 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Continual Pre-training Through Seamless Data Packing
May 29, 2025



Continual pre-training has demonstrated significant potential in enhancing model performance, particularly in domain-specific scenarios. The most common approach for packing data before continual pre-training involves concatenating input texts and splitting them into fixed-length sequences. While straightforward and efficient, this method often leads to excessive truncation and context discontinuity, which can hinder model performance. To address these issues, we explore the potential of data engineering to enhance continual pre-training, particularly its impact on model performance and efficiency. We propose Seamless Packing (SP), a novel data packing strategy aimed at preserving contextual information more effectively and enhancing model performance. Our approach employs a sliding window technique in the first stage that synchronizes overlapping tokens across consecutive sequences, ensuring better continuity and contextual coherence. In the second stage, we adopt a First-Fit-Decreasing algorithm to pack shorter texts into bins slightly larger than the target sequence length, thereby minimizing padding and truncation. Empirical evaluations across various model architectures and corpus domains demonstrate the effectiveness of our method, outperforming baseline method in 99% of all settings. Code is available at https://github.com/Infernus-WIND/Seamless-Packing.
RECAST: Strengthening LLMs' Complex Instruction Following with Constraint-Verifiable Data
May 25, 2025Large language models (LLMs) are increasingly expected to tackle complex tasks, driven by their expanding applications and users' growing proficiency in crafting sophisticated prompts. However, as the number of explicitly stated requirements increases (particularly more than 10 constraints), LLMs often struggle to accurately follow such complex instructions. To address this challenge, we propose RECAST, a novel framework for synthesizing datasets where each example incorporates far more constraints than those in existing benchmarks. These constraints are extracted from real-world prompt-response pairs to ensure practical relevance. RECAST enables automatic verification of constraint satisfaction via rule-based validators for quantitative constraints and LLM-based validators for qualitative ones. Using this framework, we construct RECAST-30K, a large-scale, high-quality dataset comprising 30k instances spanning 15 constraint types. Experimental results demonstrate that models fine-tuned on RECAST-30K show substantial improvements in following complex instructions. Moreover, the verifiability provided by RECAST enables the design of reward functions for reinforcement learning, which further boosts model performance on complex and challenging tasks.
MLLMs are Deeply Affected by Modality Bias
May 24, 2025



Recent advances in Multimodal Large Language Models (MLLMs) have shown promising results in integrating diverse modalities such as texts and images. MLLMs are heavily influenced by modality bias, often relying on language while under-utilizing other modalities like visual inputs. This position paper argues that MLLMs are deeply affected by modality bias. Firstly, we diagnose the current state of modality bias, highlighting its manifestations across various tasks. Secondly, we propose a systematic research road-map related to modality bias in MLLMs. Thirdly, we identify key factors of modality bias in MLLMs and offer actionable suggestions for future research to mitigate it. To substantiate these findings, we conduct experiments that demonstrate the influence of each factor: 1. Data Characteristics: Language data is compact and abstract, while visual data is redundant and complex, creating an inherent imbalance in learning dynamics. 2. Imbalanced Backbone Capabilities: The dominance of pretrained language models in MLLMs leads to overreliance on language and neglect of visual information. 3. Training Objectives: Current objectives often fail to promote balanced cross-modal alignment, resulting in shortcut learning biased toward language. These findings highlight the need for balanced training strategies and model architectures to better integrate multiple modalities in MLLMs. We call for interdisciplinary efforts to tackle these challenges and drive innovation in MLLM research. Our work provides a fresh perspective on modality bias in MLLMs and offers insights for developing more robust and generalizable multimodal systems-advancing progress toward Artificial General Intelligence.
Compression Hacking: A Supplementary Perspective on Informatics Metric of Language Models from Geometric Distortion
May 23, 2025Recently, the concept of ``compression as intelligence'' has provided a novel informatics metric perspective for language models (LMs), emphasizing that highly structured representations signify the intelligence level of LMs. However, from a geometric standpoint, the word representation space of highly compressed LMs tends to degenerate into a highly anisotropic state, which hinders the LM's ability to comprehend instructions and directly impacts its performance. We found this compression-anisotropy synchronicity is essentially the ``Compression Hacking'' in LM representations, where noise-dominated directions tend to create the illusion of high compression rates by sacrificing spatial uniformity. Based on this, we propose three refined compression metrics by incorporating geometric distortion analysis and integrate them into a self-evaluation pipeline. The refined metrics exhibit strong alignment with the LM's comprehensive capabilities, achieving Spearman correlation coefficients above 0.9, significantly outperforming both the original compression and other internal structure-based metrics. This confirms that compression hacking substantially enhances the informatics interpretation of LMs by incorporating geometric distortion of representations.
Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025



Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation
May 11, 2025



Large language models (LLMs) have demonstrated an impressive ability to role-play humans and replicate complex social dynamics. While large-scale social simulations are gaining increasing attention, they still face significant challenges, particularly regarding high time and computation costs. Existing solutions, such as distributed mechanisms or hybrid agent-based model (ABM) integrations, either fail to address inference costs or compromise accuracy and generalizability. To this end, we propose EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation. EcoLANG operates in two stages: (1) language evolution, where we filter synonymous words and optimize sentence-level rules through natural selection, and (2) language utilization, where agents in social simulations communicate using the evolved language. Experimental results demonstrate that EcoLANG reduces token consumption by over 20%, enhancing efficiency without sacrificing simulation accuracy.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025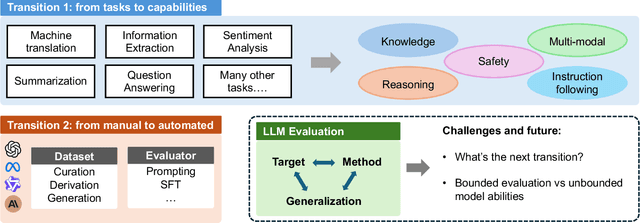
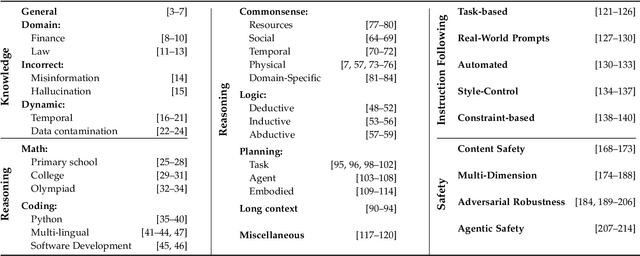
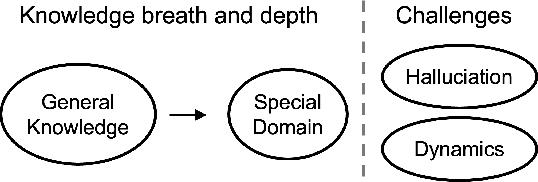
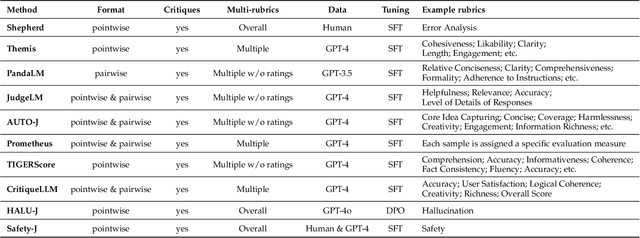
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Effective Length Extrapolation via Dimension-Wise Positional Embeddings Manipulation
Apr 26, 2025Large Language Models (LLMs) often struggle to process and generate coherent context when the number of input tokens exceeds the pre-trained length. Recent advancements in long-context extension have significantly expanded the context window of LLMs but require expensive overhead to train the large-scale models with longer context. In this work, we propose Dimension-Wise Positional Embeddings Manipulation (DPE), a training-free framework to extrapolate the context window of LLMs by diving into RoPE's different hidden dimensions. Instead of manipulating all dimensions equally, DPE detects the effective length for every dimension and finds the key dimensions for context extension. We reuse the original position indices with their embeddings from the pre-trained model and manipulate the key dimensions' position indices to their most effective lengths. In this way, DPE adjusts the pre-trained models with minimal modifications while ensuring that each dimension reaches its optimal state for extrapolation. DPE significantly surpasses well-known baselines such as YaRN and Self-Extend. DPE enables Llama3-8k 8B to support context windows of 128k tokens without continual training and integrates seamlessly with Flash Attention 2. In addition to its impressive extrapolation capability, DPE also dramatically improves the models' performance within training length, such as Llama3.1 70B, by over 18 points on popular long-context benchmarks RULER. When compared with commercial models, Llama 3.1 70B with DPE even achieves better performance than GPT-4-128K.