 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training with Denoised Neural Weights
Jul 16, 2024



Good weight initialization serves as an effective measure to reduce the training cost of a deep neural network (DNN) model. The choice of how to initialize parameters is challenging and may require manual tuning, which can be time-consuming and prone to human error. To overcome such limitations, this work takes a novel step towards building a weight generator to synthesize the neural weights for initialization. We use the image-to-image translation task with generative adversarial networks (GANs) as an example due to the ease of collecting model weights spanning a wide range. Specifically, we first collect a dataset with various image editing concepts and their corresponding trained weights, which are later used for the training of the weight generator. To address the different characteristics among layers and the substantial number of weights to be predicted, we divide the weights into equal-sized blocks and assign each block an index. Subsequently, a diffusion model is trained with such a dataset using both text conditions of the concept and the block indexes. By initializing the image translation model with the denoised weights predicted by our diffusion model, the training requires only 43.3 seconds. Compared to training from scratch (i.e., Pix2pix), we achieve a 15x training time acceleration for a new concept while obtaining even better image generation quality.
BitsFusion: 1.99 bits Weight Quantization of Diffusion Model
Jun 06, 2024



Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size. Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to 1.99 bits, achieving a model with 7.9X smaller size while exhibiting even better generation quality than the original one. Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to dramatically reduce quantization error. Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.
SF-V: Single Forward Video Generation Model
Jun 06, 2024Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process. However, these models require multiple denoising steps during sampling, resulting in high computational costs. In this work, we propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-steps video diffusion model, i.e., Stable Video Diffusion (SVD), can be trained to perform single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data. Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around $23\times$ speedup compared with SVD and $6\times$ speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing. More visualization results are made publicly available at https://snap-research.github.io/SF-V.
TextCraftor: Your Text Encoder Can be Image Quality Controller
Mar 27, 2024



Diffusion-based text-to-image generative models, e.g., Stable Diffusion, have revolutionized the field of content generation, enabling significant advancements in areas like image editing and video synthesis. Despite their formidable capabilities, these models are not without their limitations. It is still challenging to synthesize an image that aligns well with the input text, and multiple runs with carefully crafted prompts are required to achieve satisfactory results. To mitigate these limitations, numerous studies have endeavored to fine-tune the pre-trained diffusion models, i.e., UNet, utilizing various technologies. Yet, amidst these efforts, a pivotal question of text-to-image diffusion model training has remained largely unexplored: Is it possible and feasible to fine-tune the text encoder to improve the performance of text-to-image diffusion models? Our findings reveal that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language models, we can enhance it through our proposed fine-tuning approach, TextCraftor, leading to substantial improvements in quantitative benchmarks and human assessments. Interestingly, our technique also empowers controllable image generation through the interpolation of different text encoders fine-tuned with various rewards. We also demonstrate that TextCraftor is orthogonal to UNet finetuning, and can be combined to further improve generative quality.
E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
Jan 11, 2024



One highly promising direction for enabling flexible real-time on-device image editing is utilizing data distillation by leveraging large-scale text-to-image diffusion models, such as Stable Diffusion, to generate paired datasets used for training generative adversarial networks (GANs). This approach notably alleviates the stringent requirements typically imposed by high-end commercial GPUs for performing image editing with diffusion models. However, unlike text-to-image diffusion models, each distilled GAN is specialized for a specific image editing task, necessitating costly training efforts to obtain models for various concepts. In this work, we introduce and address a novel research direction: can the process of distilling GANs from diffusion models be made significantly more efficient? To achieve this goal, we propose a series of innovative techniques. First, we construct a base GAN model with generalized features, adaptable to different concepts through fine-tuning, eliminating the need for training from scratch. Second, we identify crucial layers within the base GAN model and employ Low-Rank Adaptation (LoRA) with a simple yet effective rank search process, rather than fine-tuning the entire base model. Third, we investigate the minimal amount of data necessary for fine-tuning, further reducing the overall training time. Extensive experiments show that we can efficiently empower GANs with the ability to perform real-time high-quality image editing on mobile devices with remarkable reduced training cost and storage for each concept.
HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
Oct 12, 2023Despite significant advances in large-scale text-to-image models, achieving hyper-realistic human image generation remains a desirable yet unsolved task. Existing models like Stable Diffusion and DALL-E 2 tend to generate human images with incoherent parts or unnatural poses. To tackle these challenges, our key insight is that human image is inherently structural over multiple granularities, from the coarse-level body skeleton to fine-grained spatial geometry. Therefore, capturing such correlations between the explicit appearance and latent structure in one model is essential to generate coherent and natural human images. To this end, we propose a unified framework, HyperHuman, that generates in-the-wild human images of high realism and diverse layouts. Specifically, 1) we first build a large-scale human-centric dataset, named HumanVerse, which consists of 340M images with comprehensive annotations like human pose, depth, and surface normal. 2) Next, we propose a Latent Structural Diffusion Model that simultaneously denoises the depth and surface normal along with the synthesized RGB image. Our model enforces the joint learning of image appearance, spatial relationship, and geometry in a unified network, where each branch in the model complements to each other with both structural awareness and textural richness. 3) Finally, to further boost the visual quality, we propose a Structure-Guided Refiner to compose the predicted conditions for more detailed generation of higher resolution. Extensive experiments demonstrate that our framework yields the state-of-the-art performance, generating hyper-realistic human images under diverse scenarios. Project Page: https://snap-research.github.io/HyperHuman/
SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
Jun 03, 2023Text-to-image diffusion models can create stunning images from natural language descriptions that rival the work of professional artists and photographers. However, these models are large, with complex network architectures and tens of denoising iterations, making them computationally expensive and slow to run. As a result, high-end GPUs and cloud-based inference are required to run diffusion models at scale. This is costly and has privacy implications, especially when user data is sent to a third party. To overcome these challenges, we present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than $2$ seconds. We achieve so by introducing efficient network architecture and improving step distillation. Specifically, we propose an efficient UNet by identifying the redundancy of the original model and reducing the computation of the image decoder via data distillation. Further, we enhance the step distillation by exploring training strategies and introducing regularization from classifier-free guidance. Our extensive experiments on MS-COCO show that our model with $8$ denoising steps achieves better FID and CLIP scores than Stable Diffusion v$1.5$ with $50$ steps. Our work democratizes content creation by bringing powerful text-to-image diffusion models to the hands of users.
Rethinking Vision Transformers for MobileNet Size and Speed
Dec 15, 2022



With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose an improved supernet with low latency and high parameter efficiency. We further introduce a fine-grained joint search strategy that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve about $4\%$ higher top-1 accuracy than MobileNetV2 and MobileNetV2$\times1.4$ on ImageNet-1K with similar latency and parameters. We demonstrate that properly designed and optimized vision transformers can achieve high performance with MobileNet-level size and speed.
Layer Freezing & Data Sieving: Missing Pieces of a Generic Framework for Sparse Training
Sep 22, 2022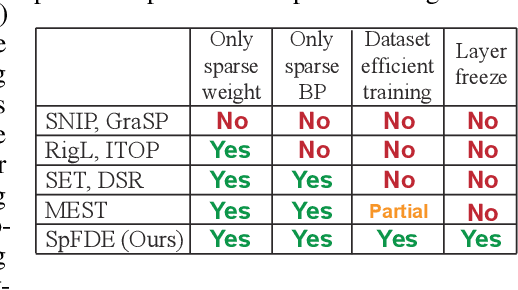
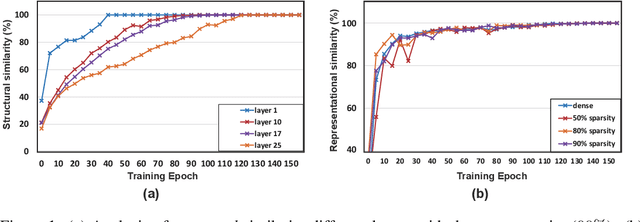
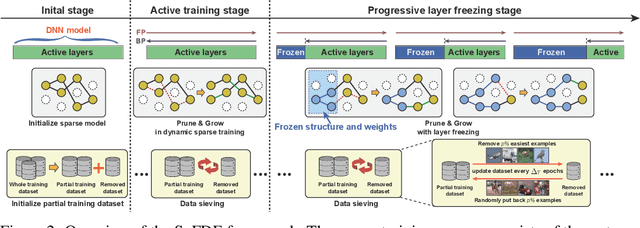
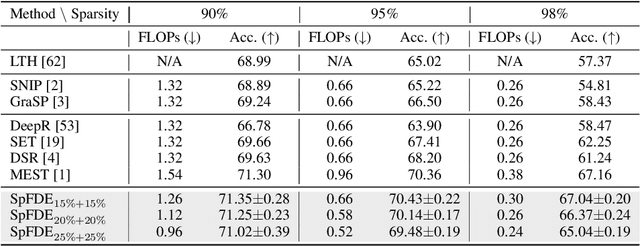
Recently, sparse training has emerged as a promising paradigm for efficient deep learning on edge devices. The current research mainly devotes efforts to reducing training costs by further increasing model sparsity. However, increasing sparsity is not always ideal since it will inevitably introduce severe accuracy degradation at an extremely high sparsity level. This paper intends to explore other possible directions to effectively and efficiently reduce sparse training costs while preserving accuracy. To this end, we investigate two techniques, namely, layer freezing and data sieving. First, the layer freezing approach has shown its success in dense model training and fine-tuning, yet it has never been adopted in the sparse training domain. Nevertheless, the unique characteristics of sparse training may hinder the incorporation of layer freezing techniques. Therefore, we analyze the feasibility and potentiality of using the layer freezing technique in sparse training and find it has the potential to save considerable training costs. Second, we propose a data sieving method for dataset-efficient training, which further reduces training costs by ensuring only a partial dataset is used throughout the entire training process. We show that both techniques can be well incorporated into the sparse training algorithm to form a generic framework, which we dub SpFDE. Our extensive experiments demonstrate that SpFDE can significantly reduce training costs while preserving accuracy from three dimensions: weight sparsity, layer freezing, and dataset sieving.
PIM-QAT: Neural Network Quantization for Processing-In-Memory (PIM) Systems
Sep 18, 2022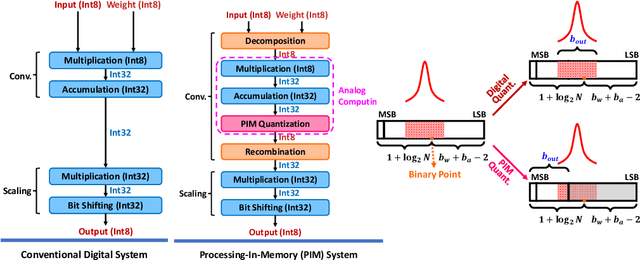

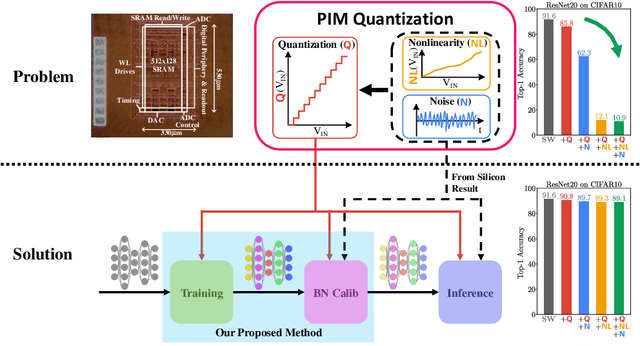

Processing-in-memory (PIM), an increasingly studied neuromorphic hardware, promises orders of energy and throughput improvements for deep learning inference. Leveraging the massively parallel and efficient analog computing inside memories, PIM circumvents the bottlenecks of data movements in conventional digital hardware. However, an extra quantization step (i.e. PIM quantization), typically with limited resolution due to hardware constraints, is required to convert the analog computing results into digital domain. Meanwhile, non-ideal effects extensively exist in PIM quantization because of the imperfect analog-to-digital interface, which further compromises the inference accuracy. In this paper, we propose a method for training quantized networks to incorporate PIM quantization, which is ubiquitous to all PIM systems. Specifically, we propose a PIM quantization aware training (PIM-QAT) algorithm, and introduce rescaling techniques during backward and forward propagation by analyzing the training dynamics to facilitate training convergence. We also propose two techniques, namely batch normalization (BN) calibration and adjusted precision training, to suppress the adverse effects of non-ideal linearity and stochastic thermal noise involved in real PIM chips. Our method is validated on three mainstream PIM decomposition schemes, and physically on a prototype chip. Comparing with directly deploying conventionally trained quantized model on PIM systems, which does not take into account this extra quantization step and thus fails, our method provides significant improvement. It also achieves comparable inference accuracy on PIM systems as that of conventionally quantized models on digital hardware, across CIFAR10 and CIFAR100 datasets using various network depths for the most popular network topology.