 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Aug 08, 2025Current multimodal large language models (MLLMs) still face significant challenges in complex visual tasks (e.g., spatial understanding, fine-grained perception). Prior methods have tried to incorporate visual reasoning, however, they fail to leverage attention correction with spatial cues to iteratively refine their focus on prompt-relevant regions. In this paper, we introduce SIFThinker, a spatially-aware "think-with-images" framework that mimics human visual perception. Specifically, SIFThinker enables attention correcting and image region focusing by interleaving depth-enhanced bounding boxes and natural language. Our contributions are twofold: First, we introduce a reverse-expansion-forward-inference strategy that facilitates the generation of interleaved image-text chains of thought for process-level supervision, which in turn leads to the construction of the SIF-50K dataset. Besides, we propose GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual grounding into a unified reasoning pipeline, teaching the model to dynamically correct and focus on prompt-relevant regions. Extensive experiments demonstrate that SIFThinker outperforms state-of-the-art methods in spatial understanding and fine-grained visual perception, while maintaining strong general capabilities, highlighting the effectiveness of our method.
ListConRanker: A Contrastive Text Reranker with Listwise Encoding
Jan 13, 2025



Reranker models aim to re-rank the passages based on the semantics similarity between the given query and passages, which have recently received more attention due to the wide application of the Retrieval-Augmented Generation. Most previous methods apply pointwise encoding, meaning that it can only encode the context of the query for each passage input into the model. However, for the reranker model, given a query, the comparison results between passages are even more important, which is called listwise encoding. Besides, previous models are trained using the cross-entropy loss function, which leads to issues of unsmooth gradient changes during training and low training efficiency. To address these issues, we propose a novel Listwise-encoded Contrastive text reRanker (ListConRanker). It can help the passage to be compared with other passages during the encoding process, and enhance the contrastive information between positive examples and between positive and negative examples. At the same time, we use the circle loss to train the model to increase the flexibility of gradients and solve the problem of training efficiency. Experimental results show that ListConRanker achieves state-of-the-art performance on the reranking benchmark of Chinese Massive Text Embedding Benchmark, including the cMedQA1.0, cMedQA2.0, MMarcoReranking, and T2Reranking datasets.
Semi-supervised Credit Card Fraud Detection via Attribute-Driven Graph Representation
Dec 24, 2024



Credit card fraud incurs a considerable cost for both cardholders and issuing banks. Contemporary methods apply machine learning-based classifiers to detect fraudulent behavior from labeled transaction records. But labeled data are usually a small proportion of billions of real transactions due to expensive labeling costs, which implies that they do not well exploit many natural features from unlabeled data. Therefore, we propose a semi-supervised graph neural network for fraud detection. Specifically, we leverage transaction records to construct a temporal transaction graph, which is composed of temporal transactions (nodes) and interactions (edges) among them. Then we pass messages among the nodes through a Gated Temporal Attention Network (GTAN) to learn the transaction representation. We further model the fraud patterns through risk propagation among transactions. The extensive experiments are conducted on a real-world transaction dataset and two publicly available fraud detection datasets. The result shows that our proposed method, namely GTAN, outperforms other state-of-the-art baselines on three fraud detection datasets. Semi-supervised experiments demonstrate the excellent fraud detection performance of our model with only a tiny proportion of labeled data.
* 9 pages, 5 figures, AAAI 2023, code: https://github.com/AI4Risk/antifraud
Efficient and Accurate Prompt Optimization: the Benefit of Memory in Exemplar-Guided Reflection
Nov 12, 2024



Automatic prompt engineering aims to enhance the generation quality of large language models (LLMs). Recent works utilize feedbacks generated from erroneous cases to guide the prompt optimization. During inference, they may further retrieve several semantically-related exemplars and concatenate them to the optimized prompts to improve the performance. However, those works only utilize the feedback at the current step, ignoring historical and unseleccted feedbacks which are potentially beneficial. Moreover, the selection of exemplars only considers the general semantic relationship and may not be optimal in terms of task performance and matching with the optimized prompt. In this work, we propose an Exemplar-Guided Reflection with Memory mechanism (ERM) to realize more efficient and accurate prompt optimization. Specifically, we design an exemplar-guided reflection mechanism where the feedback generation is additionally guided by the generated exemplars. We further build two kinds of memory to fully utilize the historical feedback information and support more effective exemplar retrieval. Empirical evaluations show our method surpasses previous state-of-the-arts with less optimization steps, i.e., improving F1 score by 10.1 on LIAR dataset, and reducing half of the optimization steps on ProTeGi.
Improving Multi-turn Emotional Support Dialogue Generation with Lookahead Strategy Planning
Oct 09, 2022
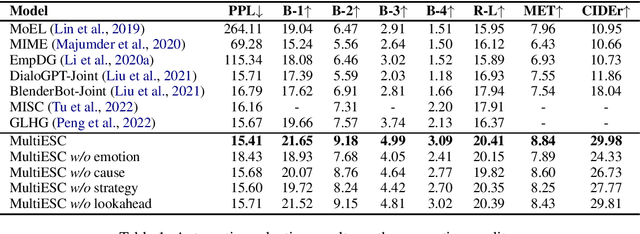
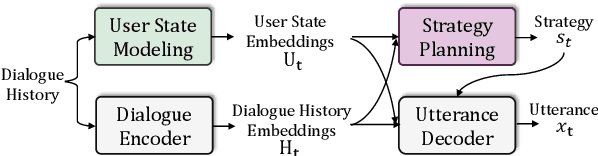
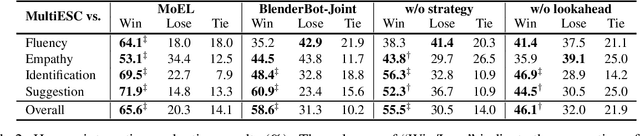
Providing Emotional Support (ES) to soothe people in emotional distress is an essential capability in social interactions. Most existing researches on building ES conversation systems only considered single-turn interactions with users, which was over-simplified. In comparison, multi-turn ES conversation systems can provide ES more effectively, but face several new technical challenges, including: (1) how to adopt appropriate support strategies to achieve the long-term dialogue goal of comforting the user's emotion; (2) how to dynamically model the user's state. In this paper, we propose a novel system MultiESC to address these issues. For strategy planning, drawing inspiration from the A* search algorithm, we propose lookahead heuristics to estimate the future user feedback after using particular strategies, which helps to select strategies that can lead to the best long-term effects. For user state modeling, MultiESC focuses on capturing users' subtle emotional expressions and understanding their emotion causes. Extensive experiments show that MultiESC significantly outperforms competitive baselines in both dialogue generation and strategy planning. Our codes are available at https://github.com/lwgkzl/MultiESC.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
May 02, 2022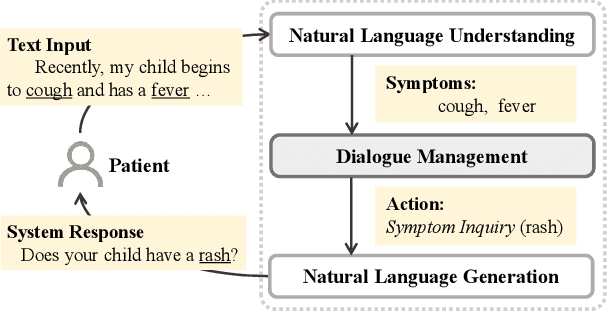
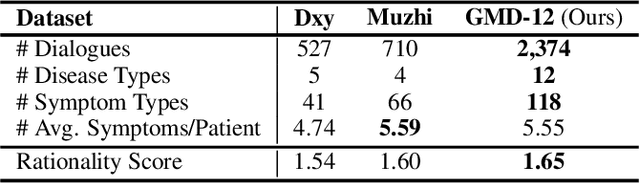
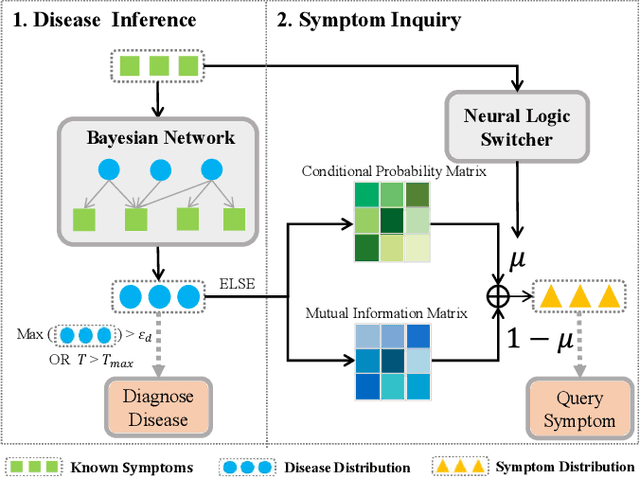
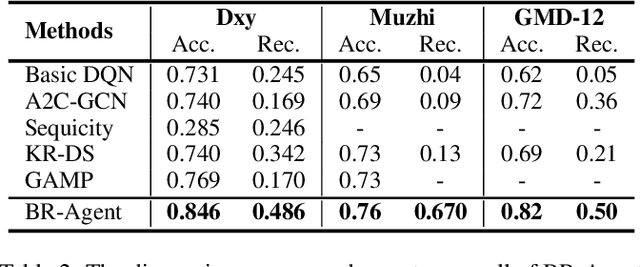
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Tell Me How to Survey: Literature Review Made Simple with Automatic Reading Path Generation
Oct 14, 2021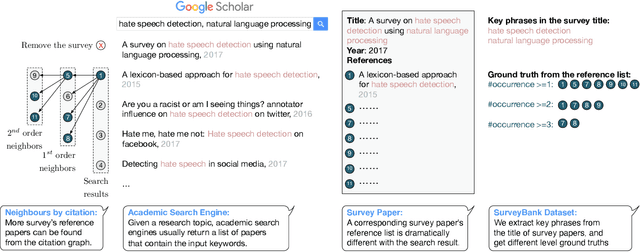
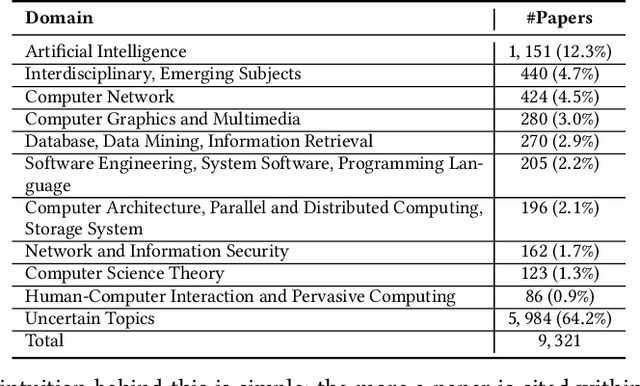
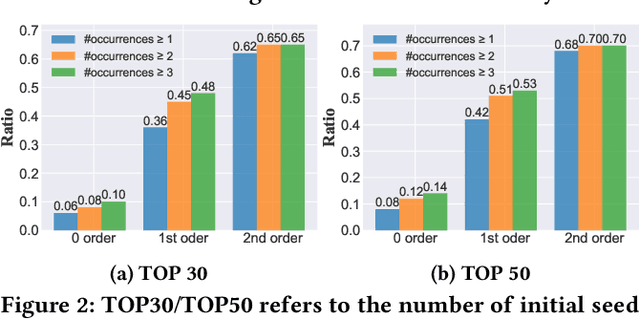

Recent years have witnessed the dramatic growth of paper volumes with plenty of new research papers published every day, especially in the area of computer science. How to glean papers worth reading from the massive literature to do a quick survey or keep up with the latest advancement about a specific research topic has become a challenging task. Existing academic search engines such as Google Scholar return relevant papers by individually calculating the relevance between each paper and query. However, such systems usually omit the prerequisite chains of a research topic and cannot form a meaningful reading path. In this paper, we introduce a new task named Reading Path Generation (RPG) which aims at automatically producing a path of papers to read for a given query. To serve as a research benchmark, we further propose SurveyBank, a dataset consisting of large quantities of survey papers in the field of computer science as well as their citation relationships. Each survey paper contains key phrases extracted from its title and multi-level reading lists inferred from its references. Furthermore, we propose a graph-optimization-based approach for reading path generation which takes the relationship between papers into account. Extensive evaluations demonstrate that our approach outperforms other baselines. A Real-time Reading Path Generation System (RePaGer) has been also implemented with our designed model. To the best of our knowledge, we are the first to target this important research problem. Our source code of RePaGer system and SurveyBank dataset can be found on here.
Refining BERT Embeddings for Document Hashing via Mutual Information Maximization
Sep 07, 2021


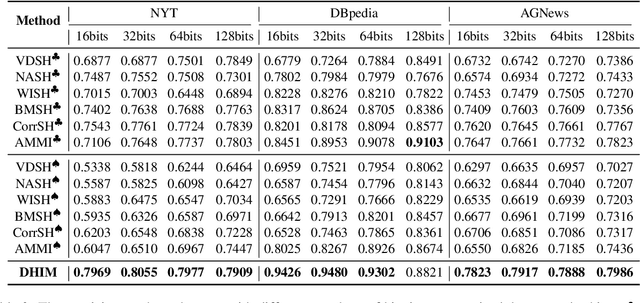
Existing unsupervised document hashing methods are mostly established on generative models. Due to the difficulties of capturing long dependency structures, these methods rarely model the raw documents directly, but instead to model the features extracted from them (e.g. bag-of-words (BOW), TFIDF). In this paper, we propose to learn hash codes from BERT embeddings after observing their tremendous successes on downstream tasks. As a first try, we modify existing generative hashing models to accommodate the BERT embeddings. However, little improvement is observed over the codes learned from the old BOW or TFIDF features. We attribute this to the reconstruction requirement in the generative hashing, which will enforce irrelevant information that is abundant in the BERT embeddings also compressed into the codes. To remedy this issue, a new unsupervised hashing paradigm is further proposed based on the mutual information (MI) maximization principle. Specifically, the method first constructs appropriate global and local codes from the documents and then seeks to maximize their mutual information. Experimental results on three benchmark datasets demonstrate that the proposed method is able to generate hash codes that outperform existing ones learned from BOW features by a substantial margin.
Prototypical Graph Contrastive Learning
Jun 17, 2021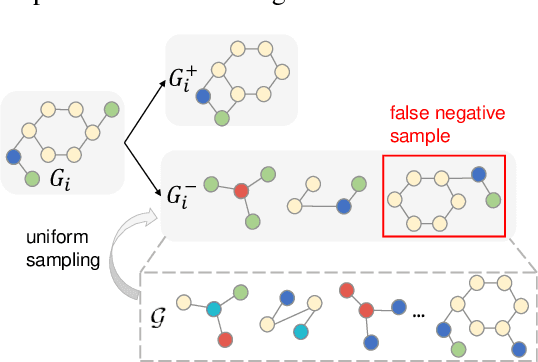
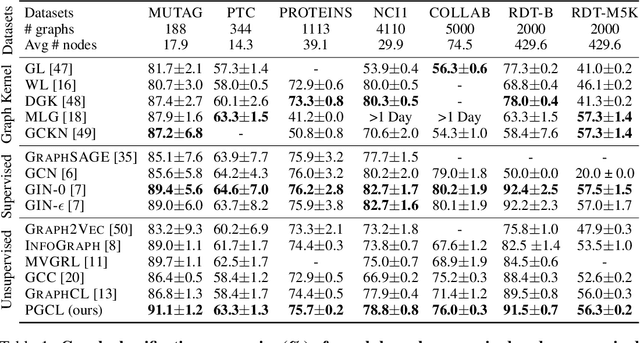
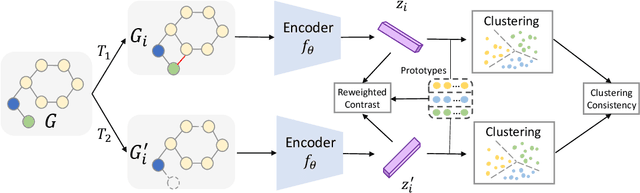
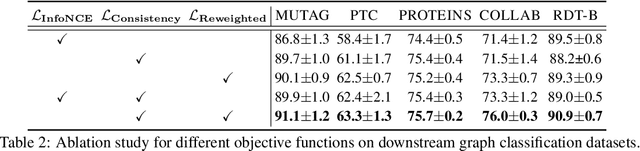
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.
Integrating Semantics and Neighborhood Information with Graph-Driven Generative Models for Document Retrieval
May 27, 2021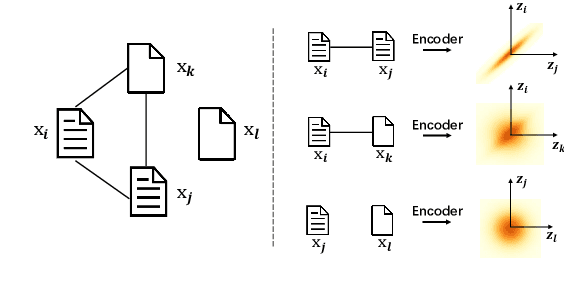
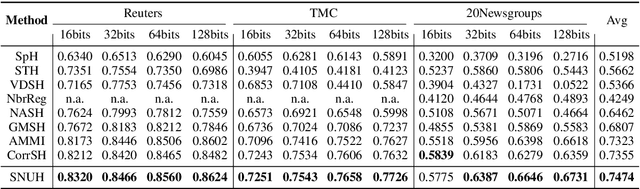
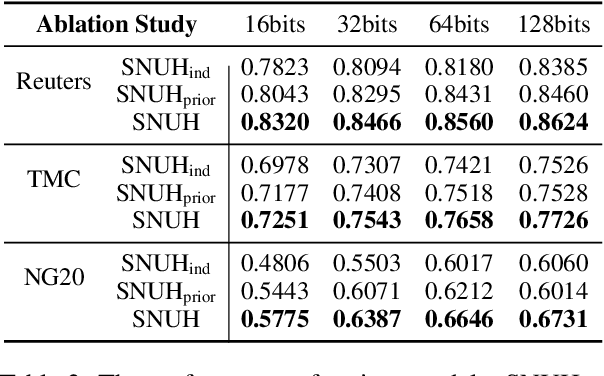
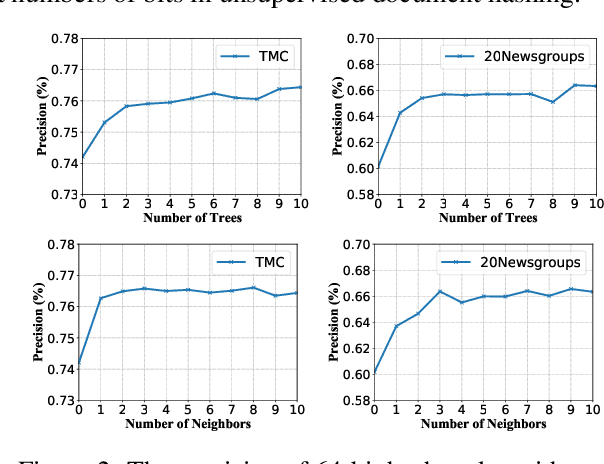
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.\