 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Delay Differential Equations: System Reconstruction and Image Classification
Apr 11, 2023



Neural Ordinary Differential Equations (NODEs), a framework of continuous-depth neural networks, have been widely applied, showing exceptional efficacy in coping with representative datasets. Recently, an augmented framework has been developed to overcome some limitations that emerged in the application of the original framework. In this paper, we propose a new class of continuous-depth neural networks with delay, named Neural Delay Differential Equations (NDDEs). To compute the corresponding gradients, we use the adjoint sensitivity method to obtain the delayed dynamics of the adjoint. Differential equations with delays are typically seen as dynamical systems of infinite dimension that possess more fruitful dynamics. Compared to NODEs, NDDEs have a stronger capacity of nonlinear representations. We use several illustrative examples to demonstrate this outstanding capacity. Firstly, we successfully model the delayed dynamics where the trajectories in the lower-dimensional phase space could be mutually intersected and even chaotic in a model-free or model-based manner. Traditional NODEs, without any argumentation, are not directly applicable for such modeling. Secondly, we achieve lower loss and higher accuracy not only for the data produced synthetically by complex models but also for the CIFAR10, a well-known image dataset. Our results on the NDDEs demonstrate that appropriately articulating the elements of dynamical systems into the network design is truly beneficial in promoting network performance.
APAUNet: Axis Projection Attention UNet for Small Target in 3D Medical Segmentation
Oct 04, 2022
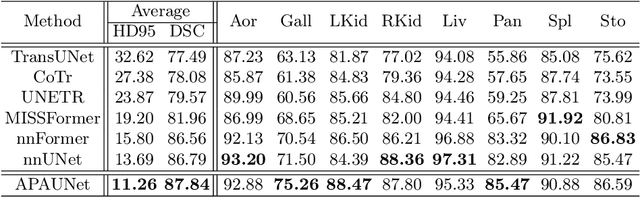
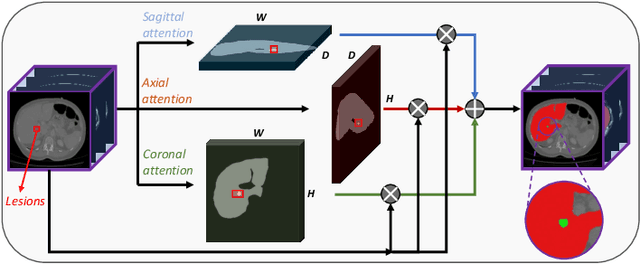
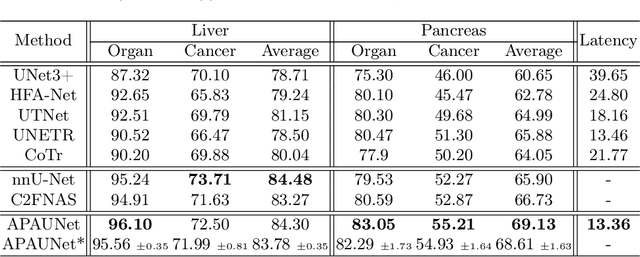
In 3D medical image segmentation, small targets segmentation is crucial for diagnosis but still faces challenges. In this paper, we propose the Axis Projection Attention UNet, named APAUNet, for 3D medical image segmentation, especially for small targets. Considering the large proportion of the background in the 3D feature space, we introduce a projection strategy to project the 3D features into three orthogonal 2D planes to capture the contextual attention from different views. In this way, we can filter out the redundant feature information and mitigate the loss of critical information for small lesions in 3D scans. Then we utilize a dimension hybridization strategy to fuse the 3D features with attention from different axes and merge them by a weighted summation to adaptively learn the importance of different perspectives. Finally, in the APA Decoder, we concatenate both high and low resolution features in the 2D projection process, thereby obtaining more precise multi-scale information, which is vital for small lesion segmentation. Quantitative and qualitative experimental results on two public datasets (BTCV and MSD) demonstrate that our proposed APAUNet outperforms the other methods. Concretely, our APAUNet achieves an average dice score of 87.84 on BTCV, 84.48 on MSD-Liver and 69.13 on MSD-Pancreas, and significantly surpass the previous SOTA methods on small targets.
Tackling Long-Tailed Category Distribution Under Domain Shifts
Jul 20, 2022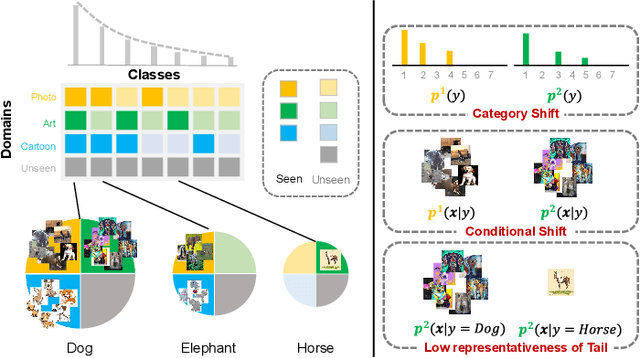
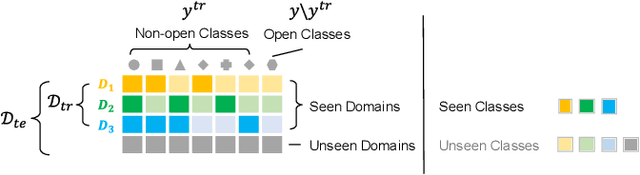
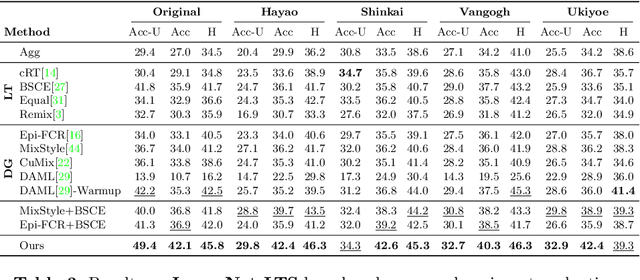
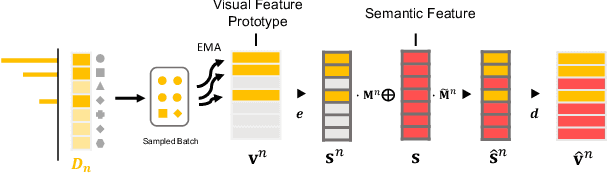
Machine learning models fail to perform well on real-world applications when 1) the category distribution P(Y) of the training dataset suffers from long-tailed distribution and 2) the test data is drawn from different conditional distributions P(X|Y). Existing approaches cannot handle the scenario where both issues exist, which however is common for real-world applications. In this study, we took a step forward and looked into the problem of long-tailed classification under domain shifts. We designed three novel core functional blocks including Distribution Calibrated Classification Loss, Visual-Semantic Mapping and Semantic-Similarity Guided Augmentation. Furthermore, we adopted a meta-learning framework which integrates these three blocks to improve domain generalization on unseen target domains. Two new datasets were proposed for this problem, named AWA2-LTS and ImageNet-LTS. We evaluated our method on the two datasets and extensive experimental results demonstrate that our proposed method can achieve superior performance over state-of-the-art long-tailed/domain generalization approaches and the combinations. Source codes and datasets can be found at our project page https://xiaogu.site/LTDS.
Toward Explainable and Fine-Grained 3D Grounding through Referring Textual Phrases
Jul 05, 2022
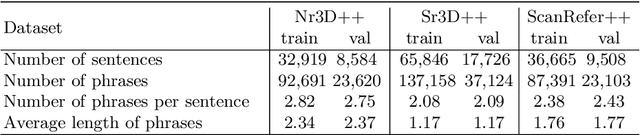
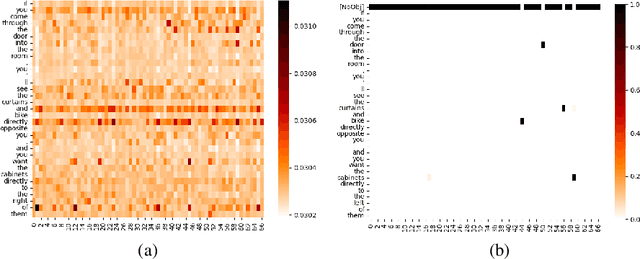
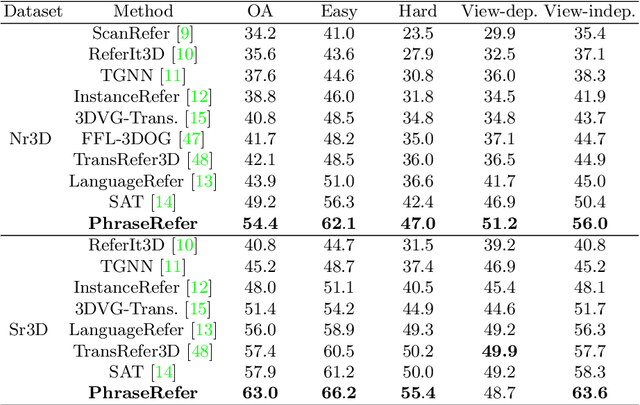
Recent progress on 3D scene understanding has explored visual grounding (3DVG) to localize a target object through a language description. However, existing methods only consider the dependency between the entire sentence and the target object, thus ignoring fine-grained relationships between contexts and non-target ones. In this paper, we extend 3DVG to a more reliable and explainable task, called 3D Phrase Aware Grounding (3DPAG). The 3DPAG task aims to localize the target object in the 3D scenes by explicitly identifying all phrase-related objects and then conducting reasoning according to contextual phrases. To tackle this problem, we label about 400K phrase-level annotations from 170K sentences in available 3DVG datasets, i.e., Nr3D, Sr3D and ScanRefer. By tapping on these developed datasets, we propose a novel framework, i.e., PhraseRefer, which conducts phrase-aware and object-level representation learning through phrase-object alignment optimization as well as phrase-specific pre-training. In our setting, we extend previous 3DVG methods to the phrase-aware scenario and provide metrics to measure the explainability of the 3DPAG task. Extensive results confirm that 3DPAG effectively boosts the 3DVG, and PhraseRefer achieves state-of-the-arts across three datasets, i.e., 63.0%, 54.4% and 55.5% overall accuracy on Sr3D, Nr3D and ScanRefer, respectively.
Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation
Apr 23, 2022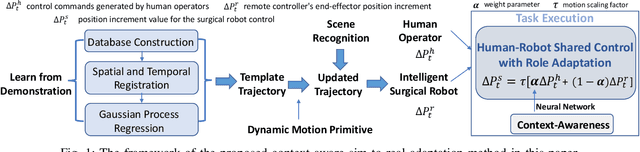
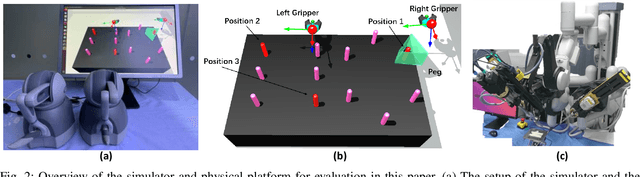
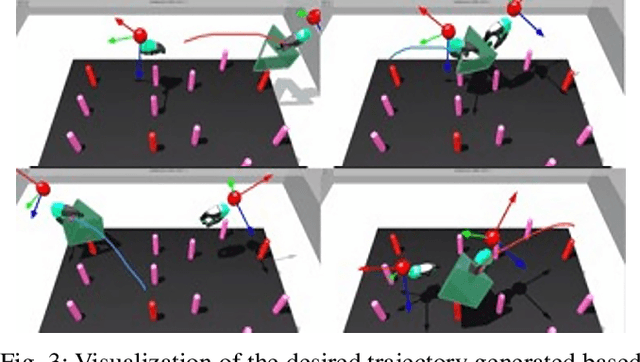
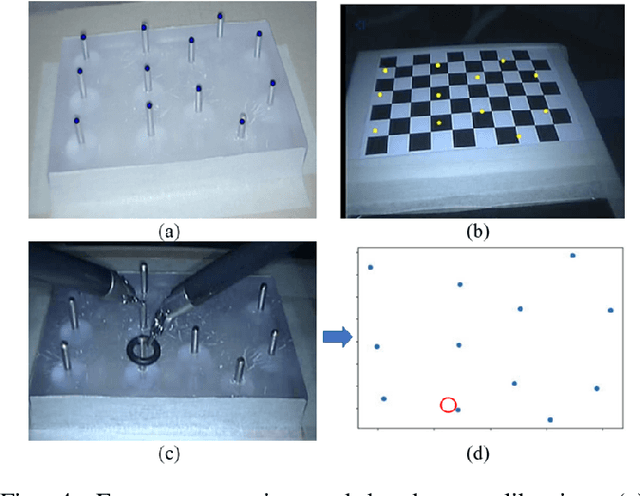
Human-robot shared control, which integrates the advantages of both humans and robots, is an effective approach to facilitate efficient surgical operation. Learning from demonstration (LfD) techniques can be used to automate some of the surgical subtasks for the construction of the shared control mechanism. However, a sufficient amount of data is required for the robot to learn the manoeuvres. Using a surgical simulator to collect data is a less resource-demanding approach. With sim-to-real adaptation, the manoeuvres learned from a simulator can be transferred to a physical robot. To this end, we propose a sim-to-real adaptation method to construct a human-robot shared control framework for robotic surgery. In this paper, a desired trajectory is generated from a simulator using LfD method, while dynamic motion primitives (DMP) is used to transfer the desired trajectory from the simulator to the physical robotic platform. Moreover, a role adaptation mechanism is developed such that the robot can adjust its role according to the surgical operation contexts predicted by a neural network model. The effectiveness of the proposed framework is validated on the da Vinci Research Kit (dVRK). Results of the user studies indicated that with the adaptive human-robot shared control framework, the path length of the remote controller, the total clutching number and the task completion time can be reduced significantly. The proposed method outperformed the traditional manual control via teleoperation.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Apr 06, 2022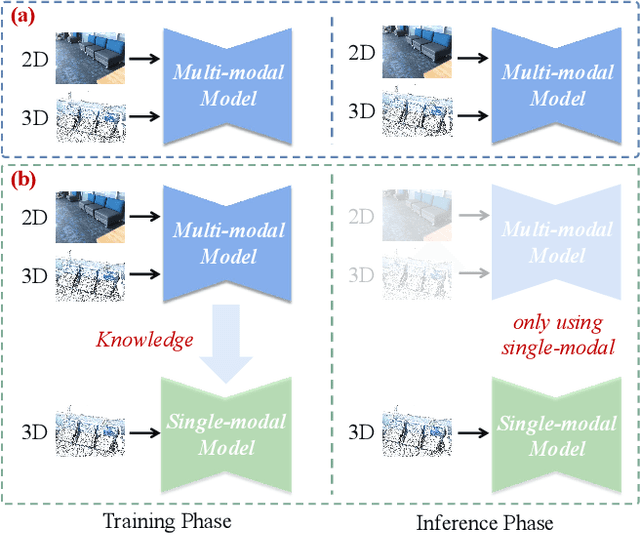
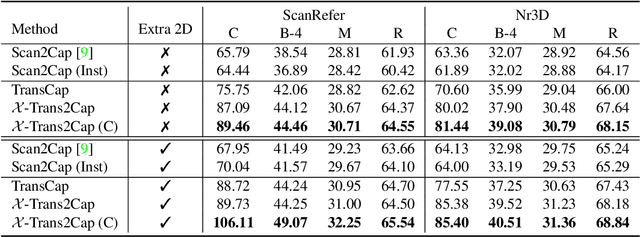
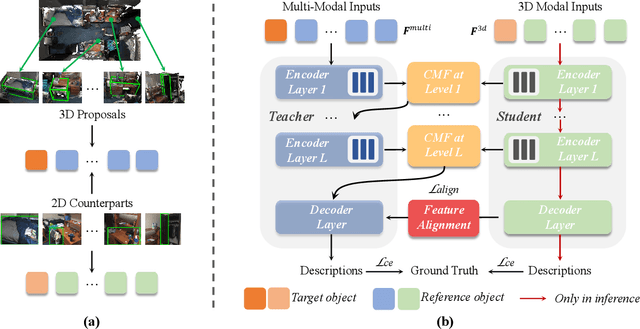

3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
CLEVR3D: Compositional Language and Elementary Visual Reasoning for Question Answering in 3D Real-World Scenes
Dec 31, 2021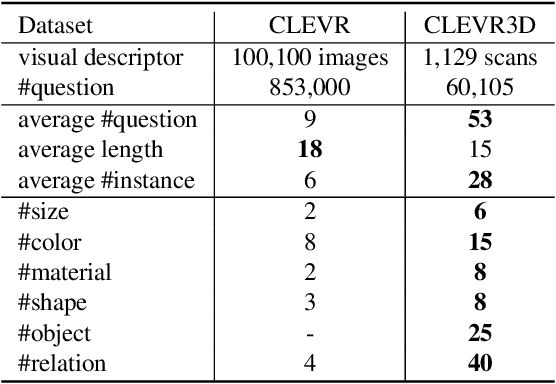
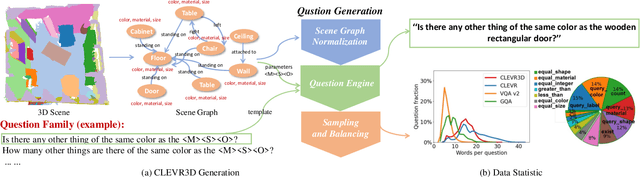
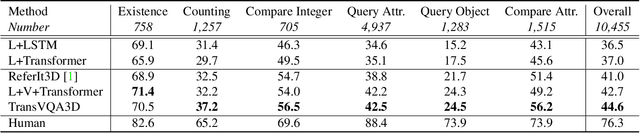
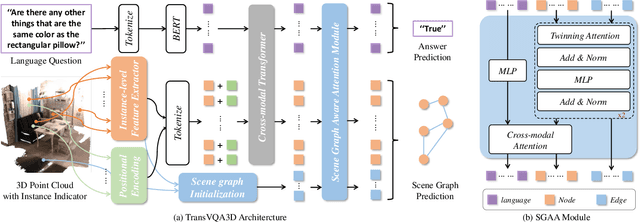
3D scene understanding is a relatively emerging research field. In this paper, we introduce the Visual Question Answering task in 3D real-world scenes (VQA-3D), which aims to answer all possible questions given a 3D scene. To tackle this problem, the first VQA-3D dataset, namely CLEVR3D, is proposed, which contains 60K questions in 1,129 real-world scenes. Specifically, we develop a question engine leveraging 3D scene graph structures to generate diverse reasoning questions, covering the questions of objects' attributes (i.e., size, color, and material) and their spatial relationships. Built upon this dataset, we further design the first VQA-3D baseline model, TransVQA3D. The TransVQA3D model adopts well-designed Transformer architectures to achieve superior VQA-3D performance, compared with the pure language baseline and previous 3D reasoning methods directly applied to 3D scenarios. Experimental results verify that taking VQA-3D as an auxiliary task can boost the performance of 3D scene understanding, including scene graph analysis for the node-wise classification and whole-graph recognition.
DistFL: Distribution-aware Federated Learning for Mobile Scenarios
Oct 22, 2021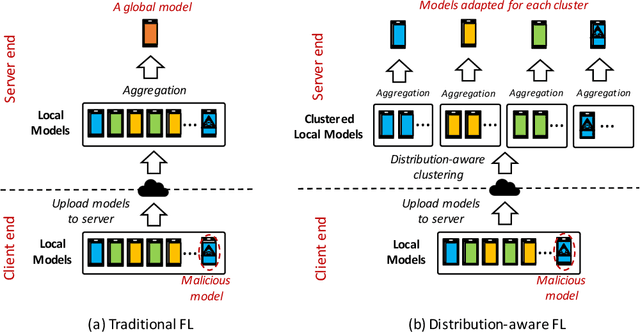
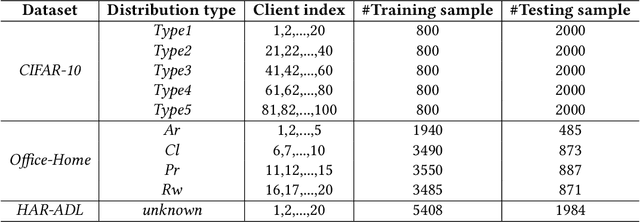
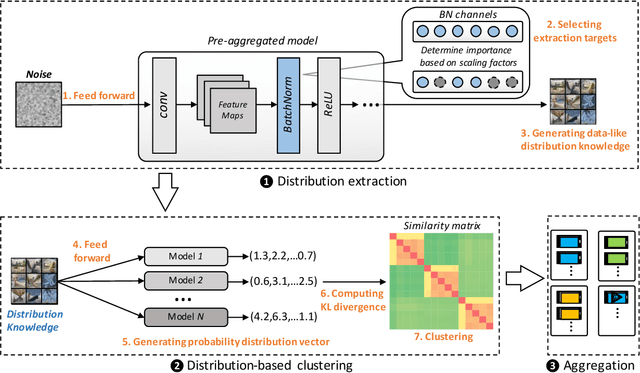
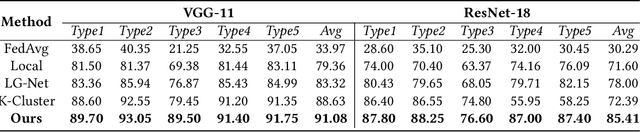
Federated learning (FL) has emerged as an effective solution to decentralized and privacy-preserving machine learning for mobile clients. While traditional FL has demonstrated its superiority, it ignores the non-iid (independently identically distributed) situation, which widely exists in mobile scenarios. Failing to handle non-iid situations could cause problems such as performance decreasing and possible attacks. Previous studies focus on the "symptoms" directly, as they try to improve the accuracy or detect possible attacks by adding extra steps to conventional FL models. However, previous techniques overlook the root causes for the "symptoms": blindly aggregating models with the non-iid distributions. In this paper, we try to fundamentally address the issue by decomposing the overall non-iid situation into several iid clusters and conducting aggregation in each cluster. Specifically, we propose \textbf{DistFL}, a novel framework to achieve automated and accurate \textbf{Dist}ribution-aware \textbf{F}ederated \textbf{L}earning in a cost-efficient way. DistFL achieves clustering via extracting and comparing the \textit{distribution knowledge} from the uploaded models. With this framework, we are able to generate multiple personalized models with distinctive distributions and assign them to the corresponding clients. Extensive experiments on mobile scenarios with popular model architectures have demonstrated the effectiveness of DistFL.
Occlusion-Invariant Rotation-Equivariant Semi-Supervised Depth Based Cross-View Gait Pose Estimation
Sep 03, 2021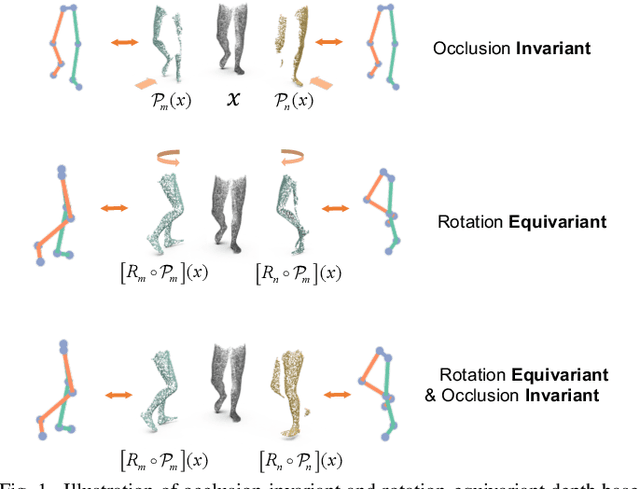
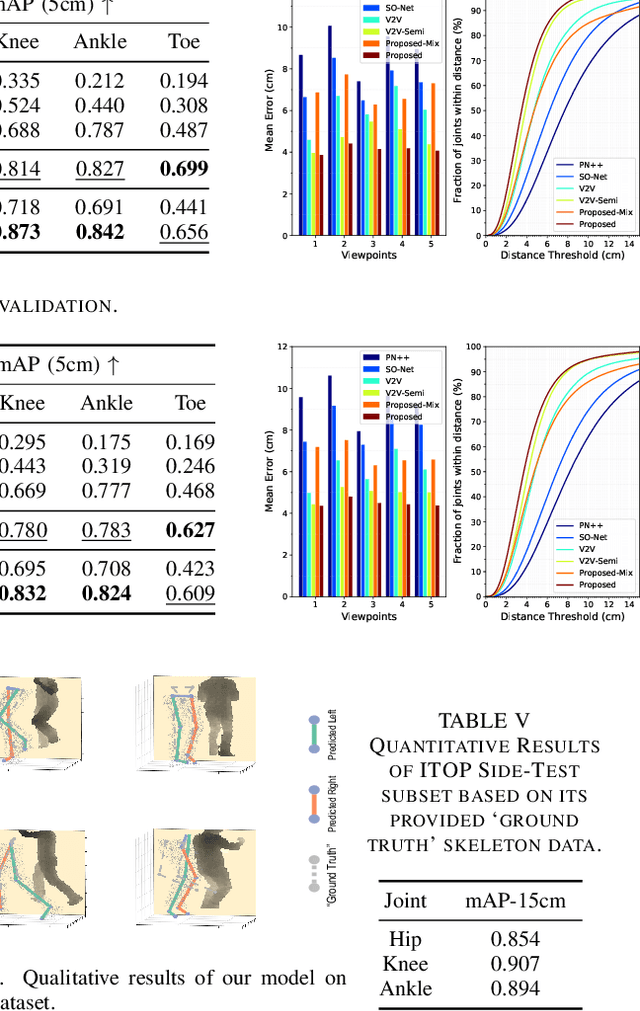
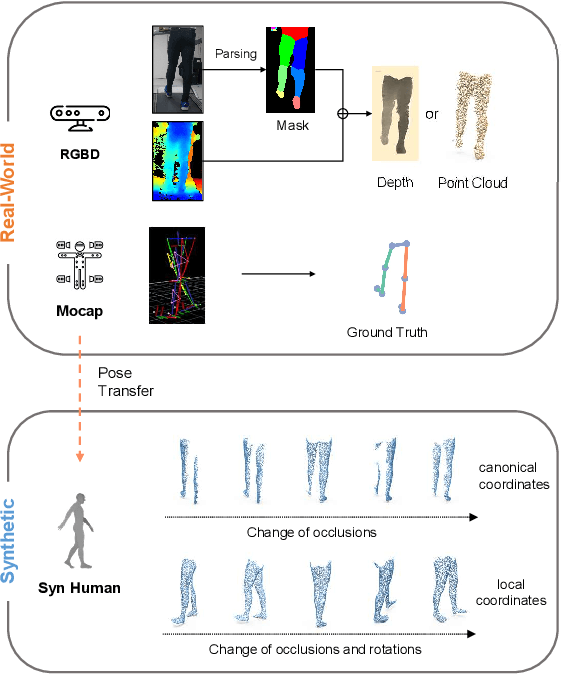
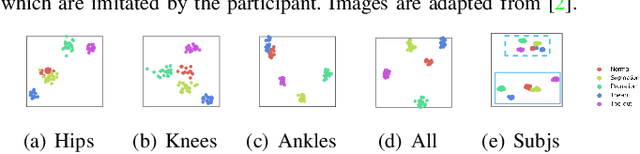
Accurate estimation of three-dimensional human skeletons from depth images can provide important metrics for healthcare applications, especially for biomechanical gait analysis. However, there exist inherent problems associated with depth images captured from a single view. The collected data is greatly affected by occlusions where only partial surface data can be recorded. Furthermore, depth images of human body exhibit heterogeneous characteristics with viewpoint changes, and the estimated poses under local coordinate systems are expected to go through equivariant rotations. Most existing pose estimation models are sensitive to both issues. To address this, we propose a novel approach for cross-view generalization with an occlusion-invariant semi-supervised learning framework built upon a novel rotation-equivariant backbone. Our model was trained with real-world data from a single view and unlabelled synthetic data from multiple views. It can generalize well on the real-world data from all the other unseen views. Our approach has shown superior performance on gait analysis on our ICL-Gait dataset compared to other state-of-the-arts and it can produce more convincing keypoints on ITOP dataset, than its provided "ground truth".
TransAction: ICL-SJTU Submission to EPIC-Kitchens Action Anticipation Challenge 2021
Jul 28, 2021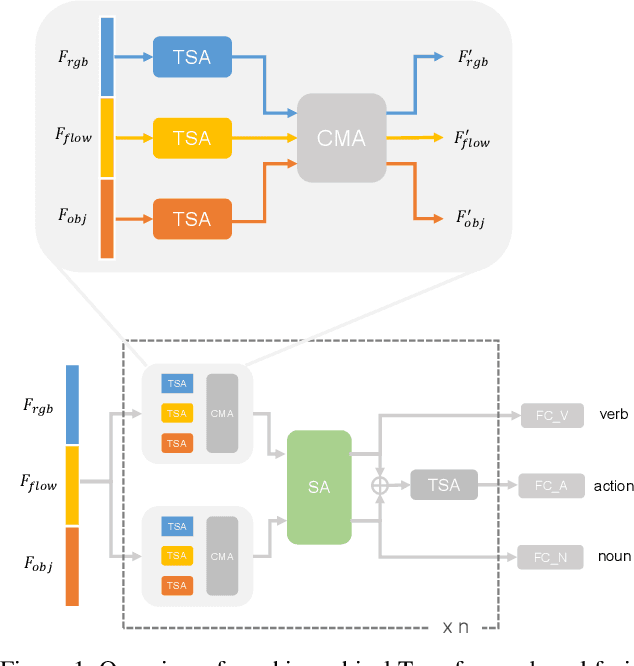
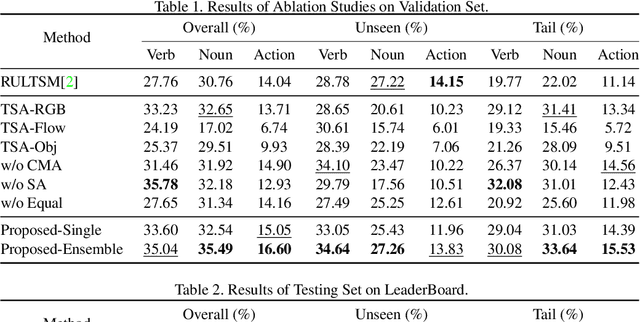
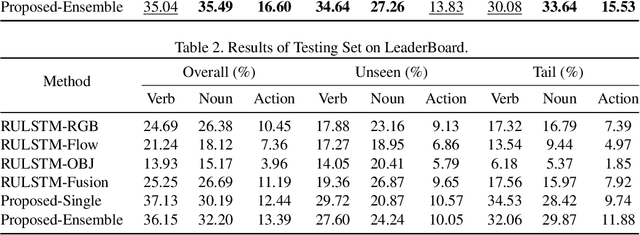
In this report, the technical details of our submission to the EPIC-Kitchens Action Anticipation Challenge 2021 are given. We developed a hierarchical attention model for action anticipation, which leverages Transformer-based attention mechanism to aggregate features across temporal dimension, modalities, symbiotic branches respectively. In terms of Mean Top-5 Recall of action, our submission with team name ICL-SJTU achieved 13.39% for overall testing set, 10.05% for unseen subsets and 11.88% for tailed subsets. Additionally, it is noteworthy that our submission ranked 1st in terms of verb class in all three (sub)sets.