 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemEvo: Memory-Evolving Incremental Multi-view Clustering
Sep 18, 2025Incremental multi-view clustering aims to achieve stable clustering results while addressing the stability-plasticity dilemma (SPD) in incremental views. At the core of SPD is the challenge that the model must have enough plasticity to quickly adapt to new data, while maintaining sufficient stability to consolidate long-term knowledge and prevent catastrophic forgetting. Inspired by the hippocampal-prefrontal cortex collaborative memory mechanism in neuroscience, we propose a Memory-Evolving Incremental Multi-view Clustering method (MemEvo) to achieve this balance. First, we propose a hippocampus-inspired view alignment module that captures the gain information of new views by aligning structures in continuous representations. Second, we introduce a cognitive forgetting mechanism that simulates the decay patterns of human memory to modulate the weights of historical knowledge. Additionally, we design a prefrontal cortex-inspired knowledge consolidation memory module that leverages temporal tensor stability to gradually consolidate historical knowledge. By integrating these modules, MemEvo achieves strong knowledge retention capabilities in scenarios with a growing number of views. Extensive experiments demonstrate that MemEvo exhibits remarkable advantages over existing state-of-the-art methods.
Robust and Efficient Boosting Method using the Conditional Risk
Jun 21, 2018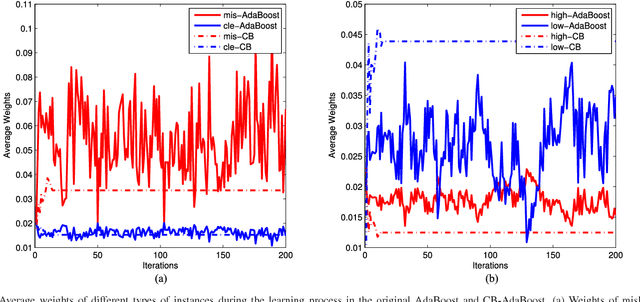
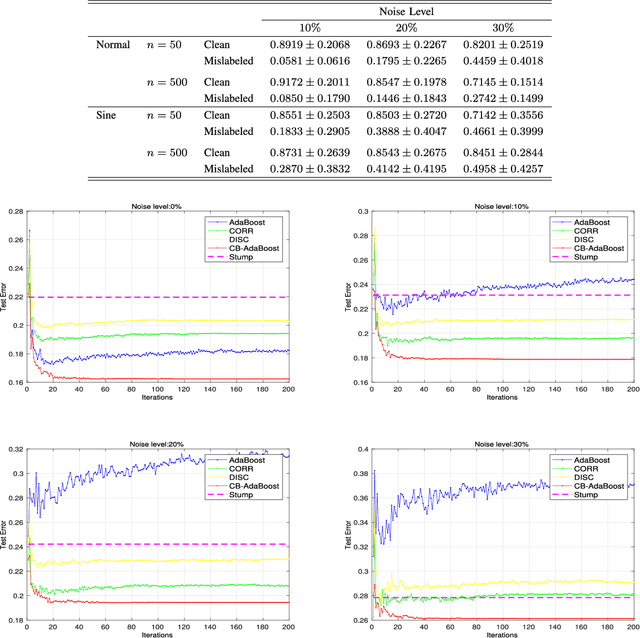
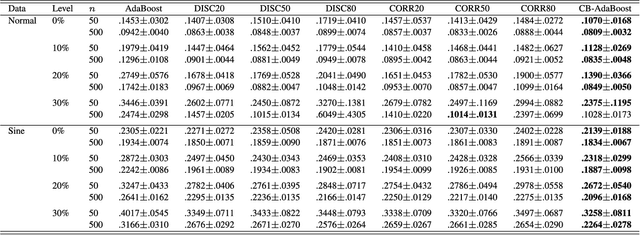
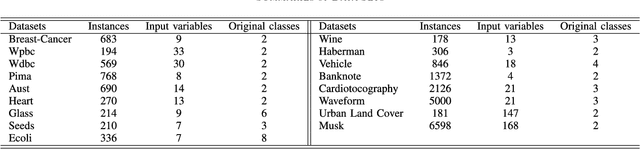
Well-known for its simplicity and effectiveness in classification, AdaBoost, however, suffers from overfitting when class-conditional distributions have significant overlap. Moreover, it is very sensitive to noise that appears in the labels. This article tackles the above limitations simultaneously via optimizing a modified loss function (i.e., the conditional risk). The proposed approach has the following two advantages. (1) It is able to directly take into account label uncertainty with an associated label confidence. (2) It introduces a "trustworthiness" measure on training samples via the Bayesian risk rule, and hence the resulting classifier tends to have finite sample performance that is superior to that of the original AdaBoost when there is a large overlap between class conditional distributions. Theoretical properties of the proposed method are investigated. Extensive experimental results using synthetic data and real-world data sets from UCI machine learning repository are provided. The empirical study shows the high competitiveness of the proposed method in predication accuracy and robustness when compared with the original AdaBoost and several existing robust AdaBoost algorithms.