 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashFPS: Efficient Farthest Point Sampling for Large-Scale Point Clouds via Pruning and Caching
Apr 20, 2026Point-based Neural Networks (PNNs) have become a key approach for point cloud processing. However, a core operation in these models, Farthest Point Sampling (FPS), often introduces significant inference latency, especially for large-scale processing. Despite existing CUDA- and hardware-level optimizations, FPS remains a major bottleneck due to exhaustive computations across multiple network layers in PNNs, which hinders scalability. Through systematic analysis, we identify three substantial redundancies in FPS, including unnecessary full-cloud computations, redundant late-stage iterations, and predictable inter-layer outputs that make later FPS computations avoidable. To address these, we propose \textbf{\textit{FlashFPS}}, a hardware-agnostic, plug-and-play framework for FPS acceleration, composed of \textit{FPS-Prune} and \textit{FPS-Cache}. \textit{FPS-Prune} introduces candidate pruning and iteration pruning to reduce redundant computations in FPS while preserving sampling quality, and \textit{FPS-Cache} eliminates layer-wise redundancy via cache-and-reuse. Integrated into existing CUDA libraries and state-of-the-art PNN accelerators, \textit{FlashFPS} achieves 5.16$\times$ speedup over the standard CUDA baseline on GPU and 2.69$\times$ on PNN accelerators, with negligible accuracy loss, enabling efficient and scalable PNN inference. Codes are released at https://github.com/Yuzhe-Fu/FlashFPS.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
MonoSparse-CAM: Harnessing Monotonicity and Sparsity for Enhanced Tree Model Processing on CAMs
Jul 12, 2024



Despite significant advancements in AI driven by neural networks, tree-based machine learning (TBML) models excel on tabular data. These models exhibit promising energy efficiency, and high performance, particularly when accelerated on analog content-addressable memory (aCAM) arrays. However, optimizing their hardware deployment, especially in leveraging TBML model structure and aCAM circuitry, remains challenging. In this paper, we introduce MonoSparse-CAM, a novel content-addressable memory (CAM) based computing optimization technique. MonoSparse-CAM efficiently leverages TBML model sparsity and CAM array circuits, enhancing processing performance. Our experiments show that MonoSparse-CAM reduces energy consumption by up to 28.56x compared to raw processing and 18.51x compared to existing deployment optimization techniques. Additionally, it consistently achieves at least 1.68x computational efficiency over current methods. By enabling energy-efficient CAM-based computing while preserving performance regardless of the array sparsity, MonoSparse-CAM addresses the high energy consumption problem of CAM which hinders processing of large arrays. Our contributions are twofold: we propose MonoSparse-CAM as an effective deployment optimization solution for CAM-based computing, and we investigate the impact of TBML model structure on array sparsity. This work provides crucial insights for energy-efficient TBML on hardware, highlighting a significant advancement in sustainable AI technologies.
RED: A ReRAM-based Deconvolution Accelerator
Jul 05, 2019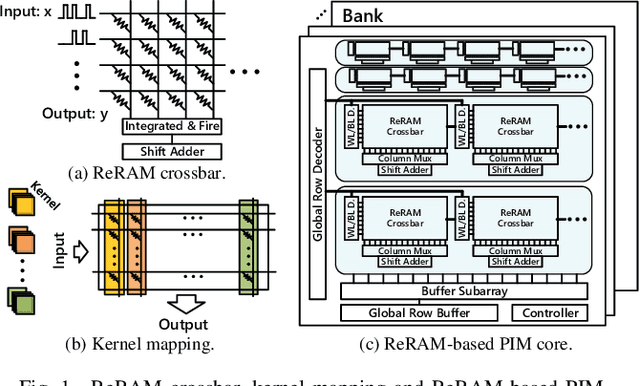

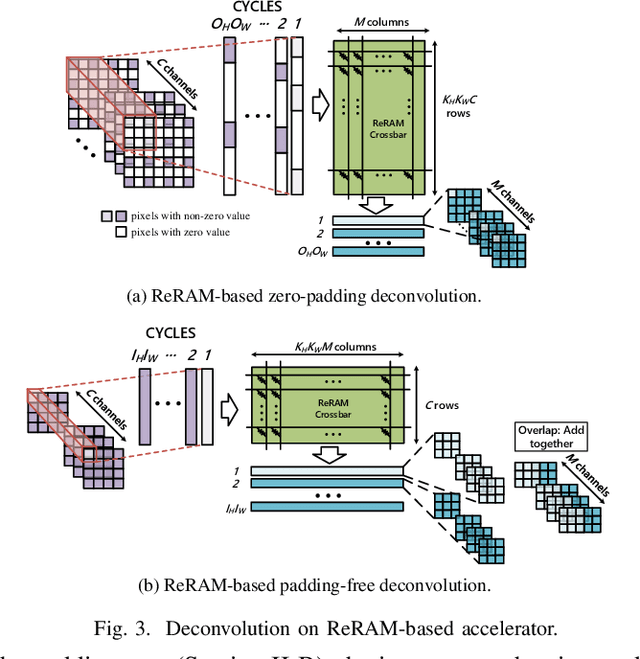
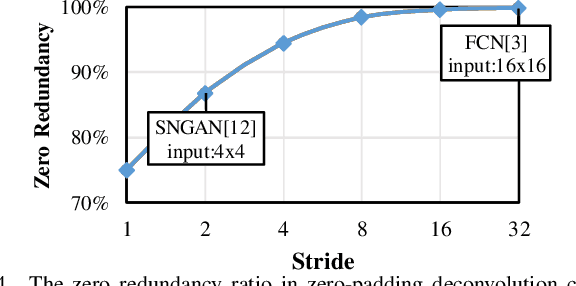
Deconvolution has been widespread in neural networks. For example, it is essential for performing unsupervised learning in generative adversarial networks or constructing fully convolutional networks for semantic segmentation. Resistive RAM (ReRAM)-based processing-in-memory architecture has been widely explored in accelerating convolutional computation and demonstrates good performance. Performing deconvolution on existing ReRAM-based accelerator designs, however, suffers from long latency and high energy consumption because deconvolutional computation includes not only convolution but also extra add-on operations. To realize the more efficient execution for deconvolution, we analyze its computation requirement and propose a ReRAM-based accelerator design, namely, RED. More specific, RED integrates two orthogonal methods, the pixel-wise mapping scheme for reducing redundancy caused by zero-inserting operations and the zero-skipping data flow for increasing the computation parallelism and therefore improving performance. Experimental evaluations show that compared to the state-of-the-art ReRAM-based accelerator, RED can speed up operation 3.69x~1.15x and reduce 8%~88.36% energy consumption.
An Overview of In-memory Processing with Emerging Non-volatile Memory for Data-intensive Applications
Jun 15, 2019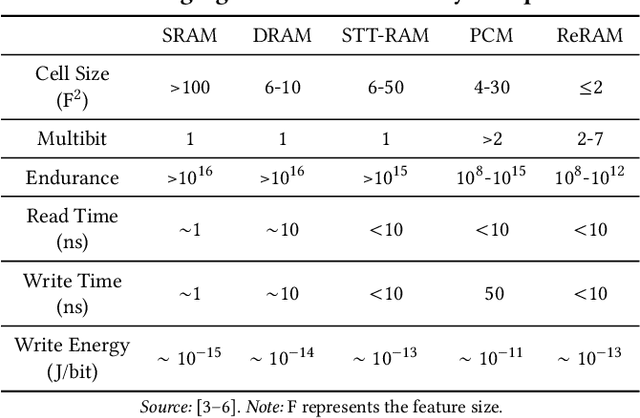
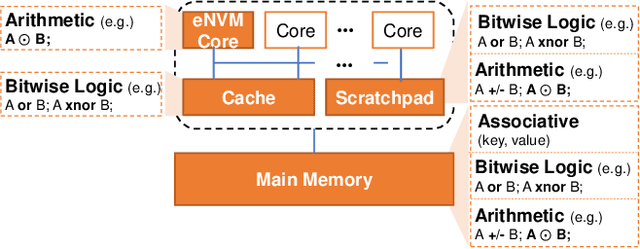
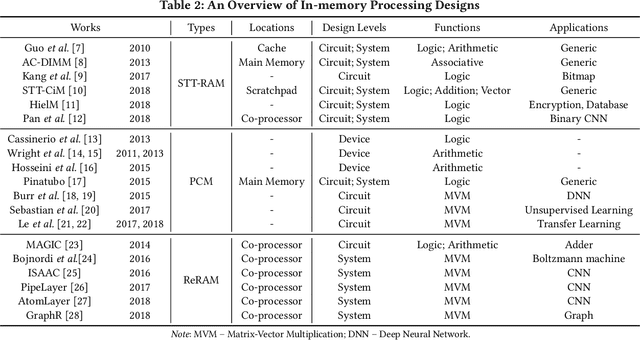
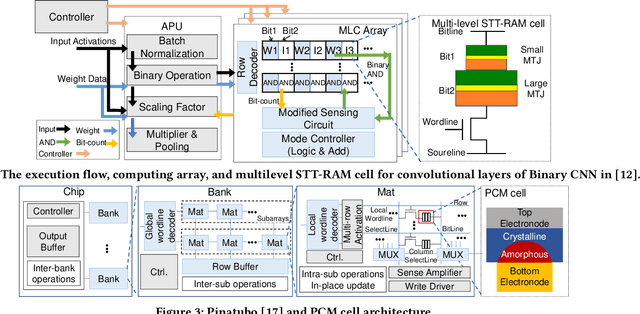
The conventional von Neumann architecture has been revealed as a major performance and energy bottleneck for rising data-intensive applications. %, due to the intensive data movements. The decade-old idea of leveraging in-memory processing to eliminate substantial data movements has returned and led extensive research activities. The effectiveness of in-memory processing heavily relies on memory scalability, which cannot be satisfied by traditional memory technologies. Emerging non-volatile memories (eNVMs) that pose appealing qualities such as excellent scaling and low energy consumption, on the other hand, have been heavily investigated and explored for realizing in-memory processing architecture. In this paper, we summarize the recent research progress in eNVM-based in-memory processing from various aspects, including the adopted memory technologies, locations of the in-memory processing in the system, supported arithmetics, as well as applied applications.
Spintronics based Stochastic Computing for Efficient Bayesian Inference System
Nov 03, 2017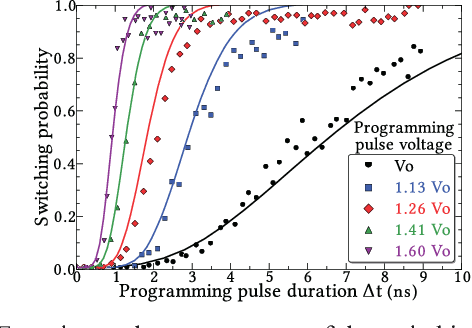
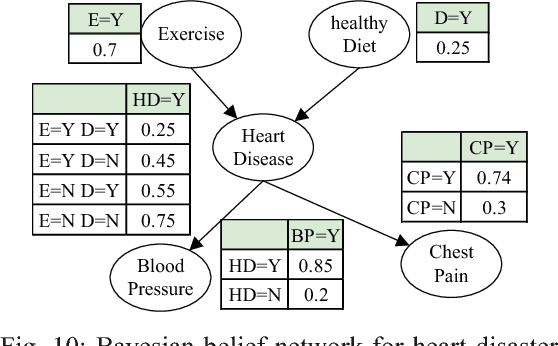
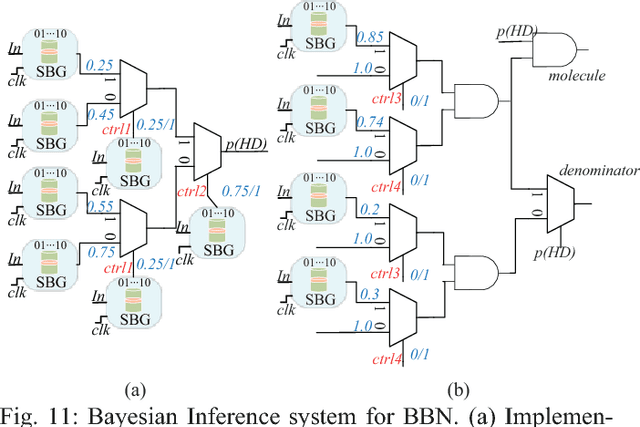
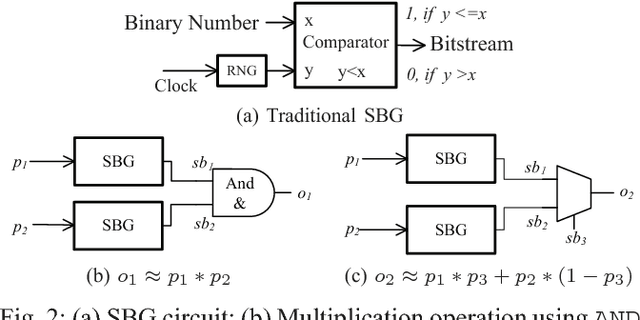
Bayesian inference is an effective approach for solving statistical learning problems especially with uncertainty and incompleteness. However, inference efficiencies are physically limited by the bottlenecks of conventional computing platforms. In this paper, an emerging Bayesian inference system is proposed by exploiting spintronics based stochastic computing. A stochastic bitstream generator is realized as the kernel components by leveraging the inherent randomness of spintronics devices. The proposed system is evaluated by typical applications of data fusion and Bayesian belief networks. Simulation results indicate that the proposed approach could achieve significant improvement on inference efficiencies in terms of power consumption and inference speed.