 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Integration of Speech Separation and Recognition with Self-Supervised Learning Representation
Jul 23, 2023


Neural speech separation has made remarkable progress and its integration with automatic speech recognition (ASR) is an important direction towards realizing multi-speaker ASR. This work provides an insightful investigation of speech separation in reverberant and noisy-reverberant scenarios as an ASR front-end. In detail, we explore multi-channel separation methods, mask-based beamforming and complex spectral mapping, as well as the best features to use in the ASR back-end model. We employ the recent self-supervised learning representation (SSLR) as a feature and improve the recognition performance from the case with filterbank features. To further improve multi-speaker recognition performance, we present a carefully designed training strategy for integrating speech separation and recognition with SSLR. The proposed integration using TF-GridNet-based complex spectral mapping and WavLM-based SSLR achieves a 2.5% word error rate in reverberant WHAMR! test set, significantly outperforming an existing mask-based MVDR beamforming and filterbank integration (28.9%).
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023



The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
Reducing Barriers to Self-Supervised Learning: HuBERT Pre-training with Academic Compute
Jun 11, 2023



Self-supervised learning (SSL) has led to great strides in speech processing. However, the resources needed to train these models has become prohibitively large as they continue to scale. Currently, only a few groups with substantial resources are capable of creating SSL models, which harms reproducibility. In this work, we optimize HuBERT SSL to fit in academic constraints. We reproduce HuBERT independently from the original implementation, with no performance loss. Our code and training optimizations make SSL feasible with only 8 GPUs, instead of the 32 used in the original work. We also explore a semi-supervised route, using an ASR model to skip the first pre-training iteration. Within one iteration of pre-training, our models improve over HuBERT on several tasks. Furthermore, our HuBERT Large variant requires only 8 GPUs, achieving similar performance to the original trained on 128. As our contribution to the community, all models, configurations, and code are made open-source in ESPnet.
Exploration of Efficient End-to-End ASR using Discretized Input from Self-Supervised Learning
May 29, 2023



Self-supervised learning (SSL) of speech has shown impressive results in speech-related tasks, particularly in automatic speech recognition (ASR). While most methods employ the output of intermediate layers of the SSL model as real-valued features for downstream tasks, there is potential in exploring alternative approaches that use discretized token sequences. This approach offers benefits such as lower storage requirements and the ability to apply techniques from natural language processing. In this paper, we propose a new protocol that utilizes discretized token sequences in ASR tasks, which includes de-duplication and sub-word modeling to enhance the input sequence. It reduces computational cost by decreasing the length of the sequence. Our experiments on the LibriSpeech dataset demonstrate that our proposed protocol performs competitively with conventional ASR systems using continuous input features, while reducing computational and storage costs.
A New Benchmark of Aphasia Speech Recognition and Detection Based on E-Branchformer and Multi-task Learning
May 19, 2023



Aphasia is a language disorder that affects the speaking ability of millions of patients. This paper presents a new benchmark for Aphasia speech recognition and detection tasks using state-of-the-art speech recognition techniques with the AphsiaBank dataset. Specifically, we introduce two multi-task learning methods based on the CTC/Attention architecture to perform both tasks simultaneously. Our system achieves state-of-the-art speaker-level detection accuracy (97.3%), and a relative WER reduction of 11% for moderate Aphasia patients. In addition, we demonstrate the generalizability of our approach by applying it to another disordered speech database, the DementiaBank Pitt corpus. We will make our all-in-one recipes and pre-trained model publicly available to facilitate reproducibility. Our standardized data preprocessing pipeline and open-source recipes enable researchers to compare results directly, promoting progress in disordered speech processing.
ML-SUPERB: Multilingual Speech Universal PERformance Benchmark
May 18, 2023

Speech processing Universal PERformance Benchmark (SUPERB) is a leaderboard to benchmark the performance of Self-Supervised Learning (SSL) models on various speech processing tasks. However, SUPERB largely considers English speech in its evaluation. This paper presents multilingual SUPERB (ML-SUPERB), covering 143 languages (ranging from high-resource to endangered), and considering both automatic speech recognition and language identification. Following the concept of SUPERB, ML-SUPERB utilizes frozen SSL features and employs a simple framework for multilingual tasks by learning a shallow downstream model. Similar to the SUPERB benchmark, we find speech SSL models can significantly improve performance compared to FBANK features. Furthermore, we find that multilingual models do not always perform better than their monolingual counterparts. We will release ML-SUPERB as a challenge with organized datasets and reproducible training scripts for future multilingual representation research.
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
Apr 25, 2023



Large language models (LLMs) have exhibited remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Despite the recent success, current LLMs are not capable of processing complex audio information or conducting spoken conversations (like Siri or Alexa). In this work, we propose a multi-modal AI system named AudioGPT, which complements LLMs (i.e., ChatGPT) with 1) foundation models to process complex audio information and solve numerous understanding and generation tasks; and 2) the input/output interface (ASR, TTS) to support spoken dialogue. With an increasing demand to evaluate multi-modal LLMs of human intention understanding and cooperation with foundation models, we outline the principles and processes and test AudioGPT in terms of consistency, capability, and robustness. Experimental results demonstrate the capabilities of AudioGPT in solving AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease. Our system is publicly available at \url{https://github.com/AIGC-Audio/AudioGPT}.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023



In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
A Study on the Integration of Pre-trained SSL, ASR, LM and SLU Models for Spoken Language Understanding
Nov 10, 2022



Collecting sufficient labeled data for spoken language understanding (SLU) is expensive and time-consuming. Recent studies achieved promising results by using pre-trained models in low-resource scenarios. Inspired by this, we aim to ask: which (if any) pre-training strategies can improve performance across SLU benchmarks? To answer this question, we employ four types of pre-trained models and their combinations for SLU. We leverage self-supervised speech and language models (LM) pre-trained on large quantities of unpaired data to extract strong speech and text representations. We also explore using supervised models pre-trained on larger external automatic speech recognition (ASR) or SLU corpora. We conduct extensive experiments on the SLU Evaluation (SLUE) benchmark and observe self-supervised pre-trained models to be more powerful, with pre-trained LM and speech models being most beneficial for the Sentiment Analysis and Named Entity Recognition task, respectively.
End-to-End Integration of Speech Recognition, Dereverberation, Beamforming, and Self-Supervised Learning Representation
Oct 19, 2022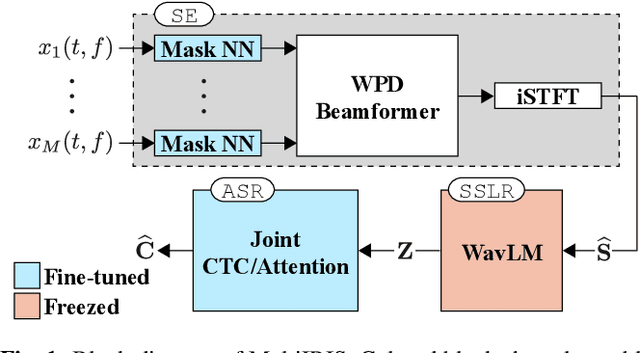
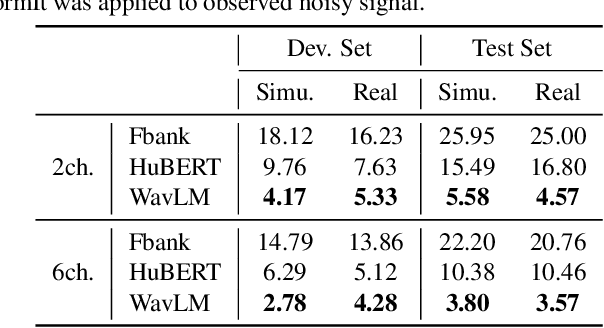
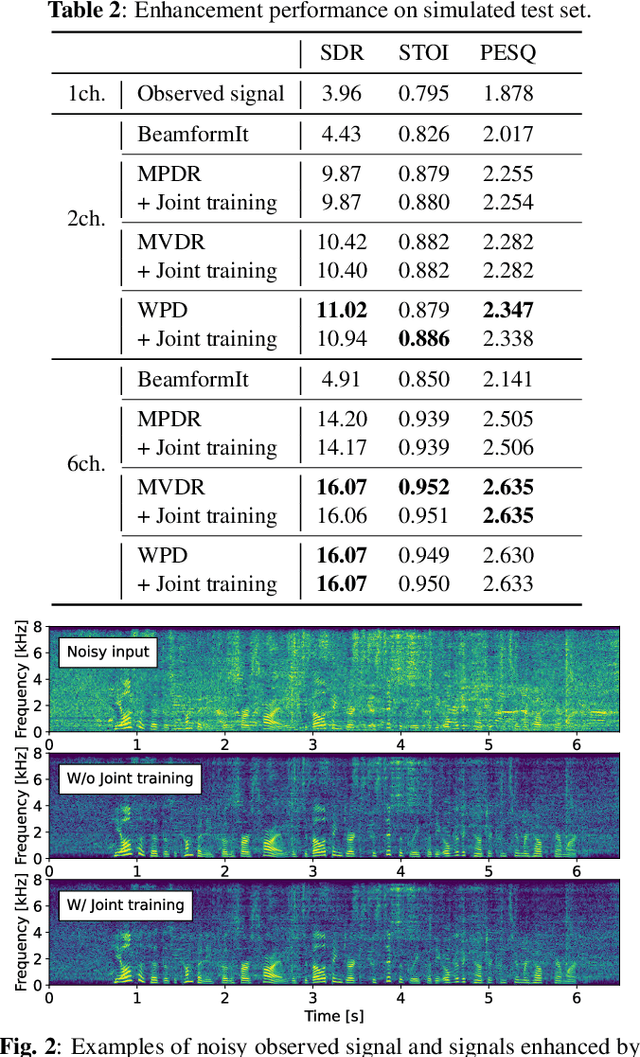
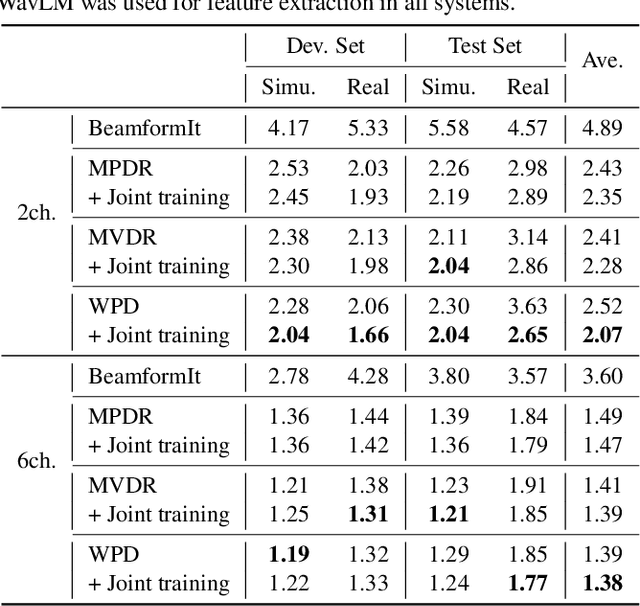
Self-supervised learning representation (SSLR) has demonstrated its significant effectiveness in automatic speech recognition (ASR), mainly with clean speech. Recent work pointed out the strength of integrating SSLR with single-channel speech enhancement for ASR in noisy environments. This paper further advances this integration by dealing with multi-channel input. We propose a novel end-to-end architecture by integrating dereverberation, beamforming, SSLR, and ASR within a single neural network. Our system achieves the best performance reported in the literature on the CHiME-4 6-channel track with a word error rate (WER) of 1.77%. While the WavLM-based strong SSLR demonstrates promising results by itself, the end-to-end integration with the weighted power minimization distortionless response beamformer, which simultaneously performs dereverberation and denoising, improves WER significantly. Its effectiveness is also validated on the REVERB dataset.