 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordination for Connected and Automated Vehicles at Non-signalized Intersections: A Value Decomposition-based Multiagent Deep Reinforcement Learning Approach
Nov 16, 2022



The recent proliferation of the research on multi-agent deep reinforcement learning (MDRL) offers an encouraging way to coordinate multiple connected and automated vehicles (CAVs) to pass the intersection. In this paper, we apply a value decomposition-based MDRL approach (QMIX) to control various CAVs in mixed-autonomy traffic of different densities to efficiently and safely pass the non-signalized intersection with fairish fuel consumption. Implementation tricks including network-level improvements, Q value update by TD ($\lambda$), and reward clipping operation are added to the pure QMIX framework, which is expected to improve the convergence speed and the asymptotic performance of the original version. The efficacy of our approach is demonstrated by several evaluation metrics: average speed, the number of collisions, and average fuel consumption per episode. The experimental results show that our approach's convergence speed and asymptotic performance can exceed that of the original QMIX and the proximal policy optimization (PPO), a state-of-the-art reinforcement learning baseline applied to the non-signalized intersection. Moreover, CAVs under the lower traffic flow controlled by our method can improve their average speed without collisions and consume the least fuel. The training is additionally conducted under the doubled traffic density, where the learning reward converges. Consequently, the model with maximal reward and minimum crashes can still guarantee low fuel consumption, but slightly reduce the efficiency of vehicles and induce more collisions than the lower-traffic counterpart, implying the difficulty of generalizing RL policy to more advanced scenarios.
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Oct 26, 2022



Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone-racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. We believe this work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
A Pareto-optimal compositional energy-based model for sampling and optimization of protein sequences
Oct 19, 2022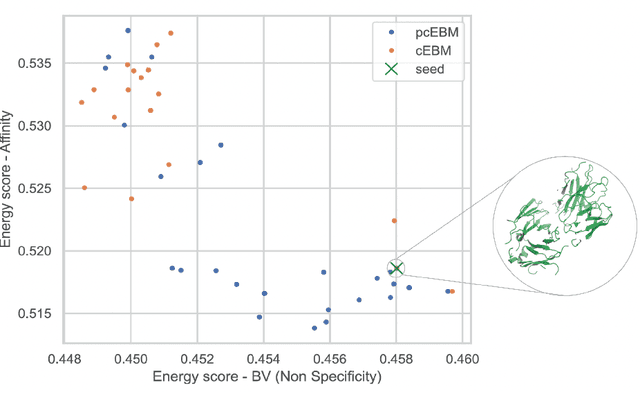
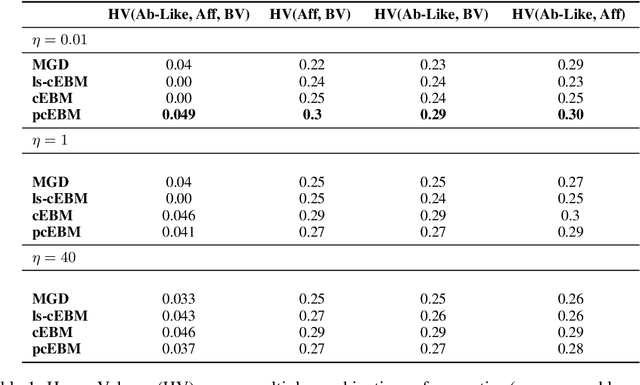
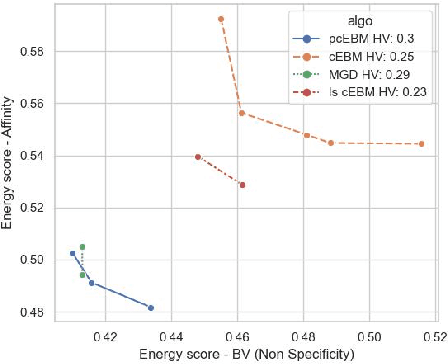
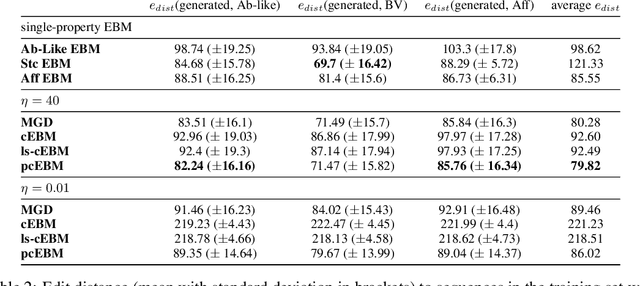
Deep generative models have emerged as a popular machine learning-based approach for inverse design problems in the life sciences. However, these problems often require sampling new designs that satisfy multiple properties of interest in addition to learning the data distribution. This multi-objective optimization becomes more challenging when properties are independent or orthogonal to each other. In this work, we propose a Pareto-compositional energy-based model (pcEBM), a framework that uses multiple gradient descent for sampling new designs that adhere to various constraints in optimizing distinct properties. We demonstrate its ability to learn non-convex Pareto fronts and generate sequences that simultaneously satisfy multiple desired properties across a series of real-world antibody design tasks.
Multi-frequency PolSAR Image Fusion Classification Based on Semantic Interactive Information and Topological Structure
Sep 05, 2022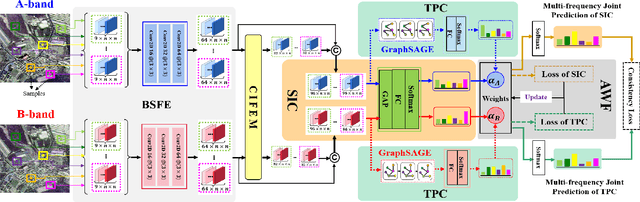
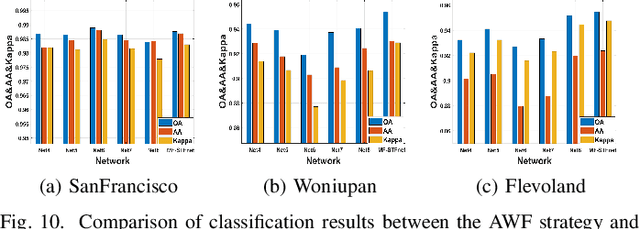
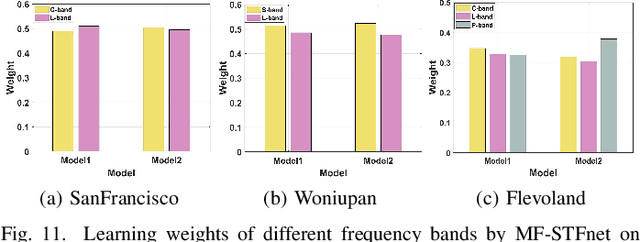
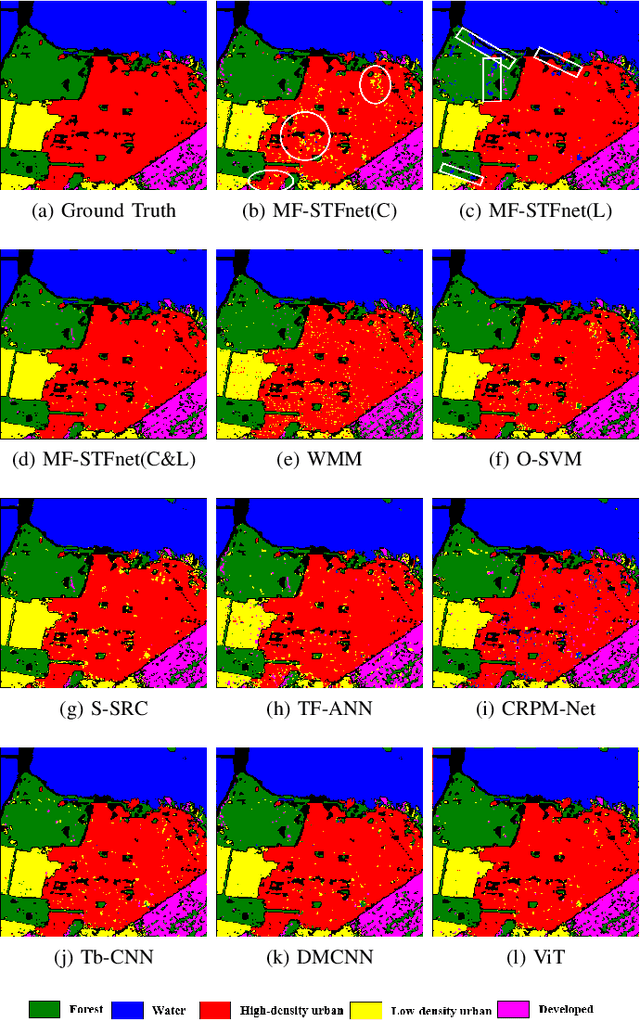
Compared with the rapid development of single-frequency multi-polarization SAR image classification technology, there is less research on the land cover classification of multifrequency polarimetric SAR (MF-PolSAR) images. In addition, the current deep learning methods for MF-PolSAR classification are mainly based on convolutional neural networks (CNNs), only local spatiality is considered but the nonlocal relationship is ignored. Therefore, based on semantic interaction and nonlocal topological structure, this paper proposes the MF semantics and topology fusion network (MF-STFnet) to improve MF-PolSAR classification performance. In MF-STFnet, two kinds of classification are implemented for each band, semantic information-based (SIC) and topological property-based (TPC). They work collaboratively during MF-STFnet training, which can not only fully leverage the complementarity of bands, but also combine local and nonlocal spatial information to improve the discrimination between different categories. For SIC, the designed crossband interactive feature extraction module (CIFEM) is embedded to explicitly model the deep semantic correlation among bands, thereby leveraging the complementarity of bands to make ground objects more separable. For TPC, the graph sample and aggregate network (GraphSAGE) is employed to dynamically capture the representation of nonlocal topological relations between land cover categories. In this way, the robustness of classification can be further improved by combining nonlocal spatial information. Finally, an adaptive weighting fusion (AWF) strategy is proposed to merge inference from different bands, so as to make the MF joint classification decisions of SIC and TPC. The comparative experiments show that MF-STFnet can achieve more competitive classification performance than some state-of-the-art methods.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
Visuo-Tactile Manipulation Planning Using Reinforcement Learning with Affordance Representation
Jul 14, 2022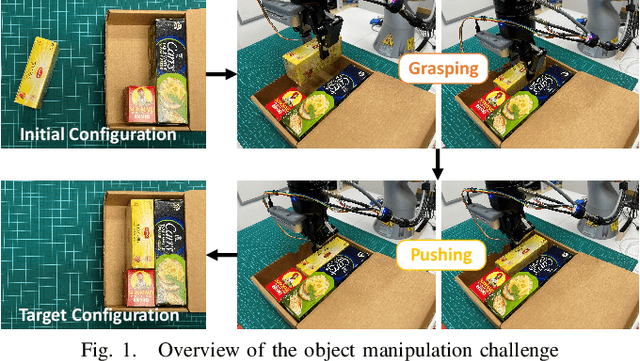
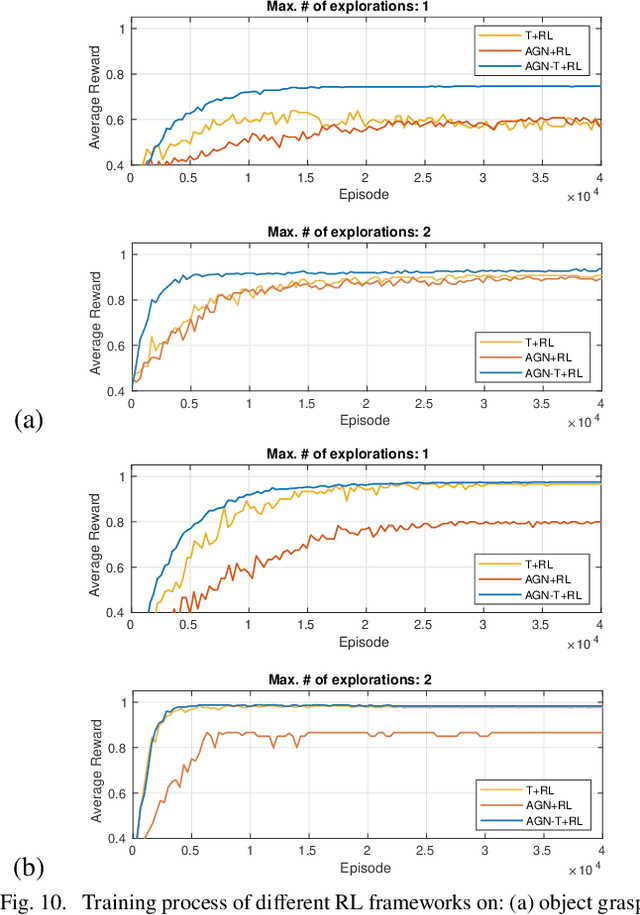
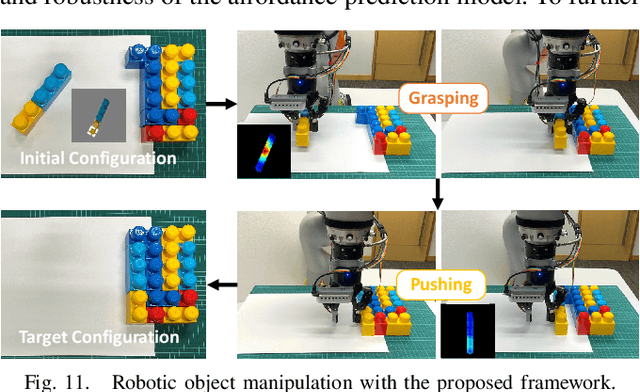
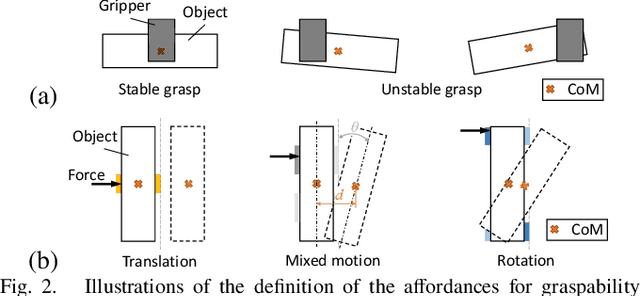
Robots are increasingly expected to manipulate objects in ever more unstructured environments where the object properties have high perceptual uncertainty from any single sensory modality. This directly impacts successful object manipulation. In this work, we propose a reinforcement learning-based motion planning framework for object manipulation which makes use of both on-the-fly multisensory feedback and a learned attention-guided deep affordance model as perceptual states. The affordance model is learned from multiple sensory modalities, including vision and touch (tactile and force/torque), which is designed to predict and indicate the manipulable regions of multiple affordances (i.e., graspability and pushability) for objects with similar appearances but different intrinsic properties (e.g., mass distribution). A DQN-based deep reinforcement learning algorithm is then trained to select the optimal action for successful object manipulation. To validate the performance of the proposed framework, our method is evaluated and benchmarked using both an open dataset and our collected dataset. The results show that the proposed method and overall framework outperform existing methods and achieve better accuracy and higher efficiency.
TAILOR: Teaching with Active and Incremental Learning for Object Registration
May 24, 2022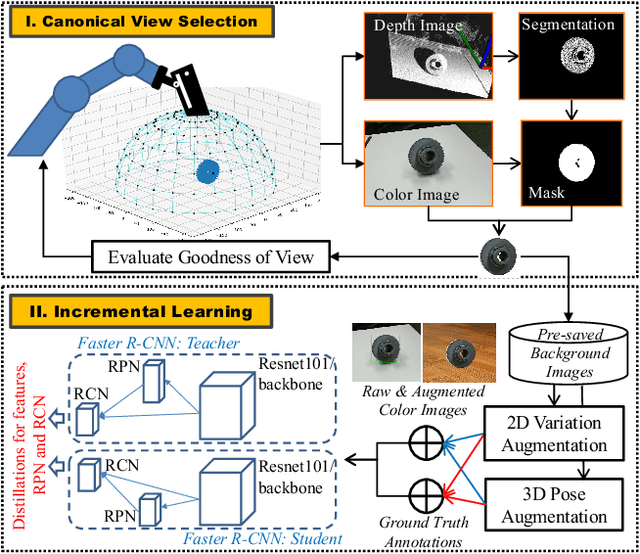
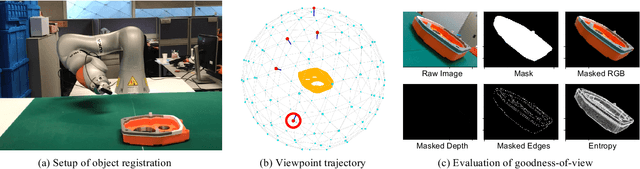

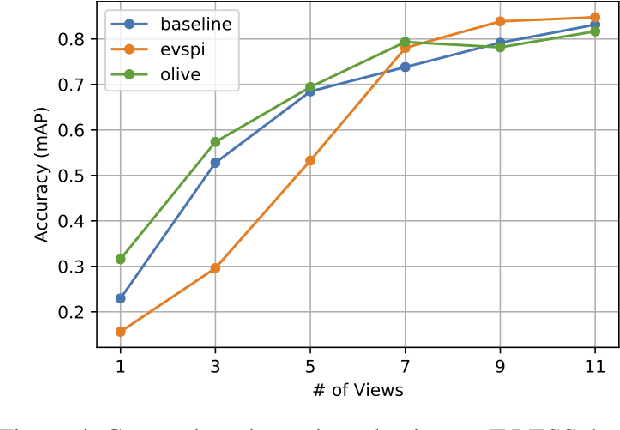
When deploying a robot to a new task, one often has to train it to detect novel objects, which is time-consuming and labor-intensive. We present TAILOR -- a method and system for object registration with active and incremental learning. When instructed by a human teacher to register an object, TAILOR is able to automatically select viewpoints to capture informative images by actively exploring viewpoints, and employs a fast incremental learning algorithm to learn new objects without potential forgetting of previously learned objects. We demonstrate the effectiveness of our method with a KUKA robot to learn novel objects used in a real-world gearbox assembly task through natural interactions.
CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
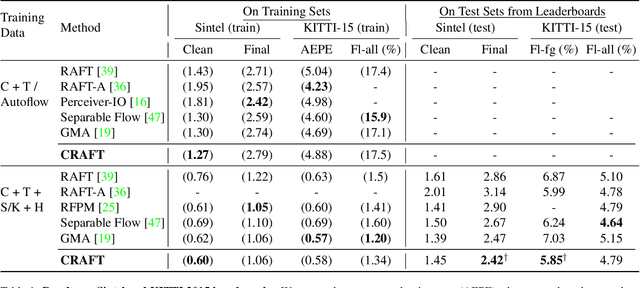
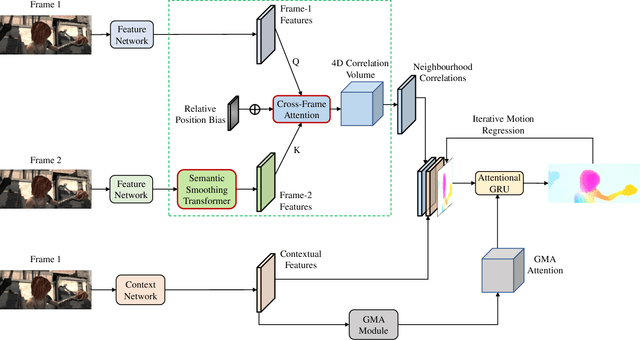
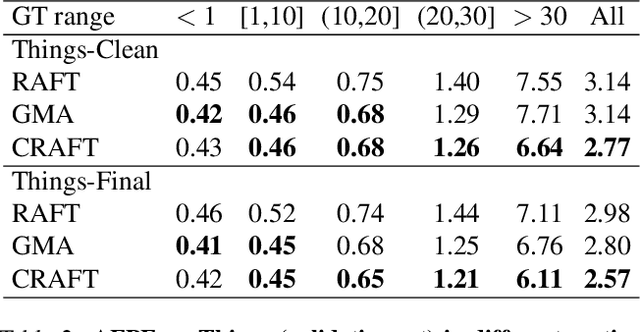
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.
End-to-end Reinforcement Learning of Robotic Manipulation with Robust Keypoints Representation
Feb 12, 2022



We present an end-to-end Reinforcement Learning(RL) framework for robotic manipulation tasks, using a robust and efficient keypoints representation. The proposed method learns keypoints from camera images as the state representation, through a self-supervised autoencoder architecture. The keypoints encode the geometric information, as well as the relationship of the tool and target in a compact representation to ensure efficient and robust learning. After keypoints learning, the RL step then learns the robot motion from the extracted keypoints state representation. The keypoints and RL learning processes are entirely done in the simulated environment. We demonstrate the effectiveness of the proposed method on robotic manipulation tasks including grasping and pushing, in different scenarios. We also investigate the generalization capability of the trained model. In addition to the robust keypoints representation, we further apply domain randomization and adversarial training examples to achieve zero-shot sim-to-real transfer in real-world robotic manipulation tasks.
SAGA: Stochastic Whole-Body Grasping with Contact
Dec 19, 2021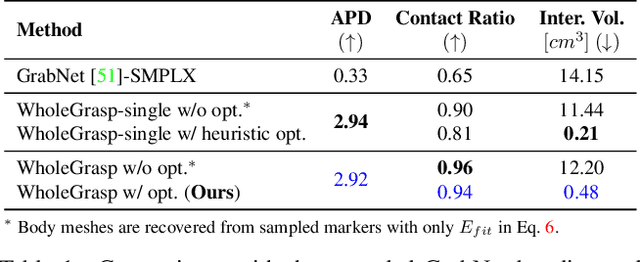

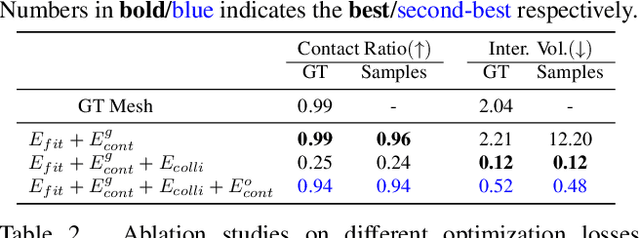
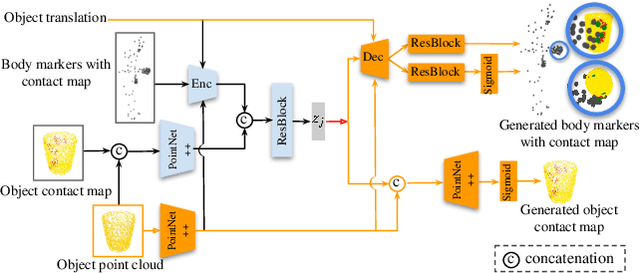
Human grasping synthesis has numerous applications including AR/VR, video games, and robotics. While some methods have been proposed to generate realistic hand-object interaction for object grasping and manipulation, they typically only consider the hand interacting with objects. In this work, our goal is to synthesize whole-body grasping motion. Given a 3D object, we aim to generate diverse and natural whole-body human motions that approach and grasp the object. This task is challenging as it requires modeling both whole-body dynamics and dexterous finger movements. To this end, we propose SAGA (StochAstic whole-body Grasping with contAct) which consists of two key components: (a) Static whole-body grasping pose generation. Specifically, we propose a multi-task generative model, to jointly learn static whole-body grasping poses and human-object contacts. (b) Grasping motion infilling. Given an initial pose and the generated whole-body grasping pose as the starting and ending poses of the motion respectively, we design a novel contact-aware generative motion infilling module to generate a diverse set of grasp-oriented motions. We demonstrate the effectiveness of our method being the first generative framework to synthesize realistic and expressive whole-body motions that approach and grasp randomly placed unseen objects. The code and videos are available at: https://jiahaoplus.github.io/SAGA/saga.html.