 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
WIPES: Wavelet-based Visual Primitives
Aug 18, 2025Pursuing a continuous visual representation that offers flexible frequency modulation and fast rendering speed has recently garnered increasing attention in the fields of 3D vision and graphics. However, existing representations often rely on frequency guidance or complex neural network decoding, leading to spectrum loss or slow rendering. To address these limitations, we propose WIPES, a universal Wavelet-based vIsual PrimitivES for representing multi-dimensional visual signals. Building on the spatial-frequency localization advantages of wavelets, WIPES effectively captures both the low-frequency "forest" and the high-frequency "trees." Additionally, we develop a wavelet-based differentiable rasterizer to achieve fast visual rendering. Experimental results on various visual tasks, including 2D image representation, 5D static and 6D dynamic novel view synthesis, demonstrate that WIPES, as a visual primitive, offers higher rendering quality and faster inference than INR-based methods, and outperforms Gaussian-based representations in rendering quality.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025



The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
3D Gaussian Adaptive Reconstruction for Fourier Light-Field Microscopy
May 19, 2025Compared to light-field microscopy (LFM), which enables high-speed volumetric imaging but suffers from non-uniform spatial sampling, Fourier light-field microscopy (FLFM) introduces sub-aperture division at the pupil plane, thereby ensuring spatially invariant sampling and enhancing spatial resolution. Conventional FLFM reconstruction methods, such as Richardson-Lucy (RL) deconvolution, exhibit poor axial resolution and signal degradation due to the ill-posed nature of the inverse problem. While data-driven approaches enhance spatial resolution by leveraging high-quality paired datasets or imposing structural priors, Neural Radiance Fields (NeRF)-based methods employ physics-informed self-supervised learning to overcome these limitations, yet they are hindered by substantial computational costs and memory demands. Therefore, we propose 3D Gaussian Adaptive Tomography (3DGAT) for FLFM, a 3D gaussian splatting based self-supervised learning framework that significantly improves the volumetric reconstruction quality of FLFM while maintaining computational efficiency. Experimental results indicate that our approach achieves higher resolution and improved reconstruction accuracy, highlighting its potential to advance FLFM imaging and broaden its applications in 3D optical microscopy.
Spike Imaging Velocimetry: Dense Motion Estimation of Fluids Using Spike Cameras
Apr 26, 2025



The need for accurate and non-intrusive flow measurement methods has led to the widespread adoption of Particle Image Velocimetry (PIV), a powerful diagnostic tool in fluid motion estimation. This study investigates the tremendous potential of spike cameras (a type of ultra-high-speed, high-dynamic-range camera) in PIV. We propose a deep learning framework, Spike Imaging Velocimetry (SIV), designed specifically for highly turbulent and intricate flow fields. To aggregate motion features from the spike stream while minimizing information loss, we incorporate a Detail-Preserving Hierarchical Transform (DPHT) module. Additionally, we introduce a Graph Encoder (GE) to extract contextual features from highly complex fluid flows. Furthermore, we present a spike-based PIV dataset, Particle Scenes with Spike and Displacement (PSSD), which provides labeled data for three challenging fluid dynamics scenarios. Our proposed method achieves superior performance compared to existing baseline methods on PSSD. The datasets and our implementation of SIV are open-sourced in the supplementary materials.
MotionPRO: Exploring the Role of Pressure in Human MoCap and Beyond
Apr 07, 2025Existing human Motion Capture (MoCap) methods mostly focus on the visual similarity while neglecting the physical plausibility. As a result, downstream tasks such as driving virtual human in 3D scene or humanoid robots in real world suffer from issues such as timing drift and jitter, spatial problems like sliding and penetration, and poor global trajectory accuracy. In this paper, we revisit human MoCap from the perspective of interaction between human body and physical world by exploring the role of pressure. Firstly, we construct a large-scale human Motion capture dataset with Pressure, RGB and Optical sensors (named MotionPRO), which comprises 70 volunteers performing 400 types of motion, encompassing a total of 12.4M pose frames. Secondly, we examine both the necessity and effectiveness of the pressure signal through two challenging tasks: (1) pose and trajectory estimation based solely on pressure: We propose a network that incorporates a small kernel decoder and a long-short-term attention module, and proof that pressure could provide accurate global trajectory and plausible lower body pose. (2) pose and trajectory estimation by fusing pressure and RGB: We impose constraints on orthographic similarity along the camera axis and whole-body contact along the vertical axis to enhance the cross-attention strategy to fuse pressure and RGB feature maps. Experiments demonstrate that fusing pressure with RGB features not only significantly improves performance in terms of objective metrics, but also plausibly drives virtual humans (SMPL) in 3D scene. Furthermore, we demonstrate that incorporating physical perception enables humanoid robots to perform more precise and stable actions, which is highly beneficial for the development of embodied artificial intelligence. Project page is available at: https://nju-cite-mocaphumanoid.github.io/MotionPRO/
Mitigating Ambiguities in 3D Classification with Gaussian Splatting
Mar 11, 20253D classification with point cloud input is a fundamental problem in 3D vision. However, due to the discrete nature and the insufficient material description of point cloud representations, there are ambiguities in distinguishing wire-like and flat surfaces, as well as transparent or reflective objects. To address these issues, we propose Gaussian Splatting (GS) point cloud-based 3D classification. We find that the scale and rotation coefficients in the GS point cloud help characterize surface types. Specifically, wire-like surfaces consist of multiple slender Gaussian ellipsoids, while flat surfaces are composed of a few flat Gaussian ellipsoids. Additionally, the opacity in the GS point cloud represents the transparency characteristics of objects. As a result, ambiguities in point cloud-based 3D classification can be mitigated utilizing GS point cloud as input. To verify the effectiveness of GS point cloud input, we construct the first real-world GS point cloud dataset in the community, which includes 20 categories with 200 objects in each category. Experiments not only validate the superiority of GS point cloud input, especially in distinguishing ambiguous objects, but also demonstrate the generalization ability across different classification methods.
Gaseous Object Detection
Feb 18, 2025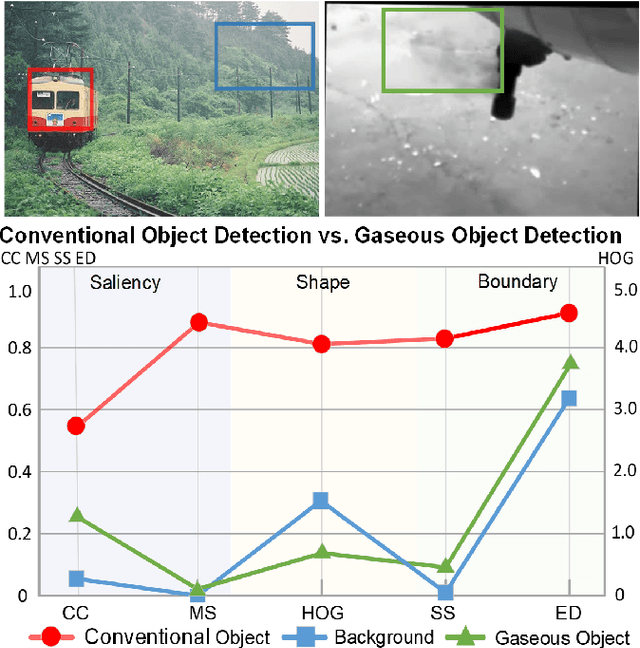



Object detection, a fundamental and challenging problem in computer vision, has experienced rapid development due to the effectiveness of deep learning. The current objects to be detected are mostly rigid solid substances with apparent and distinct visual characteristics. In this paper, we endeavor on a scarcely explored task named Gaseous Object Detection (GOD), which is undertaken to explore whether the object detection techniques can be extended from solid substances to gaseous substances. Nevertheless, the gas exhibits significantly different visual characteristics: 1) saliency deficiency, 2) arbitrary and ever-changing shapes, 3) lack of distinct boundaries. To facilitate the study on this challenging task, we construct a GOD-Video dataset comprising 600 videos (141,017 frames) that cover various attributes with multiple types of gases. A comprehensive benchmark is established based on this dataset, allowing for a rigorous evaluation of frame-level and video-level detectors. Deduced from the Gaussian dispersion model, the physics-inspired Voxel Shift Field (VSF) is designed to model geometric irregularities and ever-changing shapes in potential 3D space. By integrating VSF into Faster RCNN, the VSF RCNN serves as a simple but strong baseline for gaseous object detection. Our work aims to attract further research into this valuable albeit challenging area.