 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multimodal Large Language Models Understand Spatial Relations?
May 25, 2025Spatial relation reasoning is a crucial task for multimodal large language models (MLLMs) to understand the objective world. However, current benchmarks have issues like relying on bounding boxes, ignoring perspective substitutions, or allowing questions to be answered using only the model's prior knowledge without image understanding. To address these issues, we introduce SpatialMQA, a human-annotated spatial relation reasoning benchmark based on COCO2017, which enables MLLMs to focus more on understanding images in the objective world. To ensure data quality, we design a well-tailored annotation procedure, resulting in SpatialMQA consisting of 5,392 samples. Based on this benchmark, a series of closed- and open-source MLLMs are implemented and the results indicate that the current state-of-the-art MLLM achieves only 48.14% accuracy, far below the human-level accuracy of 98.40%. Extensive experimental analyses are also conducted, suggesting the future research directions. The benchmark and codes are available at https://github.com/ziyan-xiaoyu/SpatialMQA.git.
LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
May 05, 2025



Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.
SARGes: Semantically Aligned Reliable Gesture Generation via Intent Chain
Mar 26, 2025



Co-speech gesture generation enhances human-computer interaction realism through speech-synchronized gesture synthesis. However, generating semantically meaningful gestures remains a challenging problem. We propose SARGes, a novel framework that leverages large language models (LLMs) to parse speech content and generate reliable semantic gesture labels, which subsequently guide the synthesis of meaningful co-speech gestures.First, we constructed a comprehensive co-speech gesture ethogram and developed an LLM-based intent chain reasoning mechanism that systematically parses and decomposes gesture semantics into structured inference steps following ethogram criteria, effectively guiding LLMs to generate context-aware gesture labels. Subsequently, we constructed an intent chain-annotated text-to-gesture label dataset and trained a lightweight gesture label generation model, which then guides the generation of credible and semantically coherent co-speech gestures. Experimental results demonstrate that SARGes achieves highly semantically-aligned gesture labeling (50.2% accuracy) with efficient single-pass inference (0.4 seconds). The proposed method provides an interpretable intent reasoning pathway for semantic gesture synthesis.
Accessing the Effect of Phyllotaxy and Planting Density on Light Use Efficiency in Field-Grown Maize using 3D Reconstructions
Mar 10, 2025



High-density planting is a widely adopted strategy to enhance maize productivity, yet it introduces challenges such as increased interplant competition and shading, which can limit light capture and overall yield potential. In response, some maize plants naturally reorient their canopies to optimize light capture, a process known as canopy reorientation. Understanding this adaptive response and its impact on light capture is crucial for maximizing agricultural yield potential. This study introduces an end-to-end framework that integrates realistic 3D reconstructions of field-grown maize with photosynthetically active radiation (PAR) modeling to assess the effects of phyllotaxy and planting density on light interception. In particular, using 3D point clouds derived from field data, virtual fields for a diverse set of maize genotypes were constructed and validated against field PAR measurements. Using this framework, we present detailed analyses of the impact of canopy orientations, plant and row spacings, and planting row directions on PAR interception throughout a typical growing season. Our findings highlight significant variations in light interception efficiency across different planting densities and canopy orientations. By elucidating the relationship between canopy architecture and light capture, this study offers valuable guidance for optimizing maize breeding and cultivation strategies across diverse agricultural settings.
ExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Mar 09, 2025



Audio-driven human gesture synthesis is a crucial task with broad applications in virtual avatars, human-computer interaction, and creative content generation. Despite notable progress, existing methods often produce gestures that are coarse, lack expressiveness, and fail to fully align with audio semantics. To address these challenges, we propose ExGes, a novel retrieval-enhanced diffusion framework with three key designs: (1) a Motion Base Construction, which builds a gesture library using training dataset; (2) a Motion Retrieval Module, employing constrative learning and momentum distillation for fine-grained reference poses retreiving; and (3) a Precision Control Module, integrating partial masking and stochastic masking to enable flexible and fine-grained control. Experimental evaluations on BEAT2 demonstrate that ExGes reduces Fr\'echet Gesture Distance by 6.2\% and improves motion diversity by 5.3\% over EMAGE, with user studies revealing a 71.3\% preference for its naturalness and semantic relevance. Code will be released upon acceptance.
BayLing 2: A Multilingual Large Language Model with Efficient Language Alignment
Nov 25, 2024



Large language models (LLMs), with their powerful generative capabilities and vast knowledge, empower various tasks in everyday life. However, these abilities are primarily concentrated in high-resource languages, leaving low-resource languages with weaker generative capabilities and relatively limited knowledge. Enhancing the multilingual capabilities of LLMs is therefore crucial for serving over 100 linguistic communities worldwide. An intuitive approach to enhance the multilingual capabilities would be to construct instruction data for various languages, but constructing instruction data for over 100 languages is prohibitively costly. In this paper, we introduce BayLing 2, which efficiently transfers generative capabilities and knowledge from high-resource languages to low-resource languages through language alignment. To achieve this, we constructed a dataset of 3.2 million instructions, comprising high-resource language instructions (Chinese and English) and cross-lingual instructions for 100+ languages and performed instruction tuning based on the dataset to facilitate the capability transfer between languages. Using Llama as the foundation model, we developed BayLing-2-7B, BayLing-2-13B, and BayLing-3-8B, and conducted a comprehensive evaluation of BayLing. For multilingual translation across 100+ languages, BayLing shows superior performance compared to open-source models of similar scale. For multilingual knowledge and understanding benchmarks, BayLing achieves significant improvements across over 20 low-resource languages, demonstrating its capability of effective knowledge transfer from high-resource to low-resource languages. Furthermore, results on English benchmarks indicate that BayLing maintains high performance in highresource languages while enhancing the performance in low-resource languages. Demo, homepage, code and models of BayLing are available.
MotionGPT-2: A General-Purpose Motion-Language Model for Motion Generation and Understanding
Oct 29, 2024



Generating lifelike human motions from descriptive texts has experienced remarkable research focus in the recent years, propelled by the emerging requirements of digital humans.Despite impressive advances, existing approaches are often constrained by limited control modalities, task specificity, and focus solely on body motion representations.In this paper, we present MotionGPT-2, a unified Large Motion-Language Model (LMLM) that addresses these limitations. MotionGPT-2 accommodates multiple motion-relevant tasks and supporting multimodal control conditions through pre-trained Large Language Models (LLMs). It quantizes multimodal inputs-such as text and single-frame poses-into discrete, LLM-interpretable tokens, seamlessly integrating them into the LLM's vocabulary. These tokens are then organized into unified prompts, guiding the LLM to generate motion outputs through a pretraining-then-finetuning paradigm. We also show that the proposed MotionGPT-2 is highly adaptable to the challenging 3D holistic motion generation task, enabled by the innovative motion discretization framework, Part-Aware VQVAE, which ensures fine-grained representations of body and hand movements. Extensive experiments and visualizations validate the effectiveness of our method, demonstrating the adaptability of MotionGPT-2 across motion generation, motion captioning, and generalized motion completion tasks.
Fast Graph Sharpness-Aware Minimization for Enhancing and Accelerating Few-Shot Node Classification
Oct 22, 2024



Graph Neural Networks (GNNs) have shown superior performance in node classification. However, GNNs perform poorly in the Few-Shot Node Classification (FSNC) task that requires robust generalization to make accurate predictions for unseen classes with limited labels. To tackle the challenge, we propose the integration of Sharpness-Aware Minimization (SAM)--a technique designed to enhance model generalization by finding a flat minimum of the loss landscape--into GNN training. The standard SAM approach, however, consists of two forward-backward steps in each training iteration, doubling the computational cost compared to the base optimizer (e.g., Adam). To mitigate this drawback, we introduce a novel algorithm, Fast Graph Sharpness-Aware Minimization (FGSAM), that integrates the rapid training of Multi-Layer Perceptrons (MLPs) with the superior performance of GNNs. Specifically, we utilize GNNs for parameter perturbation while employing MLPs to minimize the perturbed loss so that we can find a flat minimum with good generalization more efficiently. Moreover, our method reutilizes the gradient from the perturbation phase to incorporate graph topology into the minimization process at almost zero additional cost. To further enhance training efficiency, we develop FGSAM+ that executes exact perturbations periodically. Extensive experiments demonstrate that our proposed algorithm outperforms the standard SAM with lower computational costs in FSNC tasks. In particular, our FGSAM+ as a SAM variant offers a faster optimization than the base optimizer in most cases. In addition to FSNC, our proposed methods also demonstrate competitive performance in the standard node classification task for heterophilic graphs, highlighting the broad applicability. The code is available at https://github.com/draym28/FGSAM_NeurIPS24.
LTPNet Integration of Deep Learning and Environmental Decision Support Systems for Renewable Energy Demand Forecasting
Oct 20, 2024



Against the backdrop of increasingly severe global environmental changes, accurately predicting and meeting renewable energy demands has become a key challenge for sustainable business development. Traditional energy demand forecasting methods often struggle with complex data processing and low prediction accuracy. To address these issues, this paper introduces a novel approach that combines deep learning techniques with environmental decision support systems. The model integrates advanced deep learning techniques, including LSTM and Transformer, and PSO algorithm for parameter optimization, significantly enhancing predictive performance and practical applicability. Results show that our model achieves substantial improvements across various metrics, including a 30% reduction in MAE, a 20% decrease in MAPE, a 25% drop in RMSE, and a 35% decline in MSE. These results validate the model's effectiveness and reliability in renewable energy demand forecasting. This research provides valuable insights for applying deep learning in environmental decision support systems.
Holistic Automated Red Teaming for Large Language Models through Top-Down Test Case Generation and Multi-turn Interaction
Sep 25, 2024
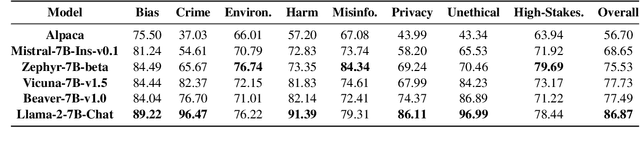
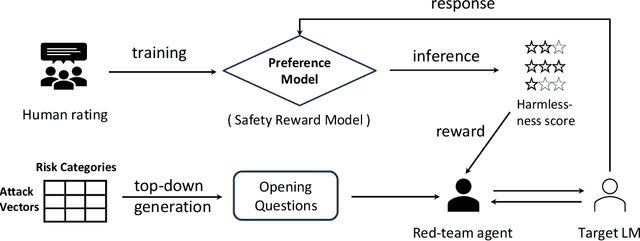
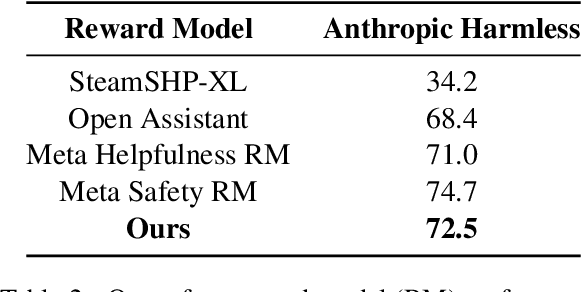
Automated red teaming is an effective method for identifying misaligned behaviors in large language models (LLMs). Existing approaches, however, often focus primarily on improving attack success rates while overlooking the need for comprehensive test case coverage. Additionally, most of these methods are limited to single-turn red teaming, failing to capture the multi-turn dynamics of real-world human-machine interactions. To overcome these limitations, we propose HARM (Holistic Automated Red teaMing), which scales up the diversity of test cases using a top-down approach based on an extensible, fine-grained risk taxonomy. Our method also leverages a novel fine-tuning strategy and reinforcement learning techniques to facilitate multi-turn adversarial probing in a human-like manner. Experimental results demonstrate that our framework enables a more systematic understanding of model vulnerabilities and offers more targeted guidance for the alignment process.