameters, which incurs high computational and memory costs. In addition, these methods suffer from low interpretability, which will cause unforeseen impacts on model performance during long-term use, where the user's personalized knowledge is accumulated extensively.To address these challenges, we propose Knowledge Graph Tuning (KGT), a novel approach that leverages knowledge graphs (KGs) to personalize LLMs. KGT extracts personalized factual knowledge triples from users' queries and feedback and optimizes KGs without modifying the LLM parameters. Our method improves computational and memory efficiency by avoiding back-propagation and ensures interpretability by making the KG adjustments comprehensible to humans.Experiments with state-of-the-art LLMs, including GPT-2, Llama2, and Llama3, show that KGT significantly improves personalization performance while reducing latency and GPU memory costs. Ultimately, KGT offers a promising solution of effective, efficient, and interpretable real-time LLM personalization during user interactions with the LLMs.