 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeblurNVS: Geometric Latent Diffusion for Novel View Synthesis from Sparse Motion-Blurred Images
May 31, 2026Novel view synthesis (NVS) is a fundamental problem in computer vision and graphics. Recent advances in neural radiance fields (NeRF), 3D Gaussian Splatting (3DGS), and generative view synthesis have substantially improved its quality. Yet most methods still rely on clean observations, where image structures and cross-view geometric cues are well preserved. Motion blur breaks this assumption by corrupting local details and weakening multi-view correspondences. Such blur commonly arises from camera shake, scene motion, or finite exposure in practical capture. Blur-aware NVS methods address this degradation by modeling image formation, but their reliance on costly per-scene optimization limits efficient and generalizable sparse-view synthesis. To address this, we propose DeblurNVS, a novel framework for synthesizing high-fidelity novel views directly from sparse motion-blurred images, without requiring per-scene optimization. DeblurNVS restores the intermediate geometric representations needed for multi-view reasoning, enabling blurred inputs to recover reliable structure and correspondence cues. The restored representations are then combined with target camera information to synthesize the target-view representation and reconstruct a sharp RGB novel view. To enable the large-scale training, we construct a motion-blurred NVS dataset from DL3DV-10K using interpolation-based finite-exposure blur synthesis. Extensive experiments demonstrate that DeblurNVS outperforms existing baselines on synthetic motion-blur benchmarks and generalizes to real motion-blurred scenes, producing perceptually sharper and structurally more stable novel views while avoiding costly per-scene optimization. Project page: https://github.com/PKU-YuanGroup/DeblurNVS.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
GenSmoke-GS: A Multi-Stage Method for Novel View Synthesis from Smoke-Degraded Images Using a Generative Model
Apr 03, 2026This paper describes our method for Track 2 of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge on smoke-degraded images. In this task, smoke reduces image visibility and weakens the cross-view consistency required by scene optimization and rendering. We address this problem with a multi-stage pipeline consisting of image restoration, dehazing, MLLM-based enhancement, 3DGS-MCMC optimization, and averaging over repeated runs. The main purpose of the pipeline is to improve visibility before rendering while limiting scene-content changes across input views. Experimental results on the challenge benchmark show improved quantitative performance and better visual quality than the provided baselines. The code is available at https://github.com/plbbl/GenSmoke-GS. Our method achieved a ranking of 1 out of 14 participants in Track 2 of the NTIRE 3DRR Challenge, as reported on the official competition website: https://www.codabench.org/competitions/13993/#/results-tab.
SRSplat: Feed-Forward Super-Resolution Gaussian Splatting from Sparse Multi-View Images
Nov 15, 2025Feed-forward 3D reconstruction from sparse, low-resolution (LR) images is a crucial capability for real-world applications, such as autonomous driving and embodied AI. However, existing methods often fail to recover fine texture details. This limitation stems from the inherent lack of high-frequency information in LR inputs. To address this, we propose \textbf{SRSplat}, a feed-forward framework that reconstructs high-resolution 3D scenes from only a few LR views. Our main insight is to compensate for the deficiency of texture information by jointly leveraging external high-quality reference images and internal texture cues. We first construct a scene-specific reference gallery, generated for each scene using Multimodal Large Language Models (MLLMs) and diffusion models. To integrate this external information, we introduce the \textit{Reference-Guided Feature Enhancement (RGFE)} module, which aligns and fuses features from the LR input images and their reference twin image. Subsequently, we train a decoder to predict the Gaussian primitives using the multi-view fused feature obtained from \textit{RGFE}. To further refine predicted Gaussian primitives, we introduce \textit{Texture-Aware Density Control (TADC)}, which adaptively adjusts Gaussian density based on the internal texture richness of the LR inputs. Extensive experiments demonstrate that our SRSplat outperforms existing methods on various datasets, including RealEstate10K, ACID, and DTU, and exhibits strong cross-dataset and cross-resolution generalization capabilities.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025

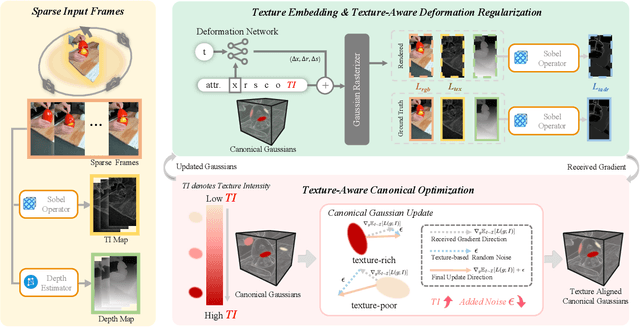
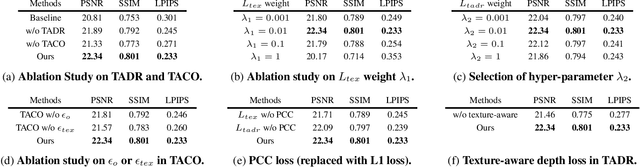
Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.