 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiDx: A Multi-Source Knowledge Integration Framework towards Diagnostic Reasoning
Apr 27, 2026Diagnostic prediction and clinical reasoning are critical tasks in healthcare applications. While Large Language Models (LLMs) have shown strong capabilities in commonsense reasoning, they still struggle with diagnostic reasoning due to limited domain knowledge. Existing approaches often rely on internal model knowledge or static knowledge bases, resulting in knowledge insufficiency and limited adaptability, which hinder their capacity to perform diagnostic reasoning. Moreover, these methods focus solely on the accuracy of final predictions, overlooking alignment with standard clinical reasoning trajectories. To this end, we propose MultiDx, a two-stage diagnostic reasoning framework that performs differential diagnosis by analyzing evidence collected from multiple knowledge sources. Specifically, it first generates suspected diagnoses and reasoning paths by leveraging knowledge from web search, SOAP-formatted case, and clinical case database. Then it integrates multi-perspective evidence through matching, voting, and differential diagnosis to generate the final prediction.~Extensive experiments on two public benchmarks demonstrate the effectiveness of our approach.
AdapTime: Enabling Adaptive Temporal Reasoning in Large Language Models
Apr 27, 2026Large language models have demonstrated strong reasoning capabilities in general knowledge question answering. However, their ability to handle temporal information remains limited. To address this limitation, existing approaches often involve external tools or manual verification and are tailored to specific scenarios, leading to poor generalizability. Moreover, these methods apply a fixed pipeline to all questions, overlooking the fact that different types of temporal questions require distinct reasoning strategies, which leads to unnecessary processing for simple cases and inadequate reasoning for complex ones. To this end, we propose AdapTime, an adaptive temporal reasoning method that dynamically executes reasoning steps based on the input context. Specifically, it involves three temporal reasoning actions: reformulate, rewrite and review, with an LLM planner guiding the reasoning process. AdapTime integrates seamlessly with state-of-the-art LLMs and significantly enhances their temporal reasoning capabilities without relying on external support. Extensive experiments demonstrate the effectiveness of our approach.
Multi-perspective Improvement of Knowledge Graph Completion with Large Language Models
Mar 04, 2024



Knowledge graph completion (KGC) is a widely used method to tackle incompleteness in knowledge graphs (KGs) by making predictions for missing links. Description-based KGC leverages pre-trained language models to learn entity and relation representations with their names or descriptions, which shows promising results. However, the performance of description-based KGC is still limited by the quality of text and the incomplete structure, as it lacks sufficient entity descriptions and relies solely on relation names, leading to sub-optimal results. To address this issue, we propose MPIKGC, a general framework to compensate for the deficiency of contextualized knowledge and improve KGC by querying large language models (LLMs) from various perspectives, which involves leveraging the reasoning, explanation, and summarization capabilities of LLMs to expand entity descriptions, understand relations, and extract structures, respectively. We conducted extensive evaluation of the effectiveness and improvement of our framework based on four description-based KGC models and four datasets, for both link prediction and triplet classification tasks.
Editing Factual Knowledge and Explanatory Ability of Medical Large Language Models
Feb 28, 2024



Model editing aims to precisely modify the behaviours of large language models (LLMs) on specific knowledge while keeping irrelevant knowledge unchanged. It has been proven effective in resolving hallucination and out-of-date issues in LLMs. As a result, it can boost the application of LLMs in many critical domains (e.g., medical domain), where the hallucination is not tolerable. In this paper, we propose two model editing studies and validate them in the medical domain: (1) directly editing the factual medical knowledge and (2) editing the explanations to facts. Meanwhile, we observed that current model editing methods struggle with the specialization and complexity of medical knowledge. Therefore, we propose MedLaSA, a novel Layer-wise Scalable Adapter strategy for medical model editing. It employs causal tracing to identify the precise location of knowledge in neurons and then introduces scalable adapters into the dense layers of LLMs. These adapters are assigned scaling values based on the corresponding specific knowledge. To evaluate the editing impact, we build two benchmark datasets and introduce a series of challenging and comprehensive metrics. Extensive experiments on medical LLMs demonstrate the editing efficiency of MedLaSA, without affecting irrelevant knowledge that is not edited.
Biomedical Entity Linking as Multiple Choice Question Answering
Feb 23, 2024



Although biomedical entity linking (BioEL) has made significant progress with pre-trained language models, challenges still exist for fine-grained and long-tailed entities. To address these challenges, we present BioELQA, a novel model that treats Biomedical Entity Linking as Multiple Choice Question Answering. BioELQA first obtains candidate entities with a fast retriever, jointly presents the mention and candidate entities to a generator, and then outputs the predicted symbol associated with its chosen entity. This formulation enables explicit comparison of different candidate entities, thus capturing fine-grained interactions between mentions and entities, as well as among entities themselves. To improve generalization for long-tailed entities, we retrieve similar labeled training instances as clues and concatenate the input with retrieved instances for the generator. Extensive experimental results show that BioELQA outperforms state-of-the-art baselines on several datasets.
Improving Biomedical Entity Linking with Retrieval-enhanced Learning
Dec 15, 2023Biomedical entity linking (BioEL) has achieved remarkable progress with the help of pre-trained language models. However, existing BioEL methods usually struggle to handle rare and difficult entities due to long-tailed distribution. To address this limitation, we introduce a new scheme $k$NN-BioEL, which provides a BioEL model with the ability to reference similar instances from the entire training corpus as clues for prediction, thus improving the generalization capabilities. Moreover, we design a contrastive learning objective with dynamic hard negative sampling (DHNS) that improves the quality of the retrieved neighbors during inference. Extensive experimental results show that $k$NN-BioEL outperforms state-of-the-art baselines on several datasets.
Emerging Drug Interaction Prediction Enabled by Flow-based Graph Neural Network with Biomedical Network
Nov 15, 2023



Accurately predicting drug-drug interactions (DDI) for emerging drugs, which offer possibilities for treating and alleviating diseases, with computational methods can improve patient care and contribute to efficient drug development. However, many existing computational methods require large amounts of known DDI information, which is scarce for emerging drugs. In this paper, we propose EmerGNN, a graph neural network (GNN) that can effectively predict interactions for emerging drugs by leveraging the rich information in biomedical networks. EmerGNN learns pairwise representations of drugs by extracting the paths between drug pairs, propagating information from one drug to the other, and incorporating the relevant biomedical concepts on the paths. The different edges on the biomedical network are weighted to indicate the relevance for the target DDI prediction. Overall, EmerGNN has higher accuracy than existing approaches in predicting interactions for emerging drugs and can identify the most relevant information on the biomedical network.
Relation-aware Ensemble Learning for Knowledge Graph Embedding
Oct 13, 2023



Knowledge graph (KG) embedding is a fundamental task in natural language processing, and various methods have been proposed to explore semantic patterns in distinctive ways. In this paper, we propose to learn an ensemble by leveraging existing methods in a relation-aware manner. However, exploring these semantics using relation-aware ensemble leads to a much larger search space than general ensemble methods. To address this issue, we propose a divide-search-combine algorithm RelEns-DSC that searches the relation-wise ensemble weights independently. This algorithm has the same computation cost as general ensemble methods but with much better performance. Experimental results on benchmark datasets demonstrate the effectiveness of the proposed method in efficiently searching relation-aware ensemble weights and achieving state-of-the-art embedding performance. The code is public at https://github.com/LARS-research/RelEns.
Perturbation-based Self-supervised Attention for Attention Bias in Text Classification
May 25, 2023



In text classification, the traditional attention mechanisms usually focus too much on frequent words, and need extensive labeled data in order to learn. This paper proposes a perturbation-based self-supervised attention approach to guide attention learning without any annotation overhead. Specifically, we add as much noise as possible to all the words in the sentence without changing their semantics and predictions. We hypothesize that words that tolerate more noise are less significant, and we can use this information to refine the attention distribution. Experimental results on three text classification tasks show that our approach can significantly improve the performance of current attention-based models, and is more effective than existing self-supervised methods. We also provide a visualization analysis to verify the effectiveness of our approach.
Multi-modal Contrastive Representation Learning for Entity Alignment
Sep 02, 2022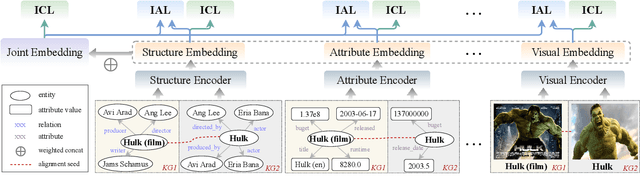
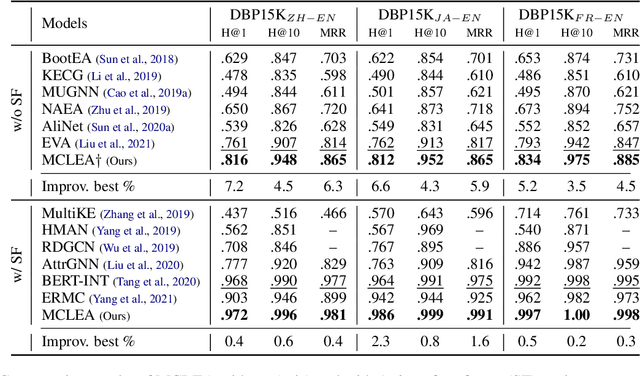
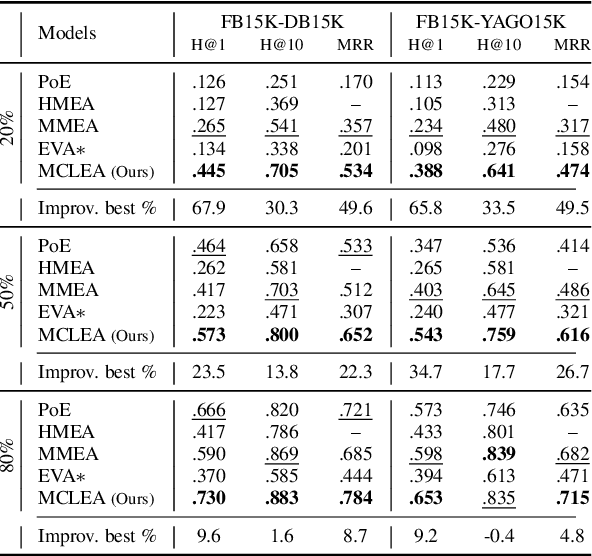
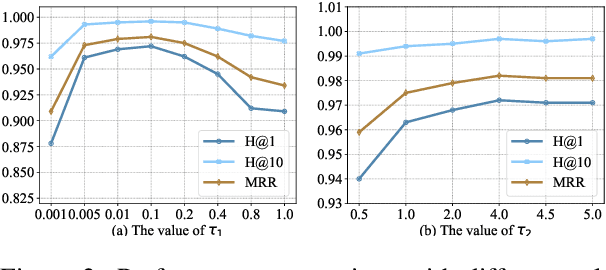
Multi-modal entity alignment aims to identify equivalent entities between two different multi-modal knowledge graphs, which consist of structural triples and images associated with entities. Most previous works focus on how to utilize and encode information from different modalities, while it is not trivial to leverage multi-modal knowledge in entity alignment because of the modality heterogeneity. In this paper, we propose MCLEA, a Multi-modal Contrastive Learning based Entity Alignment model, to obtain effective joint representations for multi-modal entity alignment. Different from previous works, MCLEA considers task-oriented modality and models the inter-modal relationships for each entity representation. In particular, MCLEA firstly learns multiple individual representations from multiple modalities, and then performs contrastive learning to jointly model intra-modal and inter-modal interactions. Extensive experimental results show that MCLEA outperforms state-of-the-art baselines on public datasets under both supervised and unsupervised settings.