 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
PhysSFI-Net: Physics-informed Geometric Learning of Skeletal and Facial Interactions for Orthognathic Surgical Outcome Prediction
Jan 06, 2026Orthognathic surgery repositions jaw bones to restore occlusion and enhance facial aesthetics. Accurate simulation of postoperative facial morphology is essential for preoperative planning. However, traditional biomechanical models are computationally expensive, while geometric deep learning approaches often lack interpretability. In this study, we develop and validate a physics-informed geometric deep learning framework named PhysSFI-Net for precise prediction of soft tissue deformation following orthognathic surgery. PhysSFI-Net consists of three components: a hierarchical graph module with craniofacial and surgical plan encoders combined with attention mechanisms to extract skeletal-facial interaction features; a Long Short-Term Memory (LSTM)-based sequential predictor for incremental soft tissue deformation; and a biomechanics-inspired module for high-resolution facial surface reconstruction. Model performance was assessed using point cloud shape error (Hausdorff distance), surface deviation error, and landmark localization error (Euclidean distances of craniomaxillofacial landmarks) between predicted facial shapes and corresponding ground truths. A total of 135 patients who underwent combined orthodontic and orthognathic treatment were included for model training and validation. Quantitative analysis demonstrated that PhysSFI-Net achieved a point cloud shape error of 1.070 +/- 0.088 mm, a surface deviation error of 1.296 +/- 0.349 mm, and a landmark localization error of 2.445 +/- 1.326 mm. Comparative experiments indicated that PhysSFI-Net outperformed the state-of-the-art method ACMT-Net in prediction accuracy. In conclusion, PhysSFI-Net enables interpretable, high-resolution prediction of postoperative facial morphology with superior accuracy, showing strong potential for clinical application in orthognathic surgical planning and simulation.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Nov 12, 2025Humanoid robots exhibit significant potential in executing diverse human-level skills. However, current research predominantly relies on data-driven approaches that necessitate extensive training datasets to achieve robust multimodal decision-making capabilities and generalizable visuomotor control. These methods raise concerns due to the neglect of geometric reasoning in unseen scenarios and the inefficient modeling of robot-target relationships within the training data, resulting in significant waste of training resources. To address these limitations, we present the Recurrent Geometric-prior Multimodal Policy (RGMP), an end-to-end framework that unifies geometric-semantic skill reasoning with data-efficient visuomotor control. For perception capabilities, we propose the Geometric-prior Skill Selector, which infuses geometric inductive biases into a vision language model, producing adaptive skill sequences for unseen scenes with minimal spatial common sense tuning. To achieve data-efficient robotic motion synthesis, we introduce the Adaptive Recursive Gaussian Network, which parameterizes robot-object interactions as a compact hierarchy of Gaussian processes that recursively encode multi-scale spatial relationships, yielding dexterous, data-efficient motion synthesis even from sparse demonstrations. Evaluated on both our humanoid robot and desktop dual-arm robot, the RGMP framework achieves 87% task success in generalization tests and exhibits 5x greater data efficiency than the state-of-the-art model. This performance underscores its superior cross-domain generalization, enabled by geometric-semantic reasoning and recursive-Gaussion adaptation.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025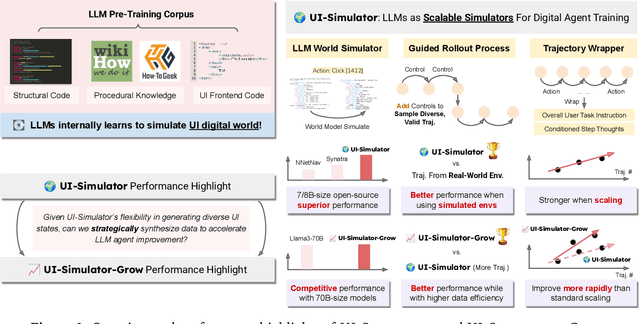
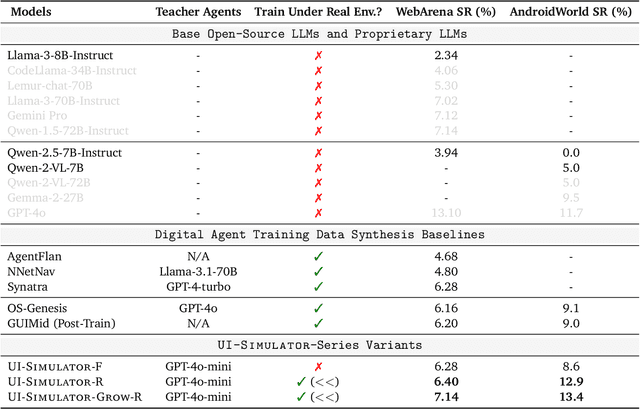

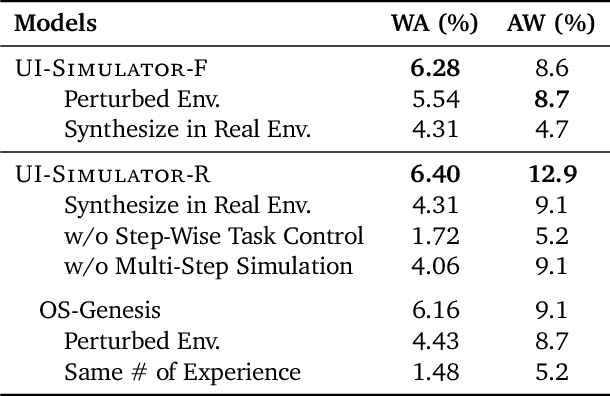
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025



Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
Rate doubly robust estimation for weighted average treatment effects
Sep 18, 2025The weighted average treatment effect (WATE) defines a versatile class of causal estimands for populations characterized by propensity score weights, including the average treatment effect (ATE), treatment effect on the treated (ATT), on controls (ATC), and for the overlap population (ATO). WATE has broad applicability in social and medical research, as many datasets from these fields align with its framework. However, the literature lacks a systematic investigation into the robustness and efficiency conditions for WATE estimation. Although doubly robust (DR) estimators are well-studied for ATE, their applicability to other WATEs remains uncertain. This paper investigates whether widely used WATEs admit DR or rate doubly robust (RDR) estimators and assesses the role of nuisance function accuracy, particularly with machine learning. Using semiparametric efficient influence function (EIF) theory and double/debiased machine learning (DML), we propose three RDR estimators under specific rate and regularity conditions and evaluate their performance via Monte Carlo simulations. Applications to NHANES data on smoking and blood lead levels, and SIPP data on 401(k) eligibility, demonstrate the methods' practical relevance in medical and social sciences.
MemEvo: Memory-Evolving Incremental Multi-view Clustering
Sep 18, 2025Incremental multi-view clustering aims to achieve stable clustering results while addressing the stability-plasticity dilemma (SPD) in incremental views. At the core of SPD is the challenge that the model must have enough plasticity to quickly adapt to new data, while maintaining sufficient stability to consolidate long-term knowledge and prevent catastrophic forgetting. Inspired by the hippocampal-prefrontal cortex collaborative memory mechanism in neuroscience, we propose a Memory-Evolving Incremental Multi-view Clustering method (MemEvo) to achieve this balance. First, we propose a hippocampus-inspired view alignment module that captures the gain information of new views by aligning structures in continuous representations. Second, we introduce a cognitive forgetting mechanism that simulates the decay patterns of human memory to modulate the weights of historical knowledge. Additionally, we design a prefrontal cortex-inspired knowledge consolidation memory module that leverages temporal tensor stability to gradually consolidate historical knowledge. By integrating these modules, MemEvo achieves strong knowledge retention capabilities in scenarios with a growing number of views. Extensive experiments demonstrate that MemEvo exhibits remarkable advantages over existing state-of-the-art methods.
Enhancing Retrieval Augmentation via Adversarial Collaboration
Sep 18, 2025Retrieval-augmented Generation (RAG) is a prevalent approach for domain-specific LLMs, yet it is often plagued by "Retrieval Hallucinations"--a phenomenon where fine-tuned models fail to recognize and act upon poor-quality retrieved documents, thus undermining performance. To address this, we propose the Adversarial Collaboration RAG (AC-RAG) framework. AC-RAG employs two heterogeneous agents: a generalist Detector that identifies knowledge gaps, and a domain-specialized Resolver that provides precise solutions. Guided by a moderator, these agents engage in an adversarial collaboration, where the Detector's persistent questioning challenges the Resolver's expertise. This dynamic process allows for iterative problem dissection and refined knowledge retrieval. Extensive experiments show that AC-RAG significantly improves retrieval accuracy and outperforms state-of-the-art RAG methods across various vertical domains.
Neural Video Compression with In-Loop Contextual Filtering and Out-of-Loop Reconstruction Enhancement
Sep 04, 2025This paper explores the application of enhancement filtering techniques in neural video compression. Specifically, we categorize these techniques into in-loop contextual filtering and out-of-loop reconstruction enhancement based on whether the enhanced representation affects the subsequent coding loop. In-loop contextual filtering refines the temporal context by mitigating error propagation during frame-by-frame encoding. However, its influence on both the current and subsequent frames poses challenges in adaptively applying filtering throughout the sequence. To address this, we introduce an adaptive coding decision strategy that dynamically determines filtering application during encoding. Additionally, out-of-loop reconstruction enhancement is employed to refine the quality of reconstructed frames, providing a simple yet effective improvement in coding efficiency. To the best of our knowledge, this work presents the first systematic study of enhancement filtering in the context of conditional-based neural video compression. Extensive experiments demonstrate a 7.71% reduction in bit rate compared to state-of-the-art neural video codecs, validating the effectiveness of the proposed approach.
LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing
Jul 30, 2025



Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch for fashion image generation (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel step-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model's multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple text-sketch pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.