 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pre-trained AudioLDM for Text to Sound Generation: A Benchmark Study
Mar 11, 2023Deep neural networks have recently achieved breakthroughs in sound generation with text prompts. Despite their promising performance, current text-to-sound generation models face issues on small-scale datasets (e.g., overfitting), significantly limiting their performance. In this paper, we investigate the use of pre-trained AudioLDM, the state-of-the-art model for text-to-audio generation, as the backbone for sound generation. Our study demonstrates the advantages of using pre-trained models for text-to-sound generation, especially in data-scarcity scenarios. In addition, experiments show that different training strategies (e.g., training conditions) may affect the performance of AudioLDM on datasets of different scales. To facilitate future studies, we also evaluate various text-to-sound generation systems on several frequently used datasets under the same evaluation protocols, which allow fair comparisons and benchmarking of these methods on the common ground.
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Feb 16, 2023



Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose AudioLDM, a TTA system that is built on a latent space to learn the continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The pretrained CLAP models enable us to train LDMs with audio embedding while providing text embedding as a condition during sampling. By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency. Trained on AudioCaps with a single GPU, AudioLDM achieves state-of-the-art TTA performance measured by both objective and subjective metrics (e.g., frechet distance). Moreover, AudioLDM is the first TTA system that enables various text-guided audio manipulations (e.g., style transfer) in a zero-shot fashion. Our implementation and demos are available at https://audioldm.github.io.
SwiftAvatar: Efficient Auto-Creation of Parameterized Stylized Character on Arbitrary Avatar Engines
Jan 19, 2023The creation of a parameterized stylized character involves careful selection of numerous parameters, also known as the "avatar vectors" that can be interpreted by the avatar engine. Existing unsupervised avatar vector estimation methods that auto-create avatars for users, however, often fail to work because of the domain gap between realistic faces and stylized avatar images. To this end, we propose SwiftAvatar, a novel avatar auto-creation framework that is evidently superior to previous works. SwiftAvatar introduces dual-domain generators to create pairs of realistic faces and avatar images using shared latent codes. The latent codes can then be bridged with the avatar vectors as pairs, by performing GAN inversion on the avatar images rendered from the engine using avatar vectors. Through this way, we are able to synthesize paired data in high-quality as many as possible, consisting of avatar vectors and their corresponding realistic faces. We also propose semantic augmentation to improve the diversity of synthesis. Finally, a light-weight avatar vector estimator is trained on the synthetic pairs to implement efficient auto-creation. Our experiments demonstrate the effectiveness and efficiency of SwiftAvatar on two different avatar engines. The superiority and advantageous flexibility of SwiftAvatar are also verified in both subjective and objective evaluations.
Learning Implicit Body Representations from Double Diffusion Based Neural Radiance Fields
Jan 17, 2022
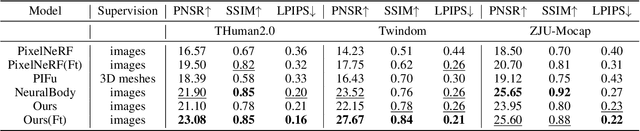
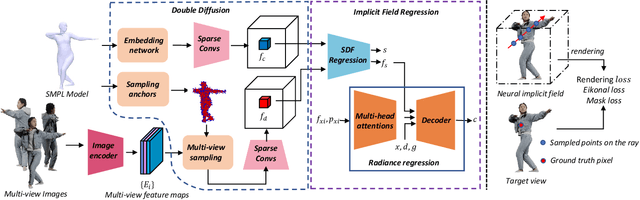
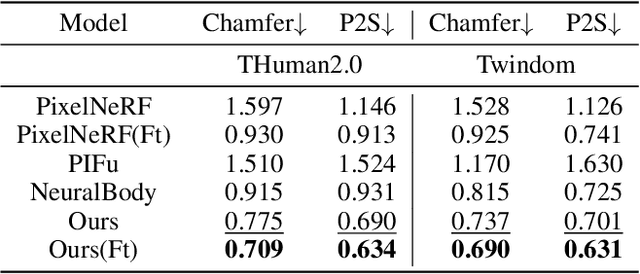
In this paper, we present a novel double diffusion based neural radiance field, dubbed DD-NeRF, to reconstruct human body geometry and render the human body appearance in novel views from a sparse set of images. We first propose a double diffusion mechanism to achieve expressive representations of input images by fully exploiting human body priors and image appearance details at two levels. At the coarse level, we first model the coarse human body poses and shapes via an unclothed 3D deformable vertex model as guidance. At the fine level, we present a multi-view sampling network to capture subtle geometric deformations and image detailed appearances, such as clothing and hair, from multiple input views. Considering the sparsity of the two level features, we diffuse them into feature volumes in the canonical space to construct neural radiance fields. Then, we present a signed distance function (SDF) regression network to construct body surfaces from the diffused features. Thanks to our double diffused representations, our method can even synthesize novel views of unseen subjects. Experiments on various datasets demonstrate that our approach outperforms the state-of-the-art in both geometric reconstruction and novel view synthesis.
Embedding Model Based Fast Meta Learning for Downlink Beamforming Adaptation
Sep 19, 2021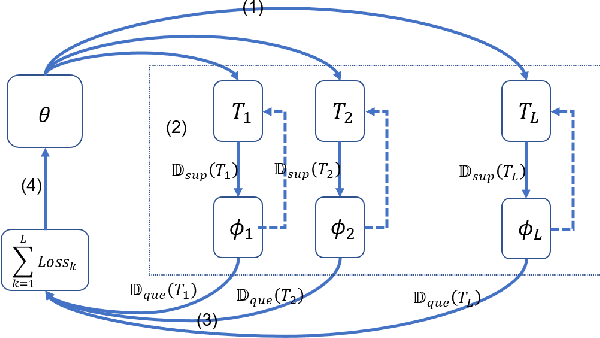
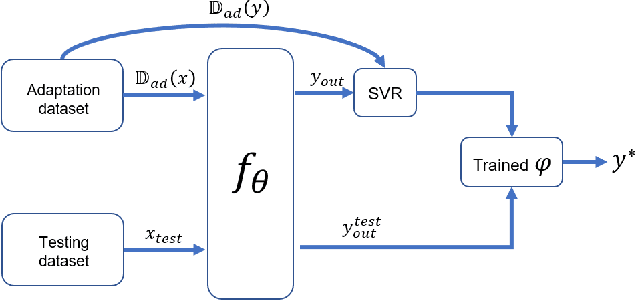
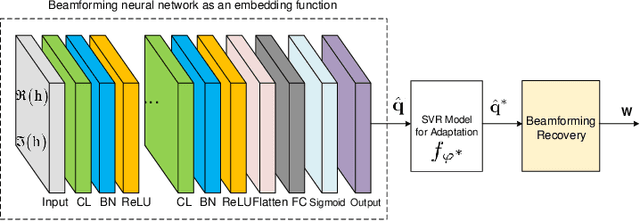
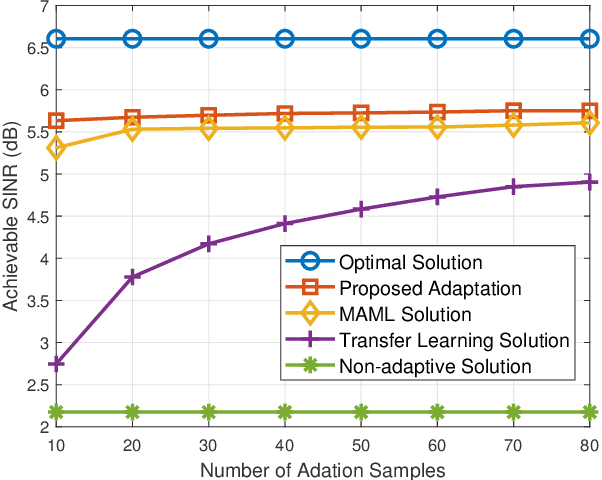
This paper studies the fast adaptive beamforming for the multiuser multiple-input single-output downlink. Existing deep learning-based approaches assume that training and testing channels follow the same distribution which causes task mismatch, when the testing environment changes. Although meta learning can deal with the task mismatch, it relies on labelled data and incurs high complexity in the pre-training and fine tuning stages. We propose a simple yet effective adaptive framework to solve the mismatch issue, which trains an embedding model as a transferable feature extractor, followed by fitting the support vector regression. Compared to the existing meta learning algorithm, our method does not necessarily need labelled data in the pre-training and does not need fine-tuning of the pre-trained model in the adaptation. The effectiveness of the proposed method is verified through two well-known applications, i.e., the signal to interference plus noise ratio balancing problem and the sum rate maximization problem. Furthermore, we extend our proposed method to online scenarios in non-stationary environments. Simulation results demonstrate the advantages of the proposed algorithm in terms of both performance and complexity. The proposed framework can also be applied to general radio resource management problems.
ZiGAN: Fine-grained Chinese Calligraphy Font Generation via a Few-shot Style Transfer Approach
Aug 08, 2021
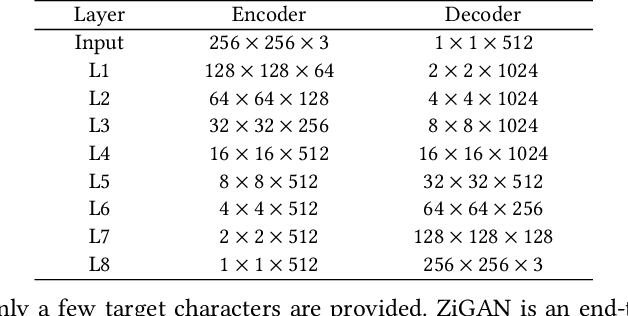
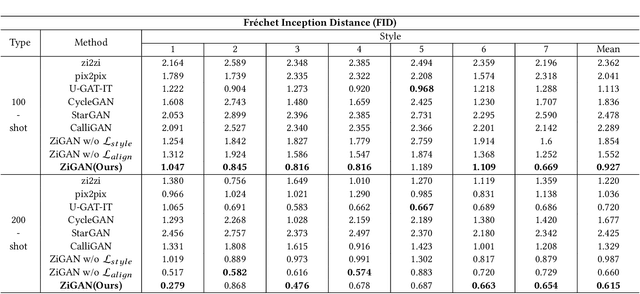

Chinese character style transfer is a very challenging problem because of the complexity of the glyph shapes or underlying structures and large numbers of existed characters, when comparing with English letters. Moreover, the handwriting of calligraphy masters has a more irregular stroke and is difficult to obtain in real-world scenarios. Recently, several GAN-based methods have been proposed for font synthesis, but some of them require numerous reference data and the other part of them have cumbersome preprocessing steps to divide the character into different parts to be learned and transferred separately. In this paper, we propose a simple but powerful end-to-end Chinese calligraphy font generation framework ZiGAN, which does not require any manual operation or redundant preprocessing to generate fine-grained target-style characters with few-shot references. To be specific, a few paired samples from different character styles are leveraged to attain a fine-grained correlation between structures underlying different glyphs. To capture valuable style knowledge in target and strengthen the coarse-grained understanding of character content, we utilize multiple unpaired samples to align the feature distributions belonging to different character styles. By doing so, only a few target Chinese calligraphy characters are needed to generated expected style transferred characters. Experiments demonstrate that our method has a state-of-the-art generalization ability in few-shot Chinese character style transfer.
Single-Shot Motion Completion with Transformer
Mar 01, 2021
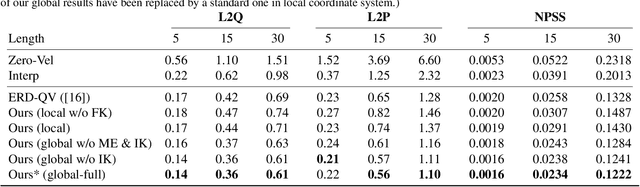
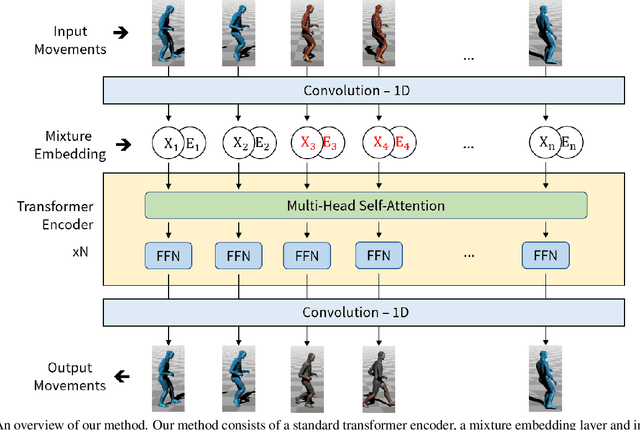
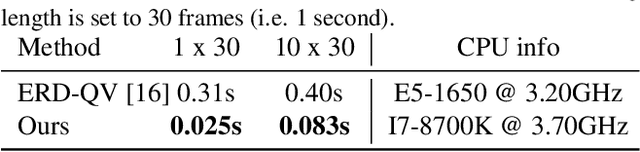
Motion completion is a challenging and long-discussed problem, which is of great significance in film and game applications. For different motion completion scenarios (in-betweening, in-filling, and blending), most previous methods deal with the completion problems with case-by-case designs. In this work, we propose a simple but effective method to solve multiple motion completion problems under a unified framework and achieves a new state of the art accuracy under multiple evaluation settings. Inspired by the recent great success of attention-based models, we consider the completion as a sequence to sequence prediction problem. Our method consists of two modules - a standard transformer encoder with self-attention that learns long-range dependencies of input motions, and a trainable mixture embedding module that models temporal information and discriminates key-frames. Our method can run in a non-autoregressive manner and predict multiple missing frames within a single forward propagation in real time. We finally show the effectiveness of our method in music-dance applications.
In-game Residential Home Planning via Visual Context-aware Global Relation Learning
Feb 23, 2021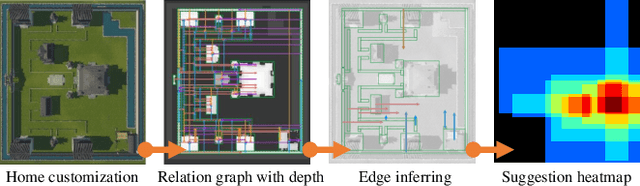
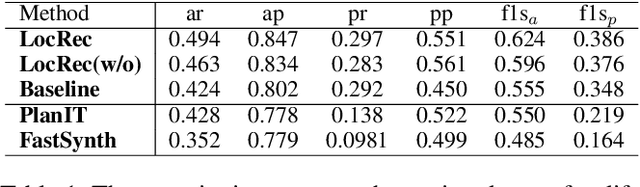
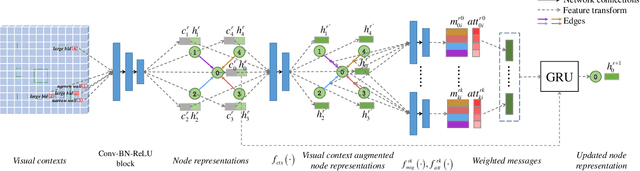
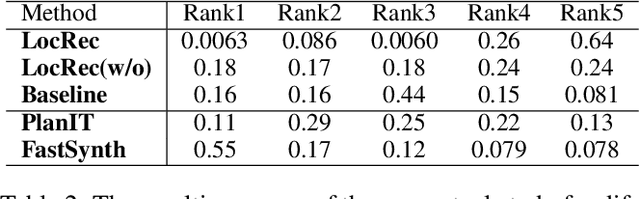
In this paper, we propose an effective global relation learning algorithm to recommend an appropriate location of a building unit for in-game customization of residential home complex. Given a construction layout, we propose a visual context-aware graph generation network that learns the implicit global relations among the scene components and infers the location of a new building unit. The proposed network takes as input the scene graph and the corresponding top-view depth image. It provides the location recommendations for a newly-added building units by learning an auto-regressive edge distribution conditioned on existing scenes. We also introduce a global graph-image matching loss to enhance the awareness of essential geometry semantics of the site. Qualitative and quantitative experiments demonstrate that the recommended location well reflects the implicit spatial rules of components in the residential estates, and it is instructive and practical to locate the building units in the 3D scene of the complex construction.
One-shot Face Reenactment Using Appearance Adaptive Normalization
Feb 20, 2021
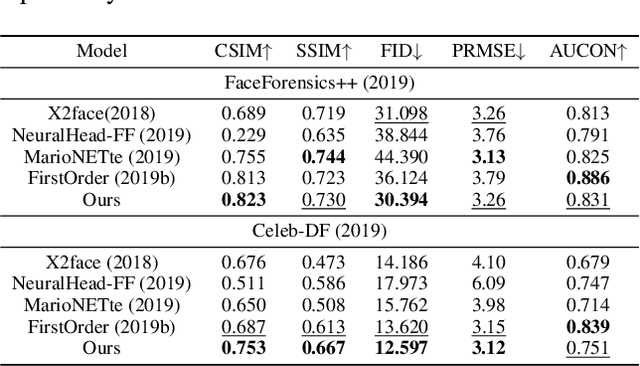
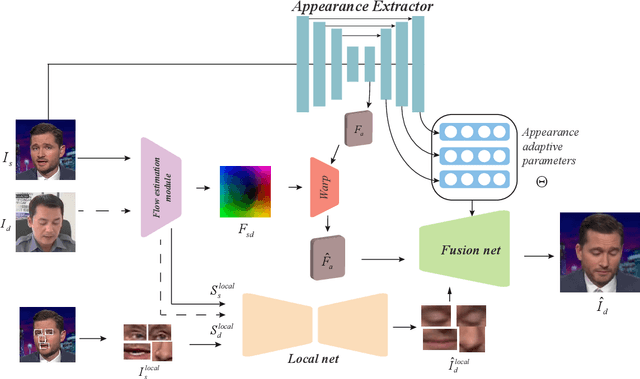
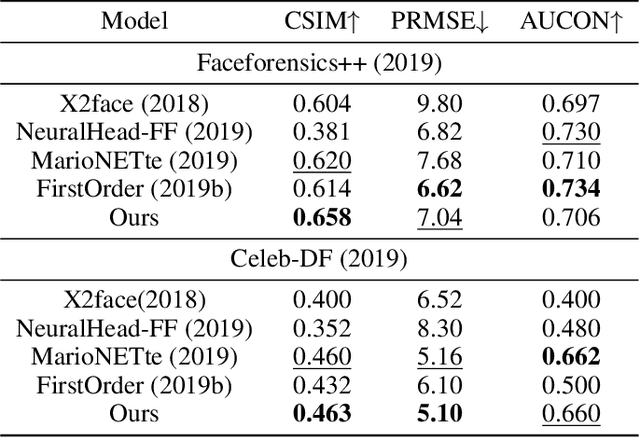
The paper proposes a novel generative adversarial network for one-shot face reenactment, which can animate a single face image to a different pose-and-expression (provided by a driving image) while keeping its original appearance. The core of our network is a novel mechanism called appearance adaptive normalization, which can effectively integrate the appearance information from the input image into our face generator by modulating the feature maps of the generator using the learned adaptive parameters. Furthermore, we specially design a local net to reenact the local facial components (i.e., eyes, nose and mouth) first, which is a much easier task for the network to learn and can in turn provide explicit anchors to guide our face generator to learn the global appearance and pose-and-expression. Extensive quantitative and qualitative experiments demonstrate the significant efficacy of our model compared with prior one-shot methods.
MeInGame: Create a Game Character Face from a Single Portrait
Feb 07, 2021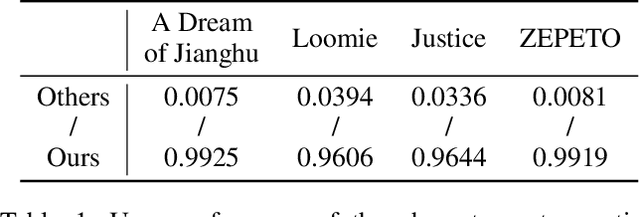
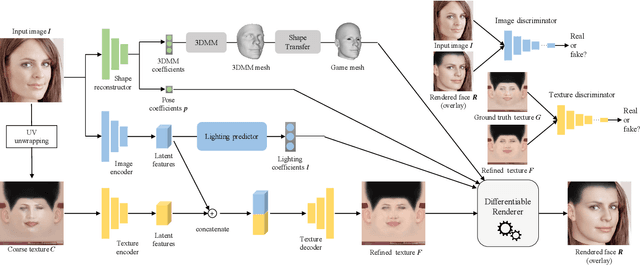
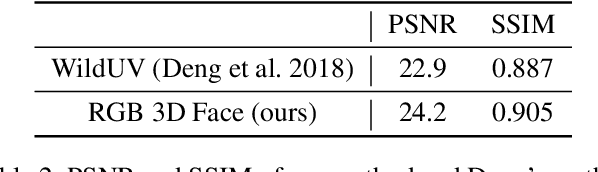

Many deep learning based 3D face reconstruction methods have been proposed recently, however, few of them have applications in games. Current game character customization systems either require players to manually adjust considerable face attributes to obtain the desired face, or have limited freedom of facial shape and texture. In this paper, we propose an automatic character face creation method that predicts both facial shape and texture from a single portrait, and it can be integrated into most existing 3D games. Although 3D Morphable Face Model (3DMM) based methods can restore accurate 3D faces from single images, the topology of 3DMM mesh is different from the meshes used in most games. To acquire fidelity texture, existing methods require a large amount of face texture data for training, while building such datasets is time-consuming and laborious. Besides, such a dataset collected under laboratory conditions may not generalized well to in-the-wild situations. To tackle these problems, we propose 1) a low-cost facial texture acquisition method, 2) a shape transfer algorithm that can transform the shape of a 3DMM mesh to games, and 3) a new pipeline for training 3D game face reconstruction networks. The proposed method not only can produce detailed and vivid game characters similar to the input portrait, but can also eliminate the influence of lighting and occlusions. Experiments show that our method outperforms state-of-the-art methods used in games.