 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAFD: Multimodal Federated Learning via Adversarial Fusion and Distillation
Mar 05, 2026Multimodal Federated Learning (MFL) enables clients with heterogeneous data modalities to collaboratively train models without sharing raw data, offering a privacy-preserving framework that leverages complementary cross-modal information. However, existing methods often overlook personalized client performance and struggle with modality/task discrepancies, as well as model heterogeneity. To address these challenges, we propose FedAFD, a unified MFL framework that enhances client and server learning. On the client side, we introduce a bi-level adversarial alignment strategy to align local and global representations within and across modalities, mitigating modality and task gaps. We further design a granularity-aware fusion module to integrate global knowledge into the personalized features adaptively. On the server side, to handle model heterogeneity, we propose a similarity-guided ensemble distillation mechanism that aggregates client representations on shared public data based on feature similarity and distills the fused knowledge into the global model. Extensive experiments conducted under both IID and non-IID settings demonstrate that FedAFD achieves superior performance and efficiency for both the client and the server.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025

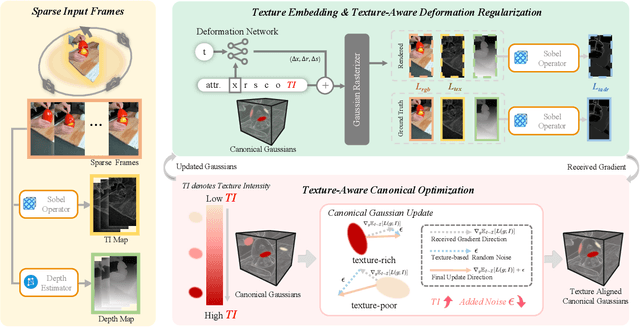
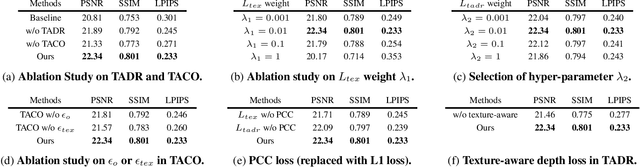
Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.
Growing a Twig to Accelerate Large Vision-Language Models
Mar 18, 2025



Large vision-language models (VLMs) have demonstrated remarkable capabilities in open-world multimodal understanding, yet their high computational overheads pose great challenges for practical deployment. Some recent works have proposed methods to accelerate VLMs by pruning redundant visual tokens guided by the attention maps of VLM's early layers. Despite the success of these token pruning methods, they still suffer from two major shortcomings: (i) considerable accuracy drop due to insensitive attention signals in early layers, and (ii) limited speedup when generating long responses (e.g., 30 tokens). To address the limitations above, we present TwigVLM -- a simple and general architecture by growing a lightweight twig upon an early layer of the base VLM. Compared with most existing VLM acceleration methods purely based on visual token pruning, our TwigVLM not only achieves better accuracy retention by employing a twig-guided token pruning (TTP) strategy, but also yields higher generation speed by utilizing a self-speculative decoding (SSD) strategy. Taking LLaVA-1.5-7B as the base VLM, experimental results show that TwigVLM preserves 96% of the original performance after pruning 88.9% of visual tokens and achieves 154% speedup in generating long responses, delivering significantly better performance in terms of both accuracy and speed over the state-of-the-art VLM acceleration methods. Code will be made publicly available.