 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNote2Chat: Improving LLMs for Multi-Turn Clinical History Taking Using Medical Notes
Jan 29, 2026Effective clinical history taking is a foundational yet underexplored component of clinical reasoning. While large language models (LLMs) have shown promise on static benchmarks, they often fall short in dynamic, multi-turn diagnostic settings that require iterative questioning and hypothesis refinement. To address this gap, we propose \method{}, a note-driven framework that trains LLMs to conduct structured history taking and diagnosis by learning from widely available medical notes. Instead of relying on scarce and sensitive dialogue data, we convert real-world medical notes into high-quality doctor-patient dialogues using a decision tree-guided generation and refinement pipeline. We then propose a three-stage fine-tuning strategy combining supervised learning, simulated data augmentation, and preference learning. Furthermore, we propose a novel single-turn reasoning paradigm that reframes history taking as a sequence of single-turn reasoning problems. This design enhances interpretability and enables local supervision, dynamic adaptation, and greater sample efficiency. Experimental results show that our method substantially improves clinical reasoning, achieving gains of +16.9 F1 and +21.0 Top-1 diagnostic accuracy over GPT-4o. Our code and dataset can be found at https://github.com/zhentingsheng/Note2Chat.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Efficient Context Scaling with LongCat ZigZag Attention
Dec 30, 2025We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
CoVAR: Co-generation of Video and Action for Robotic Manipulation via Multi-Modal Diffusion
Dec 17, 2025We present a method to generate video-action pairs that follow text instructions, starting from an initial image observation and the robot's joint states. Our approach automatically provides action labels for video diffusion models, overcoming the common lack of action annotations and enabling their full use for robotic policy learning. Existing methods either adopt two-stage pipelines, which limit tightly coupled cross-modal information sharing, or rely on adapting a single-modal diffusion model for a joint distribution that cannot fully leverage pretrained video knowledge. To overcome these limitations, we (1) extend a pretrained video diffusion model with a parallel, dedicated action diffusion model that preserves pretrained knowledge, (2) introduce a Bridge Attention mechanism to enable effective cross-modal interaction, and (3) design an action refinement module to convert coarse actions into precise controls for low-resolution datasets. Extensive evaluations on multiple public benchmarks and real-world datasets demonstrate that our method generates higher-quality videos, more accurate actions, and significantly outperforms existing baselines, offering a scalable framework for leveraging large-scale video data for robotic learning.
DRAW2ACT: Turning Depth-Encoded Trajectories into Robotic Demonstration Videos
Dec 16, 2025Video diffusion models provide powerful real-world simulators for embodied AI but remain limited in controllability for robotic manipulation. Recent works on trajectory-conditioned video generation address this gap but often rely on 2D trajectories or single modality conditioning, which restricts their ability to produce controllable and consistent robotic demonstrations. We present DRAW2ACT, a depth-aware trajectory-conditioned video generation framework that extracts multiple orthogonal representations from the input trajectory, capturing depth, semantics, shape and motion, and injects them into the diffusion model. Moreover, we propose to jointly generate spatially aligned RGB and depth videos, leveraging cross-modality attention mechanisms and depth supervision to enhance the spatio-temporal consistency. Finally, we introduce a multimodal policy model conditioned on the generated RGB and depth sequences to regress the robot's joint angles. Experiments on Bridge V2, Berkeley Autolab, and simulation benchmarks show that DRAW2ACT achieves superior visual fidelity and consistency while yielding higher manipulation success rates compared to existing baselines.
Explore Data Left Behind in Reinforcement Learning for Reasoning Language Models
Nov 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for improving the reasoning abilities of large language models (LLMs). The Group Relative Policy Optimization (GRPO) family has demonstrated strong performance in training LLMs with RLVR. However, as models train longer and scale larger, more training prompts become residual prompts, those with zero variance rewards that provide no training signal. Consequently, fewer prompts contribute to training, reducing diversity and hindering effectiveness. To fully exploit these residual prompts, we propose the Explore Residual Prompts in Policy Optimization (ERPO) framework, which encourages exploration on residual prompts and reactivates their training signals. ERPO maintains a history tracker for each prompt and adaptively increases the sampling temperature for residual prompts that previously produced all correct responses. This encourages the model to generate more diverse reasoning traces, introducing incorrect responses that revive training signals. Empirical results on the Qwen2.5 series demonstrate that ERPO consistently surpasses strong baselines across multiple mathematical reasoning benchmarks.
A Survey on LLM Mid-training
Oct 27, 2025Recent advances in foundation models have highlighted the significant benefits of multi-stage training, with a particular emphasis on the emergence of mid-training as a vital stage that bridges pre-training and post-training. Mid-training is distinguished by its use of intermediate data and computational resources, systematically enhancing specified capabilities such as mathematics, coding, reasoning, and long-context extension, while maintaining foundational competencies. This survey provides a formal definition of mid-training for large language models (LLMs) and investigates optimization frameworks that encompass data curation, training strategies, and model architecture optimization. We analyze mainstream model implementations in the context of objective-driven interventions, illustrating how mid-training serves as a distinct and critical stage in the progressive development of LLM capabilities. By clarifying the unique contributions of mid-training, this survey offers a comprehensive taxonomy and actionable insights, supporting future research and innovation in the advancement of LLMs.
On Multiple Robustness of Proximal Dynamic Treatment Regimes
Oct 23, 2025



Dynamic treatment regimes are sequential decision rules that adapt treatment according to individual time-varying characteristics and outcomes to achieve optimal effects, with applications in precision medicine, personalized recommendations, and dynamic marketing. Estimating optimal dynamic treatment regimes via sequential randomized trials might face costly and ethical hurdles, often necessitating the use of historical observational data. In this work, we utilize proximal causal inference framework for learning optimal dynamic treatment regimes when the unconfoundedness assumption fails. Our contributions are four-fold: (i) we propose three nonparametric identification methods for optimal dynamic treatment regimes; (ii) we establish the semiparametric efficiency bound for the value function of a given regime; (iii) we propose a (K+1)-robust method for learning optimal dynamic treatment regimes, where K is the number of stages; (iv) as a by-product for marginal structural models, we establish identification and estimation of counterfactual means under a static regime. Numerical experiments validate the efficiency and multiple robustness of our proposed methods.
Making Mathematical Reasoning Adaptive
Oct 06, 2025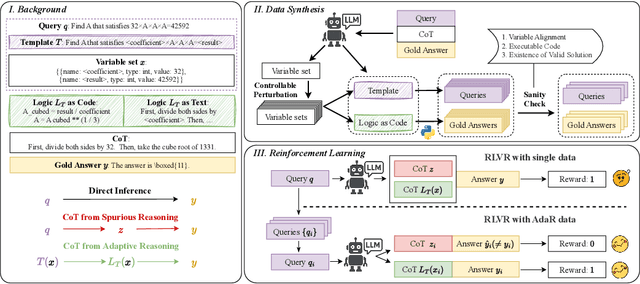
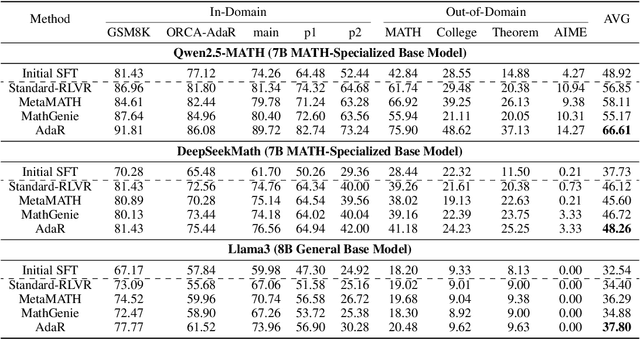


Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Fre-CW: Targeted Attack on Time Series Forecasting using Frequency Domain Loss
Aug 12, 2025Transformer-based models have made significant progress in time series forecasting. However, a key limitation of deep learning models is their susceptibility to adversarial attacks, which has not been studied enough in the context of time series prediction. In contrast to areas such as computer vision, where adversarial robustness has been extensively studied, frequency domain features of time series data play an important role in the prediction task but have not been sufficiently explored in terms of adversarial attacks. This paper proposes a time series prediction attack algorithm based on frequency domain loss. Specifically, we adapt an attack method originally designed for classification tasks to the prediction field and optimize the adversarial samples using both time-domain and frequency-domain losses. To the best of our knowledge, there is no relevant research on using frequency information for time-series adversarial attacks. Our experimental results show that these current time series prediction models are vulnerable to adversarial attacks, and our approach achieves excellent performance on major time series forecasting datasets.