 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy Layers to Make Fine-Tuned Diffusion Models More Traceable
May 01, 2024



Foundational generative models should be traceable to protect their owners and facilitate safety regulation. To achieve this, traditional approaches embed identifiers based on supervisory trigger-response signals, which are commonly known as backdoor watermarks. They are prone to failure when the model is fine-tuned with nontrigger data. Our experiments show that this vulnerability is due to energetic changes in only a few 'busy' layers during fine-tuning. This yields a novel arbitrary-in-arbitrary-out (AIAO) strategy that makes watermarks resilient to fine-tuning-based removal. The trigger-response pairs of AIAO samples across various neural network depths can be used to construct watermarked subpaths, employing Monte Carlo sampling to achieve stable verification results. In addition, unlike the existing methods of designing a backdoor for the input/output space of diffusion models, in our method, we propose to embed the backdoor into the feature space of sampled subpaths, where a mask-controlled trigger function is proposed to preserve the generation performance and ensure the invisibility of the embedded backdoor. Our empirical studies on the MS-COCO, AFHQ, LSUN, CUB-200, and DreamBooth datasets confirm the robustness of AIAO; while the verification rates of other trigger-based methods fall from ~90% to ~70% after fine-tuning, those of our method remain consistently above 90%.
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Apr 03, 2024This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Fingerprint Presentation Attack Detector Using Global-Local Model
Feb 20, 2024The vulnerability of automated fingerprint recognition systems (AFRSs) to presentation attacks (PAs) promotes the vigorous development of PA detection (PAD) technology. However, PAD methods have been limited by information loss and poor generalization ability, resulting in new PA materials and fingerprint sensors. This paper thus proposes a global-local model-based PAD (RTK-PAD) method to overcome those limitations to some extent. The proposed method consists of three modules, called: 1) the global module; 2) the local module; and 3) the rethinking module. By adopting the cut-out-based global module, a global spoofness score predicted from nonlocal features of the entire fingerprint images can be achieved. While by using the texture in-painting-based local module, a local spoofness score predicted from fingerprint patches is obtained. The two modules are not independent but connected through our proposed rethinking module by localizing two discriminative patches for the local module based on the global spoofness score. Finally, the fusion spoofness score by averaging the global and local spoofness scores is used for PAD. Our experimental results evaluated on LivDet 2017 show that the proposed RTK-PAD can achieve an average classification error (ACE) of 2.28% and a true detection rate (TDR) of 91.19% when the false detection rate (FDR) equals 1.0%, which significantly outperformed the state-of-the-art methods by $\sim$10% in terms of TDR (91.19% versus 80.74%).
* This paper was accepted by IEEE Transactions on Cybernetics. Current version is updated with minor revisions on introduction and related works
Dual Teacher Knowledge Distillation with Domain Alignment for Face Anti-spoofing
Jan 02, 2024



Face recognition systems have raised concerns due to their vulnerability to different presentation attacks, and system security has become an increasingly critical concern. Although many face anti-spoofing (FAS) methods perform well in intra-dataset scenarios, their generalization remains a challenge. To address this issue, some methods adopt domain adversarial training (DAT) to extract domain-invariant features. However, the competition between the encoder and the domain discriminator can cause the network to be difficult to train and converge. In this paper, we propose a domain adversarial attack (DAA) method to mitigate the training instability problem by adding perturbations to the input images, which makes them indistinguishable across domains and enables domain alignment. Moreover, since models trained on limited data and types of attacks cannot generalize well to unknown attacks, we propose a dual perceptual and generative knowledge distillation framework for face anti-spoofing that utilizes pre-trained face-related models containing rich face priors. Specifically, we adopt two different face-related models as teachers to transfer knowledge to the target student model. The pre-trained teacher models are not from the task of face anti-spoofing but from perceptual and generative tasks, respectively, which implicitly augment the data. By combining both DAA and dual-teacher knowledge distillation, we develop a dual teacher knowledge distillation with domain alignment framework (DTDA) for face anti-spoofing. The advantage of our proposed method has been verified through extensive ablation studies and comparison with state-of-the-art methods on public datasets across multiple protocols.
BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion
Aug 10, 2023



Recent text-to-image diffusion models have demonstrated an astonishing capacity to generate high-quality images. However, researchers mainly studied the way of synthesizing images with only text prompts. While some works have explored using other modalities as conditions, considerable paired data, e.g., box/mask-image pairs, and fine-tuning time are required for nurturing models. As such paired data is time-consuming and labor-intensive to acquire and restricted to a closed set, this potentially becomes the bottleneck for applications in an open world. This paper focuses on the simplest form of user-provided conditions, e.g., box or scribble. To mitigate the aforementioned problem, we propose a training-free method to control objects and contexts in the synthesized images adhering to the given spatial conditions. Specifically, three spatial constraints, i.e., Inner-Box, Outer-Box, and Corner Constraints, are designed and seamlessly integrated into the denoising step of diffusion models, requiring no additional training and massive annotated layout data. Extensive results show that the proposed constraints can control what and where to present in the images while retaining the ability of the Stable Diffusion model to synthesize with high fidelity and diverse concept coverage. The code is publicly available at https://github.com/Sierkinhane/BoxDiff.
Dynamically Masked Discriminator for Generative Adversarial Networks
Jun 13, 2023Training Generative Adversarial Networks (GANs) remains a challenging problem. The discriminator trains the generator by learning the distribution of real/generated data. However, the distribution of generated data changes throughout the training process, which is difficult for the discriminator to learn. In this paper, we propose a novel method for GANs from the viewpoint of online continual learning. We observe that the discriminator model, trained on historically generated data, often slows down its adaptation to the changes in the new arrival generated data, which accordingly decreases the quality of generated results. By treating the generated data in training as a stream, we propose to detect whether the discriminator slows down the learning of new knowledge in generated data. Therefore, we can explicitly enforce the discriminator to learn new knowledge fast. Particularly, we propose a new discriminator, which automatically detects its retardation and then dynamically masks its features, such that the discriminator can adaptively learn the temporally-vary distribution of generated data. Experimental results show our method outperforms the state-of-the-art approaches.
Improving GAN Training via Feature Space Shrinkage
Mar 02, 2023Due to the outstanding capability for data generation, Generative Adversarial Networks (GANs) have attracted considerable attention in unsupervised learning. However, training GANs is difficult, since the training distribution is dynamic for the discriminator, leading to unstable image representation. In this paper, we address the problem of training GANs from a novel perspective, \emph{i.e.,} robust image classification. Motivated by studies on robust image representation, we propose a simple yet effective module, namely AdaptiveMix, for GANs, which shrinks the regions of training data in the image representation space of the discriminator. Considering it is intractable to directly bound feature space, we propose to construct hard samples and narrow down the feature distance between hard and easy samples. The hard samples are constructed by mixing a pair of training images. We evaluate the effectiveness of our AdaptiveMix with widely-used and state-of-the-art GAN architectures. The evaluation results demonstrate that our AdaptiveMix can facilitate the training of GANs and effectively improve the image quality of generated samples. We also show that our AdaptiveMix can be further applied to image classification and Out-Of-Distribution (OOD) detection tasks, by equipping it with state-of-the-art methods. Extensive experiments on seven publicly available datasets show that our method effectively boosts the performance of baselines. The code is publicly available at https://github.com/WentianZhang-ML/AdaptiveMix.
Decoupled Mixup for Generalized Visual Recognition
Oct 26, 2022Convolutional neural networks (CNN) have demonstrated remarkable performance when the training and testing data are from the same distribution. However, such trained CNN models often largely degrade on testing data which is unseen and Out-Of-the-Distribution (OOD). To address this issue, we propose a novel "Decoupled-Mixup" method to train CNN models for OOD visual recognition. Different from previous work combining pairs of images homogeneously, our method decouples each image into discriminative and noise-prone regions, and then heterogeneously combines these regions of image pairs to train CNN models. Since the observation is that noise-prone regions such as textural and clutter backgrounds are adverse to the generalization ability of CNN models during training, we enhance features from discriminative regions and suppress noise-prone ones when combining an image pair. To further improve the generalization ability of trained models, we propose to disentangle discriminative and noise-prone regions in frequency-based and context-based fashions. Experiment results show the high generalization performance of our method on testing data that are composed of unseen contexts, where our method achieves 85.76\% top-1 accuracy in Track-1 and 79.92\% in Track-2 in the NICO Challenge. The source code is available at https://github.com/HaozheLiu-ST/NICOChallenge-OOD-Classification.
A Uniform Representation Learning Method for OCT-based Fingerprint Presentation Attack Detection and Reconstruction
Sep 25, 2022
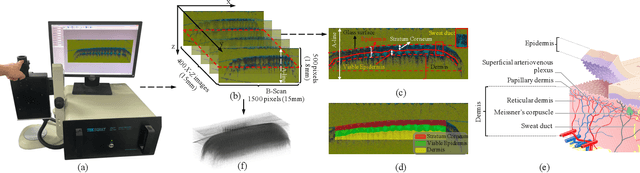

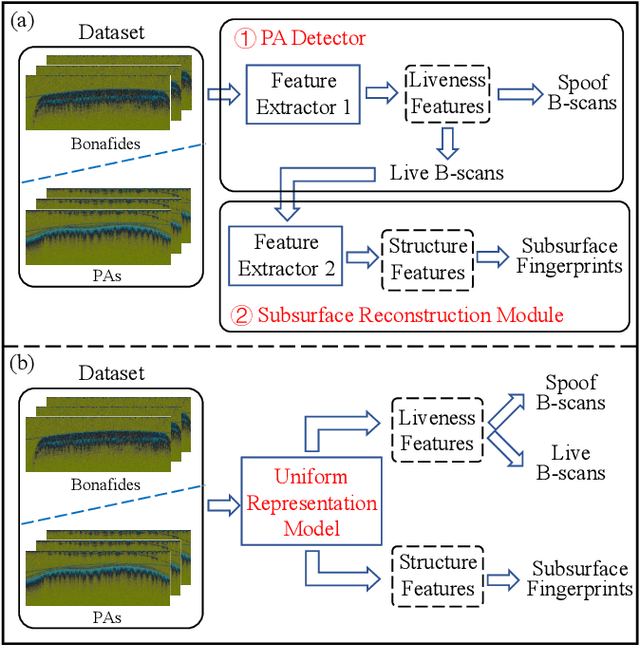
The technology of optical coherence tomography (OCT) to fingerprint imaging opens up a new research potential for fingerprint recognition owing to its ability to capture depth information of the skin layers. Developing robust and high security Automated Fingerprint Recognition Systems (AFRSs) are possible if the depth information can be fully utilized. However, in existing studies, Presentation Attack Detection (PAD) and subsurface fingerprint reconstruction based on depth information are treated as two independent branches, resulting in high computation and complexity of AFRS building.Thus, this paper proposes a uniform representation model for OCT-based fingerprint PAD and subsurface fingerprint reconstruction. Firstly, we design a novel semantic segmentation network which only trained by real finger slices of OCT-based fingerprints to extract multiple subsurface structures from those slices (also known as B-scans). The latent codes derived from the network are directly used to effectively detect the PA since they contain abundant subsurface biological information, which is independent with PA materials and has strong robustness for unknown PAs. Meanwhile, the segmented subsurface structures are adopted to reconstruct multiple subsurface 2D fingerprints. Recognition can be easily achieved by using existing mature technologies based on traditional 2D fingerprints. Extensive experiments are carried on our own established database, which is the largest public OCT-based fingerprint database with 2449 volumes. In PAD task, our method can improve 0.33% Acc from the state-of-the-art method. For reconstruction performance, our method achieves the best performance with 0.834 mIOU and 0.937 PA. By comparing with the recognition performance on surface 2D fingerprints, the effectiveness of our proposed method on high quality subsurface fingerprint reconstruction is further proved.
Face Presentation Attack Detection using Taskonomy Feature
Nov 22, 2021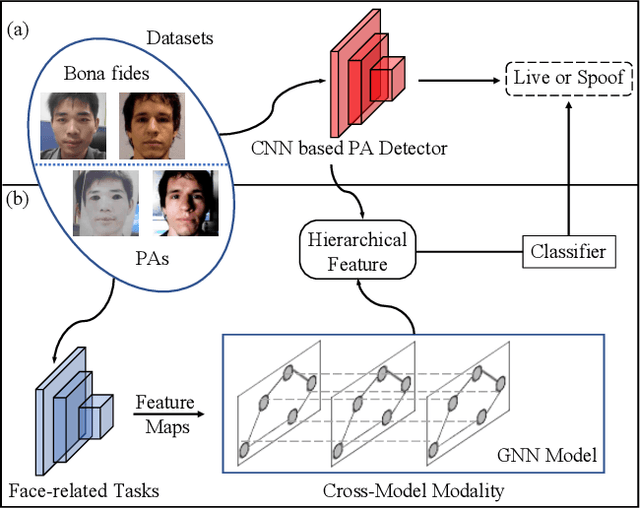

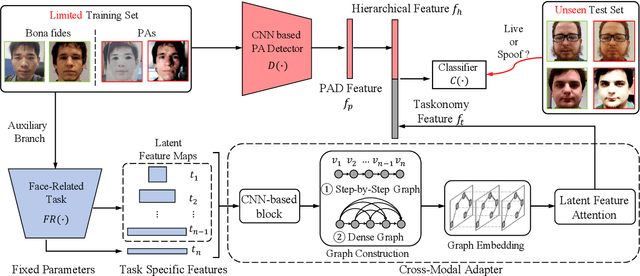
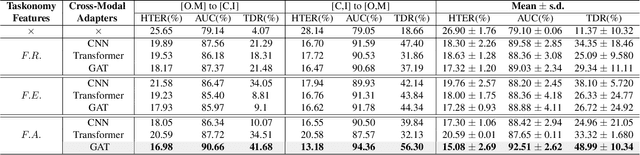
The robustness and generalization ability of Presentation Attack Detection (PAD) methods is critical to ensure the security of Face Recognition Systems (FRSs). However, in the real scenario, Presentation Attacks (PAs) are various and hard to be collected. Existing PAD methods are highly dependent on the limited training set and cannot generalize well to unknown PAs. Unlike PAD task, other face-related tasks trained by huge amount of real faces (e.g. face recognition and attribute editing) can be effectively adopted into different application scenarios. Inspired by this, we propose to apply taskonomy (task taxonomy) from other face-related tasks to solve face PAD, so as to improve the generalization ability in detecting PAs. The proposed method, first introduces task specific features from other face-related tasks, then, we design a Cross-Modal Adapter using a Graph Attention Network (GAT) to re-map such features to adapt to PAD task. Finally, face PAD is achieved by using the hierarchical features from a CNN-based PA detector and the re-mapped features. The experimental results show that the proposed method can achieve significant improvements in the complicated and hybrid datasets, when compared with the state-of-the-art methods. In particular, when trained using OULU-NPU, CASIA-FASD, and Idiap Replay-Attack, we obtain HTER (Half Total Error Rate) of 5.48% in MSU-MFSD, outperforming the baseline by 7.39%. Code will be made publicly available.