 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
Jul 14, 2022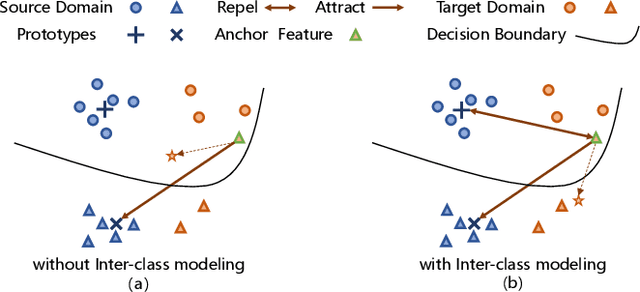
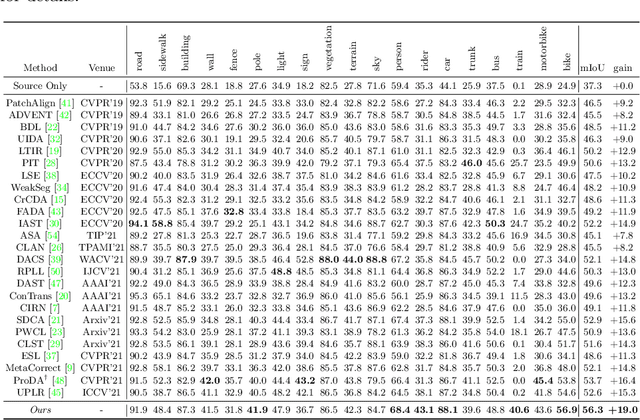
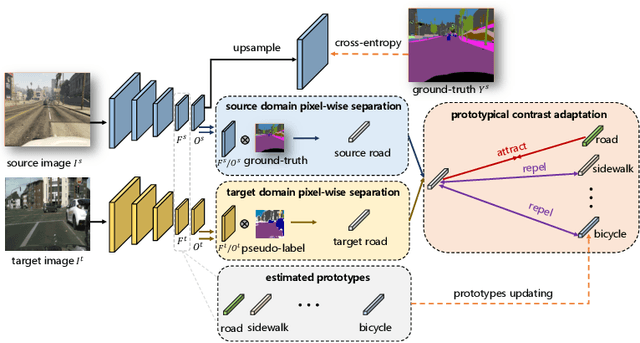
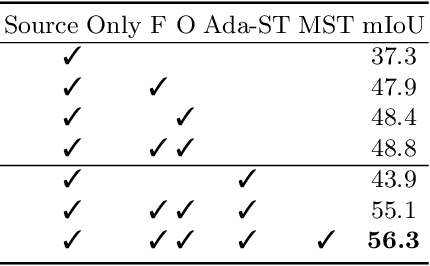
Unsupervised Domain Adaptation (UDA) aims to adapt the model trained on the labeled source domain to an unlabeled target domain. In this paper, we present Prototypical Contrast Adaptation (ProCA), a simple and efficient contrastive learning method for unsupervised domain adaptive semantic segmentation. Previous domain adaptation methods merely consider the alignment of the intra-class representational distributions across various domains, while the inter-class structural relationship is insufficiently explored, resulting in the aligned representations on the target domain might not be as easily discriminated as done on the source domain anymore. Instead, ProCA incorporates inter-class information into class-wise prototypes, and adopts the class-centered distribution alignment for adaptation. By considering the same class prototypes as positives and other class prototypes as negatives to achieve class-centered distribution alignment, ProCA achieves state-of-the-art performance on classical domain adaptation tasks, {\em i.e., GTA5 $\to$ Cityscapes \text{and} SYNTHIA $\to$ Cityscapes}. Code is available at \href{https://github.com/jiangzhengkai/ProCA}{ProCA}
IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation
May 29, 2022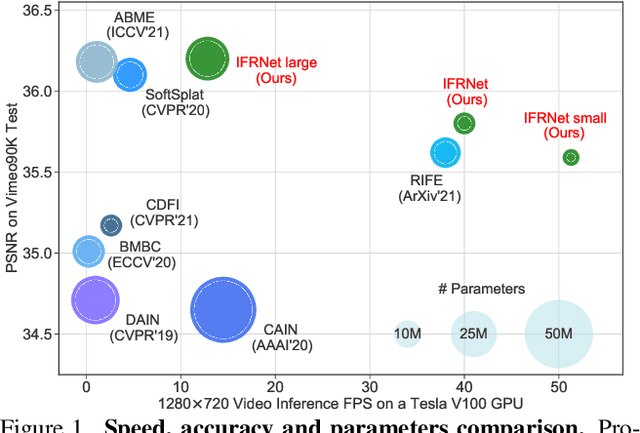
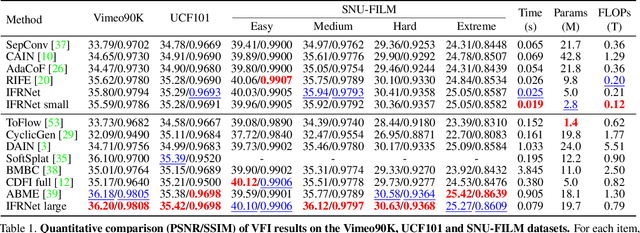

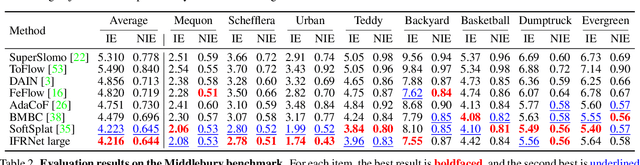
Prevailing video frame interpolation algorithms, that generate the intermediate frames from consecutive inputs, typically rely on complex model architectures with heavy parameters or large delay, hindering them from diverse real-time applications. In this work, we devise an efficient encoder-decoder based network, termed IFRNet, for fast intermediate frame synthesizing. It first extracts pyramid features from given inputs, and then refines the bilateral intermediate flow fields together with a powerful intermediate feature until generating the desired output. The gradually refined intermediate feature can not only facilitate intermediate flow estimation, but also compensate for contextual details, making IFRNet do not need additional synthesis or refinement module. To fully release its potential, we further propose a novel task-oriented optical flow distillation loss to focus on learning the useful teacher knowledge towards frame synthesizing. Meanwhile, a new geometry consistency regularization term is imposed on the gradually refined intermediate features to keep better structure layout. Experiments on various benchmarks demonstrate the excellent performance and fast inference speed of proposed approaches. Code is available at https://github.com/ltkong218/IFRNet.
FRIH: Fine-grained Region-aware Image Harmonization
May 13, 2022

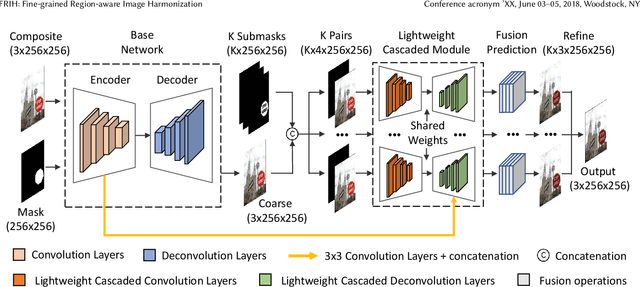
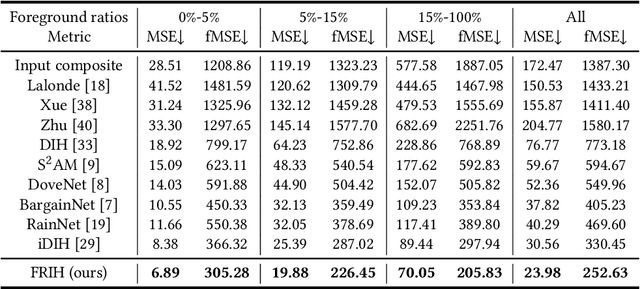
Image harmonization aims to generate a more realistic appearance of foreground and background for a composite image. Existing methods perform the same harmonization process for the whole foreground. However, the implanted foreground always contains different appearance patterns. All the existing solutions ignore the difference of each color block and losing some specific details. Therefore, we propose a novel global-local two stages framework for Fine-grained Region-aware Image Harmonization (FRIH), which is trained end-to-end. In the first stage, the whole input foreground mask is used to make a global coarse-grained harmonization. In the second stage, we adaptively cluster the input foreground mask into several submasks by the corresponding pixel RGB values in the composite image. Each submask and the coarsely adjusted image are concatenated respectively and fed into a lightweight cascaded module, adjusting the global harmonization performance according to the region-aware local feature. Moreover, we further designed a fusion prediction module by fusing features from all the cascaded decoder layers together to generate the final result, which could utilize the different degrees of harmonization results comprehensively. Without bells and whistles, our FRIH algorithm achieves the best performance on iHarmony4 dataset (PSNR is 38.19 dB) with a lightweight model. The parameters for our model are only 11.98 M, far below the existing methods.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
High-resolution Iterative Feedback Network for Camouflaged Object Detection
Mar 22, 2022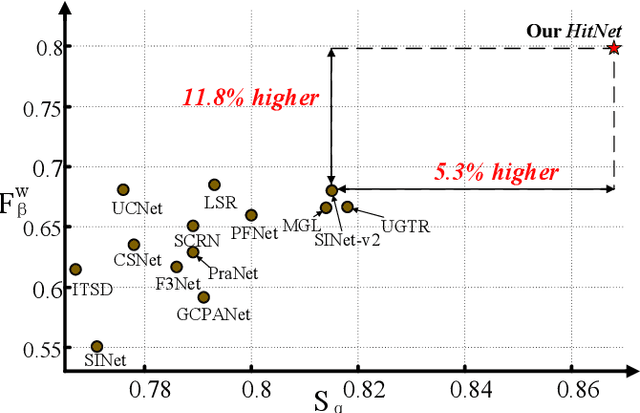



Spotting camouflaged objects that are visually assimilated into the background is tricky for both object detection algorithms and humans who are usually confused or cheated by the perfectly intrinsic similarities between the foreground objects and the background surroundings. To tackle this challenge, we aim to extract the high-resolution texture details to avoid the detail degradation that causes blurred vision in edges and boundaries. We introduce a novel HitNet to refine the low-resolution representations by high-resolution features in an iterative feedback manner, essentially a global loop-based connection among the multi-scale resolutions. In addition, an iterative feedback loss is proposed to impose more constraints on each feedback connection. Extensive experiments on four challenging datasets demonstrate that our \ourmodel~breaks the performance bottleneck and achieves significant improvements compared with 29 state-of-the-art methods. To address the data scarcity in camouflaged scenarios, we provide an application example by employing cross-domain learning to extract the features that can reflect the camouflaged object properties and embed the features into salient objects, thereby generating more camouflaged training samples from the diverse salient object datasets The code will be available at https://github.com/HUuxiaobin/HitNet.
CtlGAN: Few-shot Artistic Portraits Generation with Contrastive Transfer Learning
Mar 16, 2022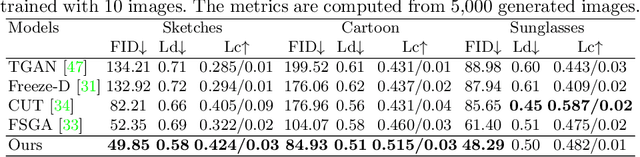

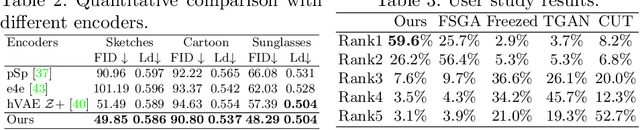
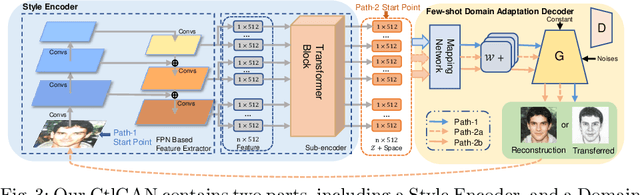
Generating artistic portraits is a challenging problem in computer vision. Existing portrait stylization models that generate good quality results are based on Image-to-Image Translation and require abundant data from both source and target domains. However, without enough data, these methods would result in overfitting. In this work, we propose CtlGAN, a new few-shot artistic portraits generation model with a novel contrastive transfer learning strategy. We adapt a pretrained StyleGAN in the source domain to a target artistic domain with no more than 10 artistic faces. To reduce overfitting to the few training examples, we introduce a novel Cross-Domain Triplet loss which explicitly encourages the target instances generated from different latent codes to be distinguishable. We propose a new encoder which embeds real faces into Z+ space and proposes a dual-path training strategy to better cope with the adapted decoder and eliminate the artifacts. Extensive qualitative, quantitative comparisons and a user study show our method significantly outperforms state-of-the-arts under 10-shot and 1-shot settings and generates high quality artistic portraits. The code will be made publicly available.
STC: Spatio-Temporal Contrastive Learning for Video Instance Segmentation
Feb 08, 2022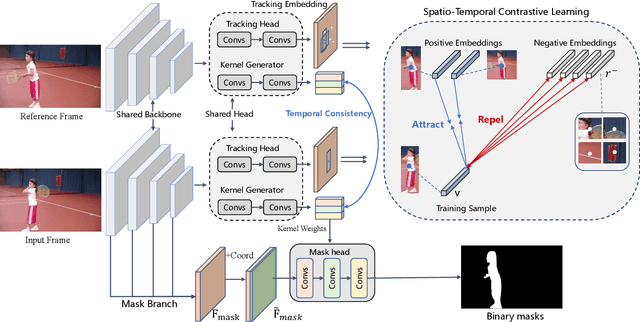
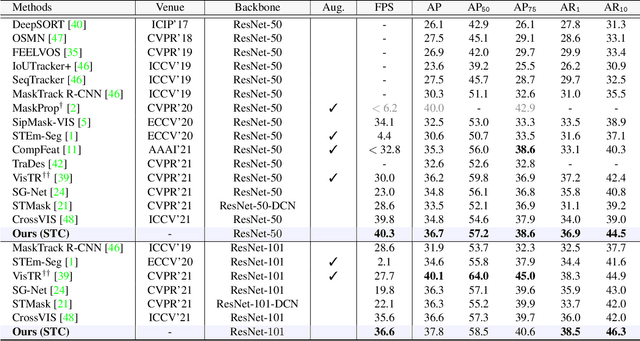
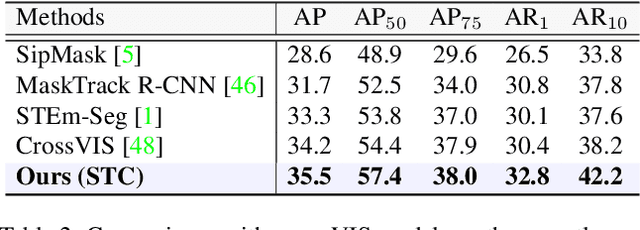

Video Instance Segmentation (VIS) is a task that simultaneously requires classification, segmentation, and instance association in a video. Recent VIS approaches rely on sophisticated pipelines to achieve this goal, including RoI-related operations or 3D convolutions. In contrast, we present a simple and efficient single-stage VIS framework based on the instance segmentation method CondInst by adding an extra tracking head. To improve instance association accuracy, a novel bi-directional spatio-temporal contrastive learning strategy for tracking embedding across frames is proposed. Moreover, an instance-wise temporal consistency scheme is utilized to produce temporally coherent results. Experiments conducted on the YouTube-VIS-2019, YouTube-VIS-2021, and OVIS-2021 datasets validate the effectiveness and efficiency of the proposed method. We hope the proposed framework can serve as a simple and strong alternative for many other instance-level video association tasks. Code will be made available.
ASFD: Automatic and Scalable Face Detector
Jan 26, 2022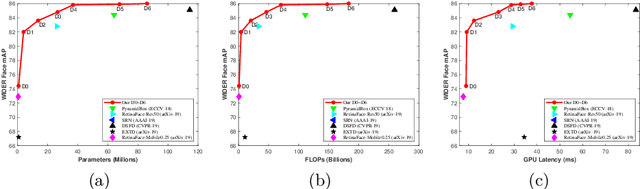

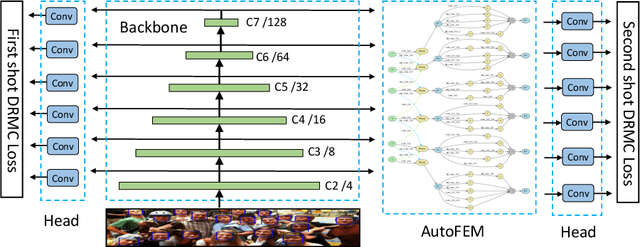
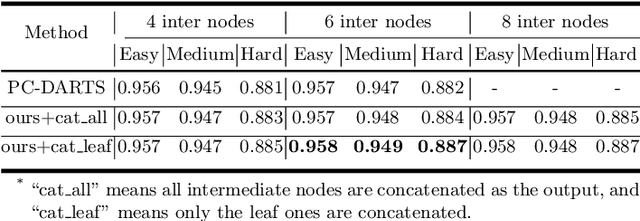
Along with current multi-scale based detectors, Feature Aggregation and Enhancement (FAE) modules have shown superior performance gains for cutting-edge object detection. However, these hand-crafted FAE modules show inconsistent improvements on face detection, which is mainly due to the significant distribution difference between its training and applying corpus, COCO vs. WIDER Face. To tackle this problem, we essentially analyse the effect of data distribution, and consequently propose to search an effective FAE architecture, termed AutoFAE by a differentiable architecture search, which outperforms all existing FAE modules in face detection with a considerable margin. Upon the found AutoFAE and existing backbones, a supernet is further built and trained, which automatically obtains a family of detectors under the different complexity constraints. Extensive experiments conducted on popular benchmarks, WIDER Face and FDDB, demonstrate the state-of-the-art performance-efficiency trade-off for the proposed automatic and scalable face detector (ASFD) family. In particular, our strong ASFD-D6 outperforms the best competitor with AP 96.7/96.2/92.1 on WIDER Face test, and the lightweight ASFD-D0 costs about 3.1 ms, more than 320 FPS, on the V100 GPU with VGA-resolution images.
CFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
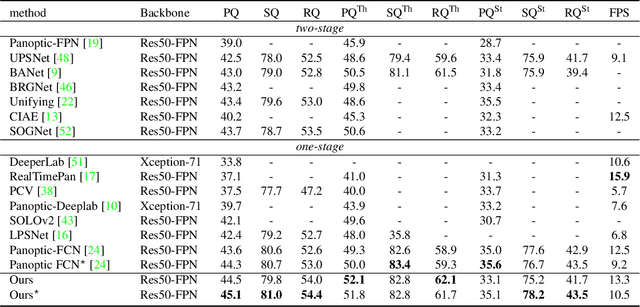
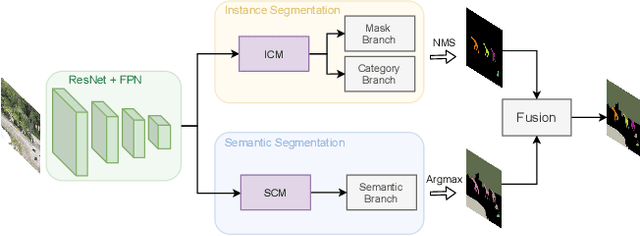
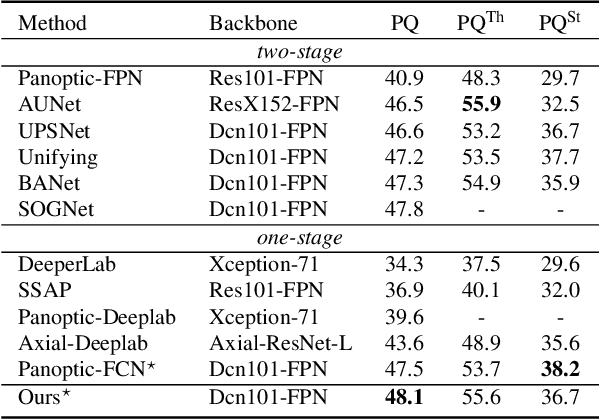
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.
SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
Jan 12, 2022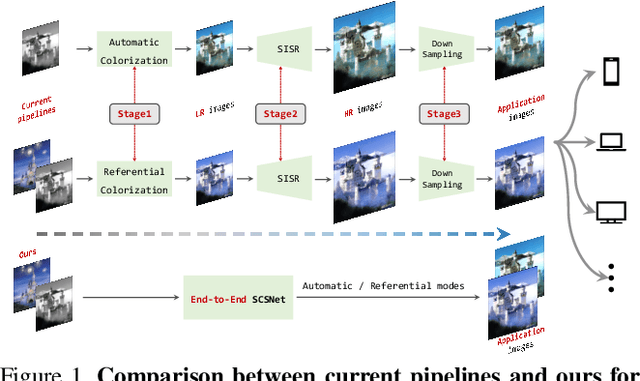
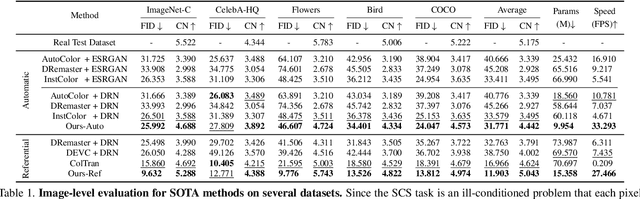

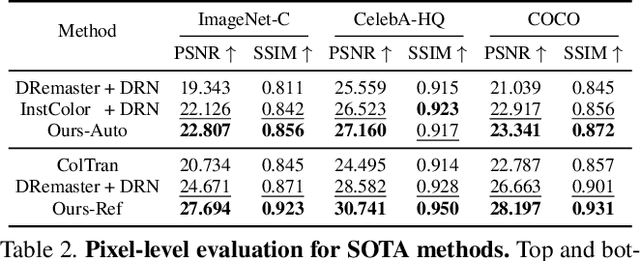
In the practical application of restoring low-resolution gray-scale images, we generally need to run three separate processes of image colorization, super-resolution, and dows-sampling operation for the target device. However, this pipeline is redundant and inefficient for the independent processes, and some inner features could have been shared. Therefore, we present an efficient paradigm to perform {S}imultaneously Image {C}olorization and {S}uper-resolution (SCS) and propose an end-to-end SCSNet to achieve this goal. The proposed method consists of two parts: colorization branch for learning color information that employs the proposed plug-and-play \emph{Pyramid Valve Cross Attention} (PVCAttn) module to aggregate feature maps between source and reference images; and super-resolution branch for integrating color and texture information to predict target images, which uses the designed \emph{Continuous Pixel Mapping} (CPM) module to predict high-resolution images at continuous magnification. Furthermore, our SCSNet supports both automatic and referential modes that is more flexible for practical application. Abundant experiments demonstrate the superiority of our method for generating authentic images over state-of-the-art methods, e.g., averagely decreasing FID by 1.8$\downarrow$ and 5.1 $\downarrow$ compared with current best scores for automatic and referential modes, respectively, while owning fewer parameters (more than $\times$2$\downarrow$) and faster running speed (more than $\times$3$\uparrow$).