 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Perspective to Boost Vision Transformer for Medical Image Classification
Jan 03, 2023Transformer has achieved impressive successes for various computer vision tasks. However, most of existing studies require to pretrain the Transformer backbone on a large-scale labeled dataset (e.g., ImageNet) for achieving satisfactory performance, which is usually unavailable for medical images. Additionally, due to the gap between medical and natural images, the improvement generated by the ImageNet pretrained weights significantly degrades while transferring the weights to medical image processing tasks. In this paper, we propose Bootstrap Own Latent of Transformer (BOLT), a self-supervised learning approach specifically for medical image classification with the Transformer backbone. Our BOLT consists of two networks, namely online and target branches, for self-supervised representation learning. Concretely, the online network is trained to predict the target network representation of the same patch embedding tokens with a different perturbation. To maximally excavate the impact of Transformer from limited medical data, we propose an auxiliary difficulty ranking task. The Transformer is enforced to identify which branch (i.e., online/target) is processing the more difficult perturbed tokens. Overall, the Transformer endeavours itself to distill the transformation-invariant features from the perturbed tokens to simultaneously achieve difficulty measurement and maintain the consistency of self-supervised representations. The proposed BOLT is evaluated on three medical image processing tasks, i.e., skin lesion classification, knee fatigue fracture grading and diabetic retinopathy grading. The experimental results validate the superiority of our BOLT for medical image classification, compared to ImageNet pretrained weights and state-of-the-art self-supervised learning approaches.
Orientation-Shared Convolution Representation for CT Metal Artifact Learning
Dec 26, 2022During X-ray computed tomography (CT) scanning, metallic implants carrying with patients often lead to adverse artifacts in the captured CT images and then impair the clinical treatment. Against this metal artifact reduction (MAR) task, the existing deep-learning-based methods have gained promising reconstruction performance. Nevertheless, there is still some room for further improvement of MAR performance and generalization ability, since some important prior knowledge underlying this specific task has not been fully exploited. Hereby, in this paper, we carefully analyze the characteristics of metal artifacts and propose an orientation-shared convolution representation strategy to adapt the physical prior structures of artifacts, i.e., rotationally symmetrical streaking patterns. The proposed method rationally adopts Fourier-series-expansion-based filter parametrization in artifact modeling, which can better separate artifacts from anatomical tissues and boost the model generalizability. Comprehensive experiments executed on synthesized and clinical datasets show the superiority of our method in detail preservation beyond the current representative MAR methods. Code will be available at \url{https://github.com/hongwang01/OSCNet}
Lesion Guided Explainable Few Weak-shot Medical Report Generation
Nov 17, 2022Medical images are widely used in clinical practice for diagnosis. Automatically generating interpretable medical reports can reduce radiologists' burden and facilitate timely care. However, most existing approaches to automatic report generation require sufficient labeled data for training. In addition, the learned model can only generate reports for the training classes, lacking the ability to adapt to previously unseen novel diseases. To this end, we propose a lesion guided explainable few weak-shot medical report generation framework that learns correlation between seen and novel classes through visual and semantic feature alignment, aiming to generate medical reports for diseases not observed in training. It integrates a lesion-centric feature extractor and a Transformer-based report generation module. Concretely, the lesion-centric feature extractor detects the abnormal regions and learns correlations between seen and novel classes with multi-view (visual and lexical) embeddings. Then, features of the detected regions and corresponding embeddings are concatenated as multi-view input to the report generation module for explainable report generation, including text descriptions and corresponding abnormal regions detected in the images. We conduct experiments on FFA-IR, a dataset providing explainable annotations, showing that our framework outperforms others on report generation for novel diseases.
Knowing the Past to Predict the Future: Reinforcement Virtual Learning
Nov 02, 2022



Reinforcement Learning (RL)-based control system has received considerable attention in recent decades. However, in many real-world problems, such as Batch Process Control, the environment is uncertain, which requires expensive interaction to acquire the state and reward values. In this paper, we present a cost-efficient framework, such that the RL model can evolve for itself in a Virtual Space using the predictive models with only historical data. The proposed framework enables a step-by-step RL model to predict the future state and select optimal actions for long-sight decisions. The main focuses are summarized as: 1) how to balance the long-sight and short-sight rewards with an optimal strategy; 2) how to make the virtual model interacting with real environment to converge to a final learning policy. Under the experimental settings of Fed-Batch Process, our method consistently outperforms the existing state-of-the-art methods.
Decoupled Mixup for Generalized Visual Recognition
Oct 26, 2022Convolutional neural networks (CNN) have demonstrated remarkable performance when the training and testing data are from the same distribution. However, such trained CNN models often largely degrade on testing data which is unseen and Out-Of-the-Distribution (OOD). To address this issue, we propose a novel "Decoupled-Mixup" method to train CNN models for OOD visual recognition. Different from previous work combining pairs of images homogeneously, our method decouples each image into discriminative and noise-prone regions, and then heterogeneously combines these regions of image pairs to train CNN models. Since the observation is that noise-prone regions such as textural and clutter backgrounds are adverse to the generalization ability of CNN models during training, we enhance features from discriminative regions and suppress noise-prone ones when combining an image pair. To further improve the generalization ability of trained models, we propose to disentangle discriminative and noise-prone regions in frequency-based and context-based fashions. Experiment results show the high generalization performance of our method on testing data that are composed of unseen contexts, where our method achieves 85.76\% top-1 accuracy in Track-1 and 79.92\% in Track-2 in the NICO Challenge. The source code is available at https://github.com/HaozheLiu-ST/NICOChallenge-OOD-Classification.
Improving Multi-turn Emotional Support Dialogue Generation with Lookahead Strategy Planning
Oct 09, 2022
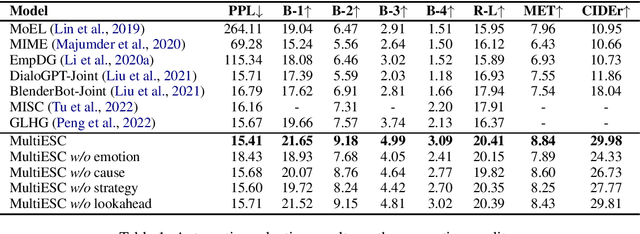
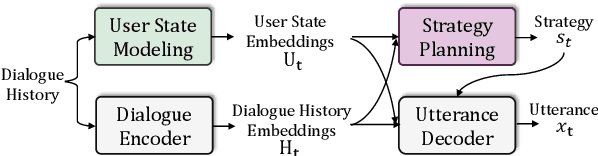
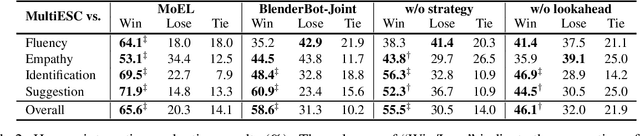
Providing Emotional Support (ES) to soothe people in emotional distress is an essential capability in social interactions. Most existing researches on building ES conversation systems only considered single-turn interactions with users, which was over-simplified. In comparison, multi-turn ES conversation systems can provide ES more effectively, but face several new technical challenges, including: (1) how to adopt appropriate support strategies to achieve the long-term dialogue goal of comforting the user's emotion; (2) how to dynamically model the user's state. In this paper, we propose a novel system MultiESC to address these issues. For strategy planning, drawing inspiration from the A* search algorithm, we propose lookahead heuristics to estimate the future user feedback after using particular strategies, which helps to select strategies that can lead to the best long-term effects. For user state modeling, MultiESC focuses on capturing users' subtle emotional expressions and understanding their emotion causes. Extensive experiments show that MultiESC significantly outperforms competitive baselines in both dialogue generation and strategy planning. Our codes are available at https://github.com/lwgkzl/MultiESC.
Prompt Combines Paraphrase: Teaching Pre-trained Models to Understand Rare Biomedical Words
Sep 14, 2022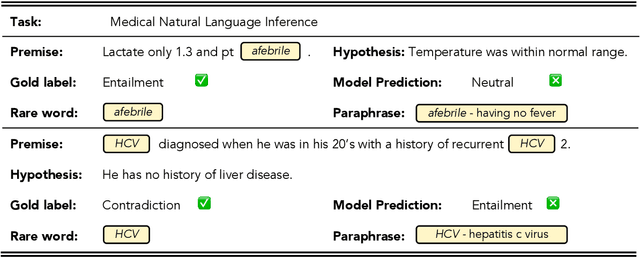
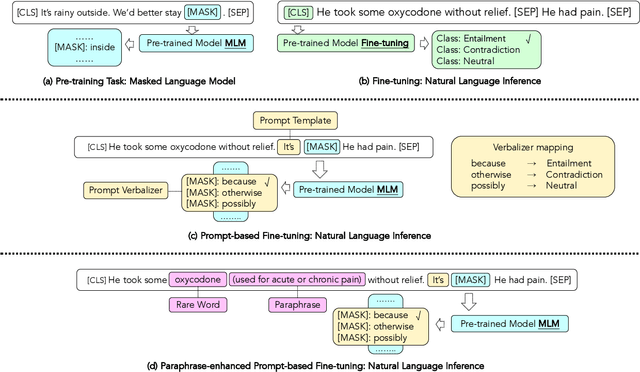
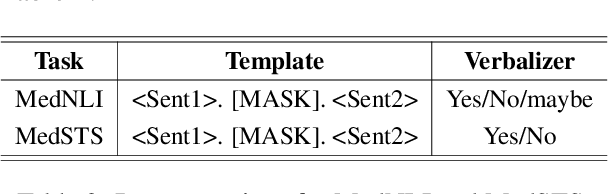
Prompt-based fine-tuning for pre-trained models has proven effective for many natural language processing tasks under few-shot settings in general domain. However, tuning with prompt in biomedical domain has not been investigated thoroughly. Biomedical words are often rare in general domain, but quite ubiquitous in biomedical contexts, which dramatically deteriorates the performance of pre-trained models on downstream biomedical applications even after fine-tuning, especially in low-resource scenarios. We propose a simple yet effective approach to helping models learn rare biomedical words during tuning with prompt. Experimental results show that our method can achieve up to 6% improvement in biomedical natural language inference task without any extra parameters or training steps using few-shot vanilla prompt settings.
A Benchmark for Weakly Semi-Supervised Abnormality Localization in Chest X-Rays
Sep 05, 2022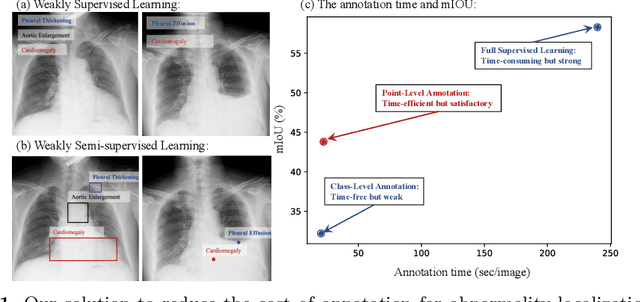
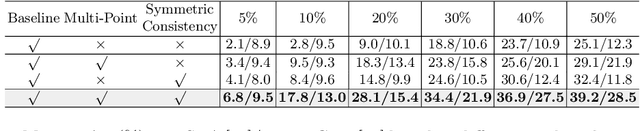
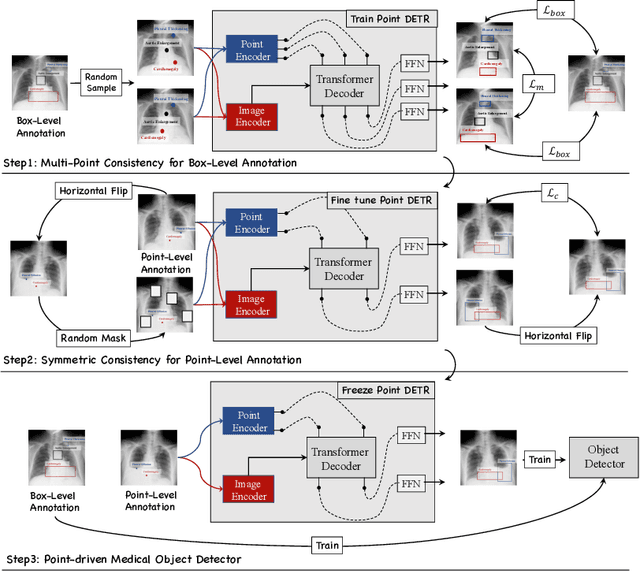
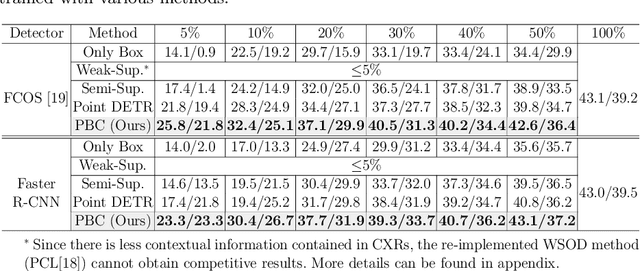
Accurate abnormality localization in chest X-rays (CXR) can benefit the clinical diagnosis of various thoracic diseases. However, the lesion-level annotation can only be performed by experienced radiologists, and it is tedious and time-consuming, thus difficult to acquire. Such a situation results in a difficulty to develop a fully-supervised abnormality localization system for CXR. In this regard, we propose to train the CXR abnormality localization framework via a weakly semi-supervised strategy, termed Point Beyond Class (PBC), which utilizes a small number of fully annotated CXRs with lesion-level bounding boxes and extensive weakly annotated samples by points. Such a point annotation setting can provide weakly instance-level information for abnormality localization with a marginal annotation cost. Particularly, the core idea behind our PBC is to learn a robust and accurate mapping from the point annotations to the bounding boxes against the variance of annotated points. To achieve that, a regularization term, namely multi-point consistency, is proposed, which drives the model to generate the consistent bounding box from different point annotations inside the same abnormality. Furthermore, a self-supervision, termed symmetric consistency, is also proposed to deeply exploit the useful information from the weakly annotated data for abnormality localization. Experimental results on RSNA and VinDr-CXR datasets justify the effectiveness of the proposed method. When less than 20% box-level labels are used for training, an improvement of ~5 in mAP can be achieved by our PBC, compared to the current state-of-the-art method (i.e., Point DETR). Code is available at https://github.com/HaozheLiu-ST/Point-Beyond-Class.
Multi-modal Contrastive Representation Learning for Entity Alignment
Sep 02, 2022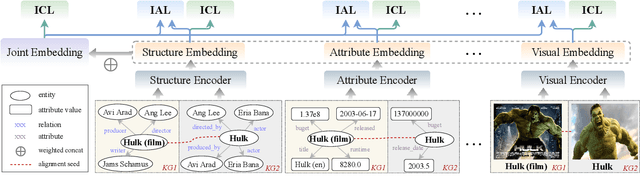
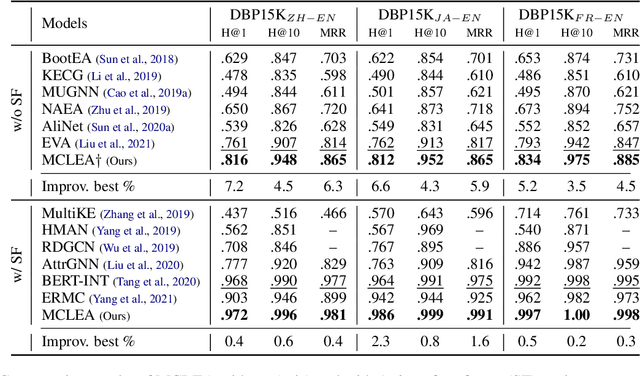
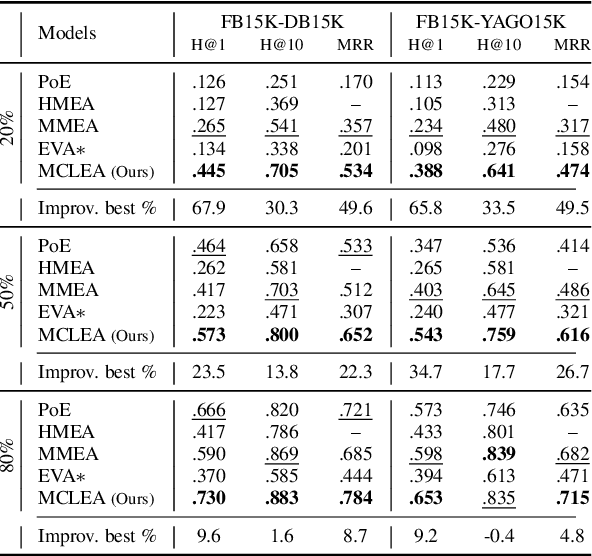
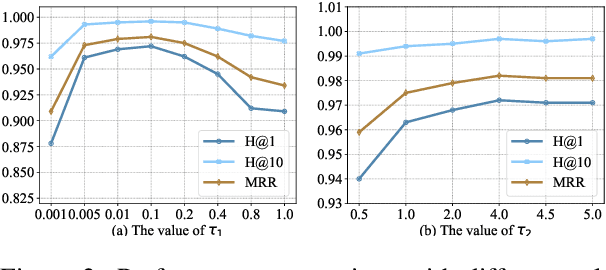
Multi-modal entity alignment aims to identify equivalent entities between two different multi-modal knowledge graphs, which consist of structural triples and images associated with entities. Most previous works focus on how to utilize and encode information from different modalities, while it is not trivial to leverage multi-modal knowledge in entity alignment because of the modality heterogeneity. In this paper, we propose MCLEA, a Multi-modal Contrastive Learning based Entity Alignment model, to obtain effective joint representations for multi-modal entity alignment. Different from previous works, MCLEA considers task-oriented modality and models the inter-modal relationships for each entity representation. In particular, MCLEA firstly learns multiple individual representations from multiple modalities, and then performs contrastive learning to jointly model intra-modal and inter-modal interactions. Extensive experimental results show that MCLEA outperforms state-of-the-art baselines on public datasets under both supervised and unsupervised settings.
Seg4Reg+: Consistency Learning between Spine Segmentation and Cobb Angle Regression
Aug 26, 2022Automated methods for Cobb angle estimation are of high demand for scoliosis assessment. Existing methods typically calculate the Cobb angle from landmark estimation, or simply combine the low-level task (e.g., landmark detection and spine segmentation) with the Cobb angle regression task, without fully exploring the benefits from each other. In this study, we propose a novel multi-task framework, named Seg4Reg+, which jointly optimizes the segmentation and regression networks. We thoroughly investigate both local and global consistency and knowledge transfer between each other. Specifically, we propose an attention regularization module leveraging class activation maps (CAMs) from image-segmentation pairs to discover additional supervision in the regression network, and the CAMs can serve as a region-of-interest enhancement gate to facilitate the segmentation task in turn. Meanwhile, we design a novel triangle consistency learning to train the two networks jointly for global optimization. The evaluations performed on the public AASCE Challenge dataset demonstrate the effectiveness of each module and superior performance of our model to the state-of-the-art methods.