 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandheld Video Document Scanning: A Robust On-Device Model for Multi-Page Document Scanning
Nov 01, 2024Document capture applications on smartphones have emerged as popular tools for digitizing documents. For many individuals, capturing documents with their smartphones is more convenient than using dedicated photocopiers or scanners, even if the quality of digitization is lower. However, using a smartphone for digitization can become excessively time-consuming and tedious when a user needs to digitize a document with multiple pages. In this work, we propose a novel approach to automatically scan multi-page documents from a video stream as the user turns through the pages of the document. Unlike previous methods that required constrained settings such as mounting the phone on a tripod, our technique is designed to allow the user to hold the phone in their hand. Our technique is trained to be robust to the motion and instability inherent in handheld scanning. Our primary contributions in this work include: (1) an efficient, on-device deep learning model that is accurate and robust for handheld scanning, (2) a novel data collection and annotation technique for video document scanning, and (3) state-of-the-art results on the PUCIT page turn dataset.
ARTIST: Improving the Generation of Text-rich Images by Disentanglement
Jun 17, 2024



Diffusion models have demonstrated exceptional capabilities in generating a broad spectrum of visual content, yet their proficiency in rendering text is still limited: they often generate inaccurate characters or words that fail to blend well with the underlying image. To address these shortcomings, we introduce a new framework named ARTIST. This framework incorporates a dedicated textual diffusion model to specifically focus on the learning of text structures. Initially, we pretrain this textual model to capture the intricacies of text representation. Subsequently, we finetune a visual diffusion model, enabling it to assimilate textual structure information from the pretrained textual model. This disentangled architecture design and the training strategy significantly enhance the text rendering ability of the diffusion models for text-rich image generation. Additionally, we leverage the capabilities of pretrained large language models to better interpret user intentions, contributing to improved generation quality. Empirical results on the MARIO-Eval benchmark underscore the effectiveness of the proposed method, showing an improvement of up to 15\% in various metrics.
DocSynthv2: A Practical Autoregressive Modeling for Document Generation
Jun 12, 2024



While the generation of document layouts has been extensively explored, comprehensive document generation encompassing both layout and content presents a more complex challenge. This paper delves into this advanced domain, proposing a novel approach called DocSynthv2 through the development of a simple yet effective autoregressive structured model. Our model, distinct in its integration of both layout and textual cues, marks a step beyond existing layout-generation approaches. By focusing on the relationship between the structural elements and the textual content within documents, we aim to generate cohesive and contextually relevant documents without any reliance on visual components. Through experimental studies on our curated benchmark for the new task, we demonstrate the ability of our model combining layout and textual information in enhancing the generation quality and relevance of documents, opening new pathways for research in document creation and automated design. Our findings emphasize the effectiveness of autoregressive models in handling complex document generation tasks.
Certified Neural Network Watermarks with Randomized Smoothing
Jul 16, 2022

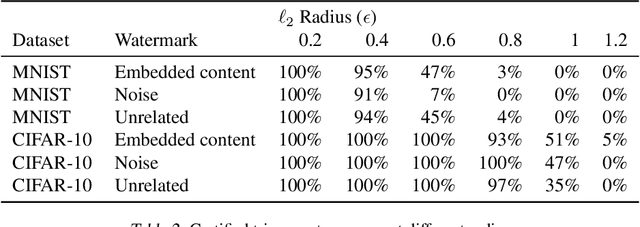

Watermarking is a commonly used strategy to protect creators' rights to digital images, videos and audio. Recently, watermarking methods have been extended to deep learning models -- in principle, the watermark should be preserved when an adversary tries to copy the model. However, in practice, watermarks can often be removed by an intelligent adversary. Several papers have proposed watermarking methods that claim to be empirically resistant to different types of removal attacks, but these new techniques often fail in the face of new or better-tuned adversaries. In this paper, we propose a certifiable watermarking method. Using the randomized smoothing technique proposed in Chiang et al., we show that our watermark is guaranteed to be unremovable unless the model parameters are changed by more than a certain l2 threshold. In addition to being certifiable, our watermark is also empirically more robust compared to previous watermarking methods. Our experiments can be reproduced with code at https://github.com/arpitbansal297/Certified_Watermarks
* ICML 2022
End-to-end Document Recognition and Understanding with Dessurt
Mar 30, 2022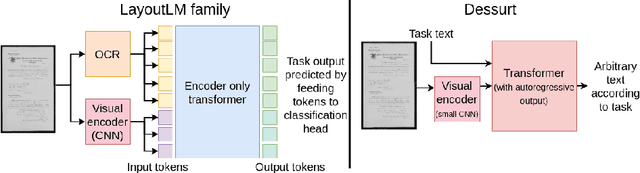


We introduce Dessurt, a relatively simple document understanding transformer capable of being fine-tuned on a greater variety of document tasks than prior methods. It receives a document image and task string as input and generates arbitrary text autoregressively as output. Because Dessurt is an end-to-end architecture that performs text recognition in addition to the document understanding, it does not require an external recognition model as prior methods do, making it easier to fine-tune to new visual domains. We show that this model is effective at 9 different dataset-task combinations.
RPCL: A Framework for Improving Cross-Domain Detection with Auxiliary Tasks
Apr 18, 2021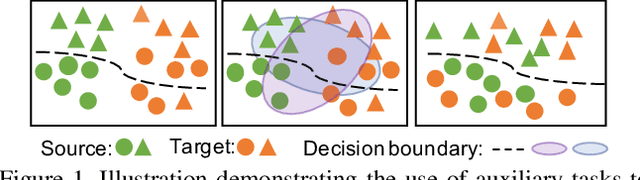
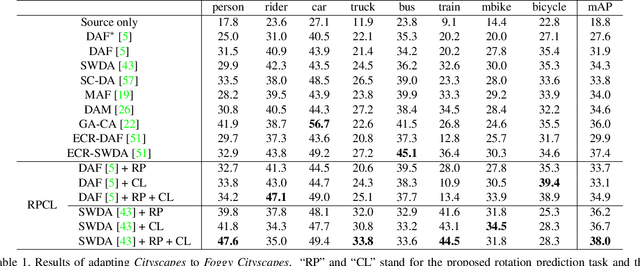
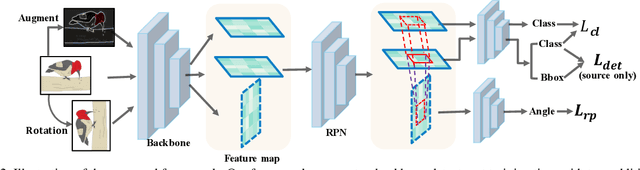
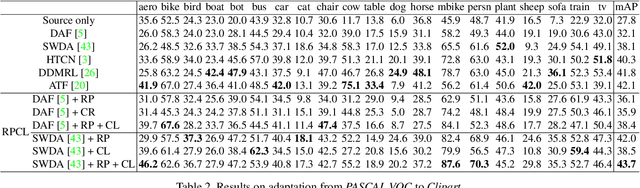
Cross-Domain Detection (XDD) aims to train an object detector using labeled image from a source domain but have good performance in the target domain with only unlabeled images. Existing approaches achieve this either by aligning the feature maps or the region proposals from the two domains, or by transferring the style of source images to that of target image. Contrasted with prior work, this paper provides a complementary solution to align domains by learning the same auxiliary tasks in both domains simultaneously. These auxiliary tasks push image from both domains towards shared spaces, which bridges the domain gap. Specifically, this paper proposes Rotation Prediction and Consistency Learning (PRCL), a framework complementing existing XDD methods for domain alignment by leveraging the two auxiliary tasks. The first one encourages the model to extract region proposals from foreground regions by rotating an image and predicting the rotation angle from the extracted region proposals. The second task encourages the model to be robust to changes in the image space by optimizing the model to make consistent class predictions for region proposals regardless of image perturbations. Experiments show the detection performance can be consistently and significantly enhanced by applying the two proposed tasks to existing XDD methods.
Text and Style Conditioned GAN for Generation of Offline Handwriting Lines
Sep 01, 2020
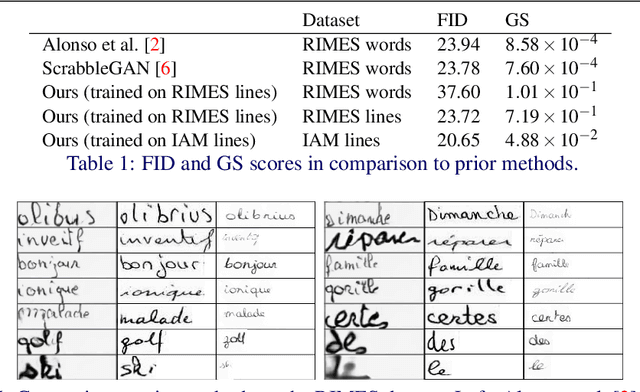
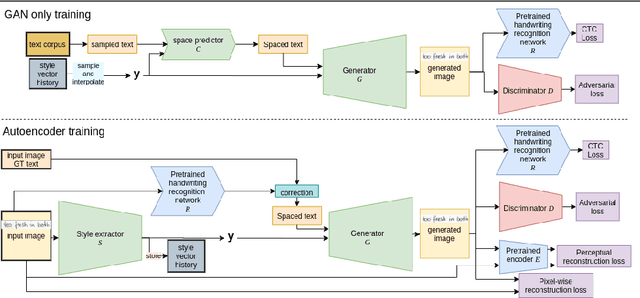
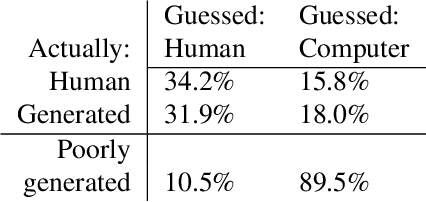
This paper presents a GAN for generating images of handwritten lines conditioned on arbitrary text and latent style vectors. Unlike prior work, which produce stroke points or single-word images, this model generates entire lines of offline handwriting. The model produces variable-sized images by using style vectors to determine character widths. A generator network is trained with GAN and autoencoder techniques to learn style, and uses a pre-trained handwriting recognition network to induce legibility. A study using human evaluators demonstrates that the model produces images that appear to be written by a human. After training, the encoder network can extract a style vector from an image, allowing images in a similar style to be generated, but with arbitrary text.
Cross-Domain Document Object Detection: Benchmark Suite and Method
Mar 30, 2020
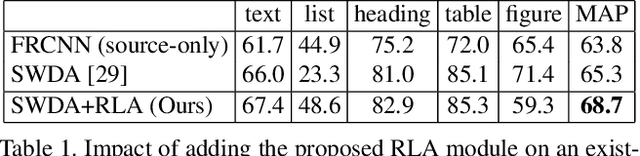
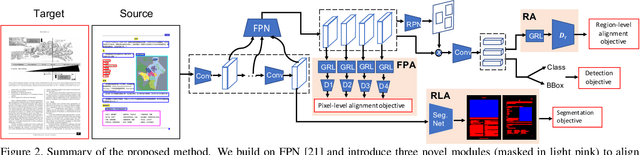
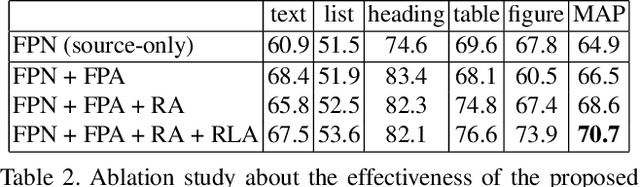
Decomposing images of document pages into high-level semantic regions (e.g., figures, tables, paragraphs), document object detection (DOD) is fundamental for downstream tasks like intelligent document editing and understanding. DOD remains a challenging problem as document objects vary significantly in layout, size, aspect ratio, texture, etc. An additional challenge arises in practice because large labeled training datasets are only available for domains that differ from the target domain. We investigate cross-domain DOD, where the goal is to learn a detector for the target domain using labeled data from the source domain and only unlabeled data from the target domain. Documents from the two domains may vary significantly in layout, language, and genre. We establish a benchmark suite consisting of different types of PDF document datasets that can be utilized for cross-domain DOD model training and evaluation. For each dataset, we provide the page images, bounding box annotations, PDF files, and the rendering layers extracted from the PDF files. Moreover, we propose a novel cross-domain DOD model which builds upon the standard detection model and addresses domain shifts by incorporating three novel alignment modules: Feature Pyramid Alignment (FPA) module, Region Alignment (RA) module and Rendering Layer alignment (RLA) module. Extensive experiments on the benchmark suite substantiate the efficacy of the three proposed modules and the proposed method significantly outperforms the baseline methods. The project page is at \url{https://github.com/kailigo/cddod}.
Language Model Supervision for Handwriting Recognition Model Adaptation
Aug 04, 2018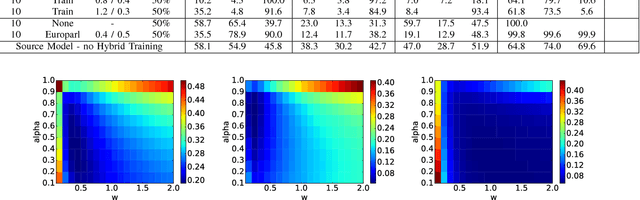
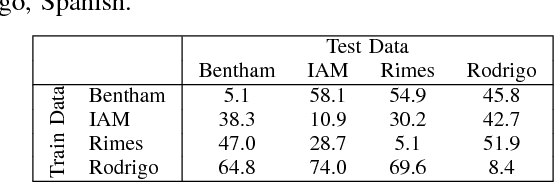
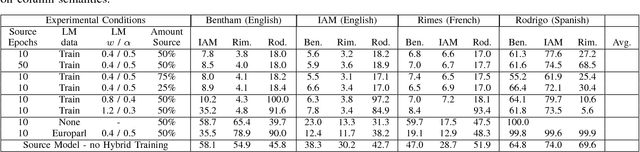
Training state-of-the-art offline handwriting recognition (HWR) models requires large labeled datasets, but unfortunately such datasets are not available in all languages and domains due to the high cost of manual labeling.We address this problem by showing how high resource languages can be leveraged to help train models for low resource languages.We propose a transfer learning methodology where we adapt HWR models trained on a source language to a target language that uses the same writing script.This methodology only requires labeled data in the source language, unlabeled data in the target language, and a language model of the target language. The language model is used in a bootstrapping fashion to refine predictions in the target language for use as ground truth in training the model.Using this approach we demonstrate improved transferability among French, English, and Spanish languages using both historical and modern handwriting datasets. In the best case, transferring with the proposed methodology results in character error rates nearly as good as full supervised training.
PageNet: Page Boundary Extraction in Historical Handwritten Documents
Sep 05, 2017
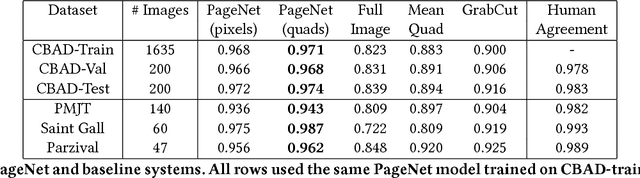

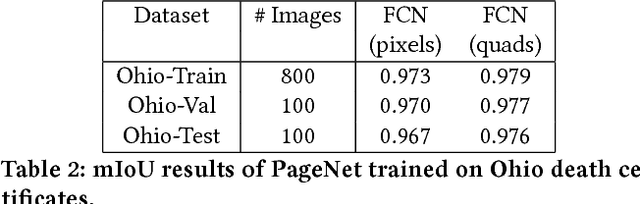
When digitizing a document into an image, it is common to include a surrounding border region to visually indicate that the entire document is present in the image. However, this border should be removed prior to automated processing. In this work, we present a deep learning based system, PageNet, which identifies the main page region in an image in order to segment content from both textual and non-textual border noise. In PageNet, a Fully Convolutional Network obtains a pixel-wise segmentation which is post-processed into the output quadrilateral region. We evaluate PageNet on 4 collections of historical handwritten documents and obtain over 94% mean intersection over union on all datasets and approach human performance on 2 of these collections. Additionally, we show that PageNet can segment documents that are overlayed on top of other documents.