 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Mar 09, 2025



Audio-driven human gesture synthesis is a crucial task with broad applications in virtual avatars, human-computer interaction, and creative content generation. Despite notable progress, existing methods often produce gestures that are coarse, lack expressiveness, and fail to fully align with audio semantics. To address these challenges, we propose ExGes, a novel retrieval-enhanced diffusion framework with three key designs: (1) a Motion Base Construction, which builds a gesture library using training dataset; (2) a Motion Retrieval Module, employing constrative learning and momentum distillation for fine-grained reference poses retreiving; and (3) a Precision Control Module, integrating partial masking and stochastic masking to enable flexible and fine-grained control. Experimental evaluations on BEAT2 demonstrate that ExGes reduces Fr\'echet Gesture Distance by 6.2\% and improves motion diversity by 5.3\% over EMAGE, with user studies revealing a 71.3\% preference for its naturalness and semantic relevance. Code will be released upon acceptance.
VGG-Tex: A Vivid Geometry-Guided Facial Texture Estimation Model for High Fidelity Monocular 3D Face Reconstruction
Sep 17, 2024



3D face reconstruction from monocular images has promoted the development of various applications such as augmented reality. Though existing methods have made remarkable progress, most of them emphasize geometric reconstruction, while overlooking the importance of texture prediction. To address this issue, we propose VGG-Tex, a novel Vivid Geometry-Guided Facial Texture Estimation model designed for High Fidelity Monocular 3D Face Reconstruction. The core of this approach is leveraging 3D parametric priors to enhance the outcomes of 2D UV texture estimation. Specifically, VGG-Tex includes a Facial Attributes Encoding Module, a Geometry-Guided Texture Generator, and a Visibility-Enhanced Texture Completion Module. These components are responsible for extracting parametric priors, generating initial textures, and refining texture details, respectively. Based on the geometry-texture complementarity principle, VGG-Tex also introduces a Texture-guided Geometry Refinement Module to further balance the overall fidelity of the reconstructed 3D faces, along with corresponding losses. Comprehensive experiments demonstrate that our method significantly improves texture reconstruction performance compared to existing state-of-the-art methods.
Meta-Learning Empowered Meta-Face: Personalized Speaking Style Adaptation for Audio-Driven 3D Talking Face Animation
Aug 18, 2024



Audio-driven 3D face animation is increasingly vital in live streaming and augmented reality applications. While remarkable progress has been observed, most existing approaches are designed for specific individuals with predefined speaking styles, thus neglecting the adaptability to varied speaking styles. To address this limitation, this paper introduces MetaFace, a novel methodology meticulously crafted for speaking style adaptation. Grounded in the novel concept of meta-learning, MetaFace is composed of several key components: the Robust Meta Initialization Stage (RMIS) for fundamental speaking style adaptation, the Dynamic Relation Mining Neural Process (DRMN) for forging connections between observed and unobserved speaking styles, and the Low-rank Matrix Memory Reduction Approach to enhance the efficiency of model optimization as well as learning style details. Leveraging these novel designs, MetaFace not only significantly outperforms robust existing baselines but also establishes a new state-of-the-art, as substantiated by our experimental results.
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
Oct 16, 2023



Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance.
STDG: Semi-Teacher-Student Training Paradigram for Depth-guided One-stage Scene Graph Generation
Sep 15, 2023



Scene Graph Generation is a critical enabler of environmental comprehension for autonomous robotic systems. Most of existing methods, however, are often thwarted by the intricate dynamics of background complexity, which limits their ability to fully decode the inherent topological information of the environment. Additionally, the wealth of contextual information encapsulated within depth cues is often left untapped, rendering existing approaches less effective. To address these shortcomings, we present STDG, an avant-garde Depth-Guided One-Stage Scene Graph Generation methodology. The innovative architecture of STDG is a triad of custom-built modules: The Depth Guided HHA Representation Generation Module, the Depth Guided Semi-Teaching Network Learning Module, and the Depth Guided Scene Graph Generation Module. This trifecta of modules synergistically harnesses depth information, covering all aspects from depth signal generation and depth feature utilization, to the final scene graph prediction. Importantly, this is achieved without imposing additional computational burden during the inference phase. Experimental results confirm that our method significantly enhances the performance of one-stage scene graph generation baselines.
Backdoor Attacks with Input-unique Triggers in NLP
Mar 25, 2023

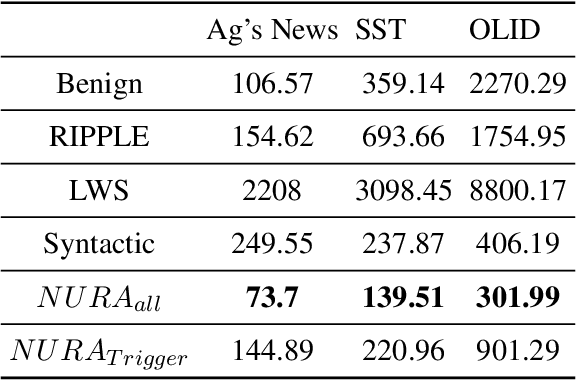

Backdoor attack aims at inducing neural models to make incorrect predictions for poison data while keeping predictions on the clean dataset unchanged, which creates a considerable threat to current natural language processing (NLP) systems. Existing backdoor attacking systems face two severe issues:firstly, most backdoor triggers follow a uniform and usually input-independent pattern, e.g., insertion of specific trigger words, synonym replacement. This significantly hinders the stealthiness of the attacking model, leading the trained backdoor model being easily identified as malicious by model probes. Secondly, trigger-inserted poisoned sentences are usually disfluent, ungrammatical, or even change the semantic meaning from the original sentence, making them being easily filtered in the pre-processing stage. To resolve these two issues, in this paper, we propose an input-unique backdoor attack(NURA), where we generate backdoor triggers unique to inputs. IDBA generates context-related triggers by continuing writing the input with a language model like GPT2. The generated sentence is used as the backdoor trigger. This strategy not only creates input-unique backdoor triggers, but also preserves the semantics of the original input, simultaneously resolving the two issues above. Experimental results show that the IDBA attack is effective for attack and difficult to defend: it achieves high attack success rate across all the widely applied benchmarks, while is immune to existing defending methods. In addition, it is able to generate fluent, grammatical, and diverse backdoor inputs, which can hardly be recognized through human inspection.