 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExMesh: EXplicit Mesh Reconstruction with Topology Adaptation
Jun 05, 2026Reconstructing surface meshes from multi-view images has remained a core challenge in recent years. Most existing methods, whether implicit or explicit, depend on intermediate representations and post-processing steps like Marching Cubes or TSDF fusion, often resulting in artifacts and fragmented geometry. Directly optimizing explicit meshes is a promising approach. However, it presents two critical challenges. The first is how to adaptively refine mesh topology to capture detail without introducing degenerate faces. The second is how to maintain consistent UV coordinates for high-fidelity texturing as the mesh structure evolves. To overcome these, we propose ExMesh, a novel framework that directly optimizes explicit meshes by integrating differentiable optimization with discrete topology updates. Specifically, we introduce an adaptive vertex splitting and merging strategy, along with real-time UV maintenance, to enable coarse-to-fine optimization while preserving geometric integrity. To our knowledge, ExMesh is the first framework to seamlessly integrate discrete topology operations into a continuous differentiable optimization pipeline. Extensive experiments demonstrate that ExMesh achieves a balance among accuracy, computational efficiency, and mesh conciseness.
Adversarial Attacks Already Tell the Answer: Directional Bias-Guided Test-time Defense for Vision-Language Models
Jun 04, 2026Vision-Language Models (VLMs), such as CLIP, have shown strong zero-shot generalization but remain highly vulnerable to adversarial perturbations, posing serious risks in real-world applications. Test-time defenses for VLMs have recently emerged as a promising and efficient approach to defend against adversarial attacks without requiring costly large-scale retraining. In this work, we uncover a surprising phenomenon: under diverse input transformations, adversarial images in CLIP's feature space consistently shift along a dominant direction, in contrast to the dispersed patterns of clean images. We hypothesize that this dominant shift, termed the Defense Direction, opposes the adversarial shift, pointing features back toward their correct class centers. Building on this insight, we propose Directional Bias-guided Defense (DBD), a test-time framework that estimates the Defense Direction and employs a DB-score-based two-stream reconstruction strategy to recover robust representations. Experiments on 15 datasets demonstrate that DBD not only achieves SOTA adversarial robustness while preserving clean accuracy, but also reveals the counterintuitive result that adversarial accuracy can even surpass clean accuracy. This demonstrates that adversarial perturbations inherently encode directional priors about the true decision boundary.
ComPose: A Unified Completion-Pose Framework for Robust Category-Level Object Pose Estimation
May 25, 2026Category-level object pose estimation aims to predict the pose and size of arbitrary objects in specific categories. Existing methods struggle with the inherent incompleteness of observed point clouds, which limits their ability to capture complete object shapes for robust pose reasoning. While point cloud completion offers a promising solution, naively treating it as a separate preprocessing step for partial observations introduces compounding errors and additional computational overhead, ultimately hindering both accuracy and efficiency. To address these challenges, we propose ComPose, a novel unified framework that tightly integrates shape completion to provide complete geometric cues for enhanced pose estimation. At the core of ComPose is a keypoint-based progressive completion module, which recovers full shape representations by progressively predicting a sparse set of keypoints and their surrounding dense point sets, empowering the keypoints to capture holistic object geometries. A geometric relation encoding module further enriches keypoint features with both local and global geometric context. In addition, we introduce a novel geometric relation consistency loss to enforce structural alignment between observed keypoints and their predicted NOCS coordinates, ensuring globally coherent coordinate transformations. Extensive experiments on standard benchmarks demonstrate that our method outperforms state-of-the-art approaches without relying on category-level shape priors.
GeoGuide: Hierarchical Geometric Guidance for Open-Vocabulary 3D Semantic Segmentation
Mar 27, 2026Open-vocabulary 3D semantic segmentation aims to segment arbitrary categories beyond the training set. Existing methods predominantly rely on distilling knowledge from 2D open-vocabulary models. However, aligning 3D features to the 2D representation space restricts intrinsic 3D geometric learning and inherits errors from 2D predictions. To address these limitations, we propose GeoGuide, a novel framework that leverages pretrained 3D models to integrate hierarchical geometry-semantic consistency for open-vocabulary 3D segmentation. Specifically, we introduce an Uncertainty-based Superpoint Distillation module to fuse geometric and semantic features for estimating per-point uncertainty, adaptively weighting 2D features within superpoints to suppress noise while preserving discriminative information to enhance local semantic consistency. Furthermore, our Instance-level Mask Reconstruction module leverages geometric priors to enforce semantic consistency within instances by reconstructing complete instance masks. Additionally, our Inter-Instance Relation Consistency module aligns geometric and semantic similarity matrices to calibrate cross-instance consistency for same-category objects, mitigating viewpoint-induced semantic drift. Extensive experiments on ScanNet v2, Matterport3D, and nuScenes demonstrate the superior performance of GeoGuide.
SMTrack: State-Aware Mamba for Efficient Temporal Modeling in Visual Tracking
Feb 02, 2026Visual tracking aims to automatically estimate the state of a target object in a video sequence, which is challenging especially in dynamic scenarios. Thus, numerous methods are proposed to introduce temporal cues to enhance tracking robustness. However, conventional CNN and Transformer architectures exhibit inherent limitations in modeling long-range temporal dependencies in visual tracking, often necessitating either complex customized modules or substantial computational costs to integrate temporal cues. Inspired by the success of the state space model, we propose a novel temporal modeling paradigm for visual tracking, termed State-aware Mamba Tracker (SMTrack), providing a neat pipeline for training and tracking without needing customized modules or substantial computational costs to build long-range temporal dependencies. It enjoys several merits. First, we propose a novel selective state-aware space model with state-wise parameters to capture more diverse temporal cues for robust tracking. Second, SMTrack facilitates long-range temporal interactions with linear computational complexity during training. Third, SMTrack enables each frame to interact with previously tracked frames via hidden state propagation and updating, which releases computational costs of handling temporal cues during tracking. Extensive experimental results demonstrate that SMTrack achieves promising performance with low computational costs.
Correlation and Temporal Consistency Analysis of Mono-static and Bi-static ISAC Channels
Nov 05, 2025Integrated Sensing and Communication (ISAC) is critical for efficient spectrum and hardware utilization in future wireless networks like 6G. However, existing channel models lack comprehensive characterization of ISAC-specific dynamics, particularly the relationship between mono-static (co-located Tx/Rx) and bi-static (separated Tx/Rx) sensing configurations. Empirical measurements in dynamic urban microcell (UMi) environments using a 79-GHz FMCW channel sounder help bridge this gap. Two key findings are demonstrated: (1) mono-static and bi-static channels exhibit consistently low instantaneous correlation due to divergent propagation geometries; (2) despite low instantaneous correlation, both channels share unified temporal consistency, evolving predictably under environmental kinematics. These insights, validated across seven real-world scenarios with moving targets/transceivers, inform robust ISAC system design and future standardization.
Frequency-responsive RCS characteristics and scaling implications for ISAC development
Jul 16, 2025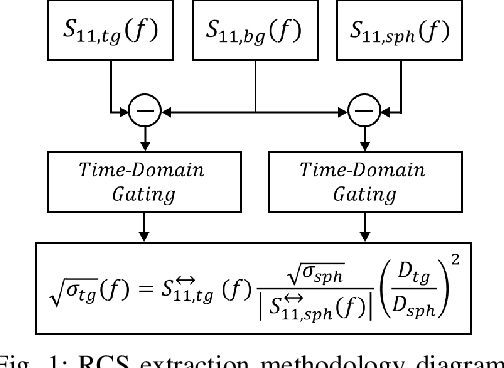
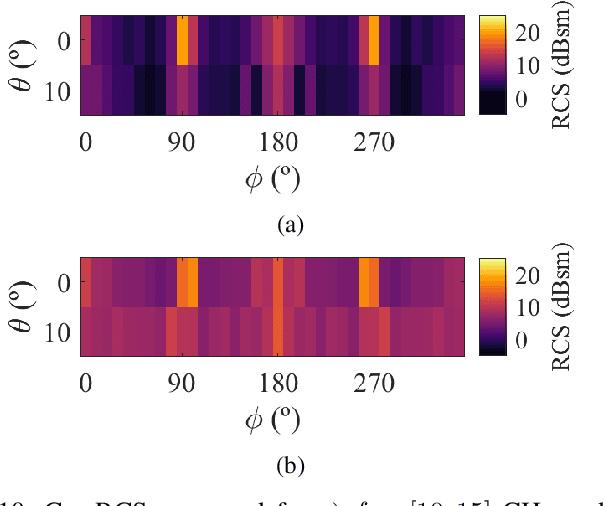
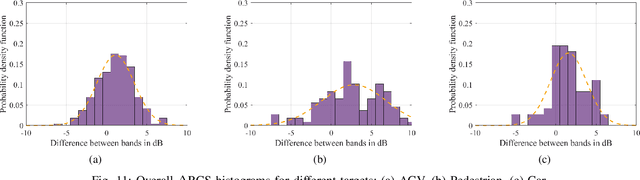
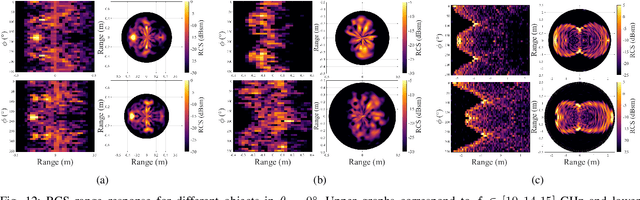
This paper presents an investigation on the Radar Cross-Section (RCS) of various targets, with the objective of analysing how RCS properties vary with frequency. Targets such as an Automated Guided Vehicle (AGV), a pedestrian, and a full-scale car were measured in the frequency bands referred to in industry standards as FR2 and FR3. Measurements were taken in diverse environments, indoors and outdoors, to ensure comprehensive scenario coverage. The methodology employed in RCS extraction performs background subtraction, followed by time-domain gating to isolate the influence of the target. This analysis compares the RCS values and how the points of greatest contribution are distributed across different bands based on the range response of the RCS. Analysis of the results demonstrated how RCS values change with frequency and target shape, providing insights into the electromagnetic behaviour of these targets. Key findings highlight how much scaling RCS values based on frequency and geometry is complex and varies among different types of materials and shapes. These insights are instrumental for advancing sensing systems and enhancing 3GPP channel models, particularly for Integrated Sensing and Communications (ISAC) techniques proposed for 6G standards.
* 6 pages, 12 figures, 3 tables. Accepted for publication at the 2024 IEEE Global Communications Conference (GLOBECOM), WS-02: Workshop on Propagation Channel Models and Evaluation Methodologies for 6G
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
Jun 26, 2025Detection-free methods typically follow a coarse-to-fine pipeline, extracting image and point cloud features for patch-level matching and refining dense pixel-to-point correspondences. However, differences in feature channel attention between images and point clouds may lead to degraded matching results, ultimately impairing registration accuracy. Furthermore, similar structures in the scene could lead to redundant correspondences in cross-modal matching. To address these issues, we propose Channel Adaptive Adjustment Module (CAA) and Global Optimal Selection Module (GOS). CAA enhances intra-modal features and suppresses cross-modal sensitivity, while GOS replaces local selection with global optimization. Experiments on RGB-D Scenes V2 and 7-Scenes demonstrate the superiority of our method, achieving state-of-the-art performance in image-to-point cloud registration.
StruMamba3D: Exploring Structural Mamba for Self-supervised Point Cloud Representation Learning
Jun 26, 2025Recently, Mamba-based methods have demonstrated impressive performance in point cloud representation learning by leveraging State Space Model (SSM) with the efficient context modeling ability and linear complexity. However, these methods still face two key issues that limit the potential of SSM: Destroying the adjacency of 3D points during SSM processing and failing to retain long-sequence memory as the input length increases in downstream tasks. To address these issues, we propose StruMamba3D, a novel paradigm for self-supervised point cloud representation learning. It enjoys several merits. First, we design spatial states and use them as proxies to preserve spatial dependencies among points. Second, we enhance the SSM with a state-wise update strategy and incorporate a lightweight convolution to facilitate interactions between spatial states for efficient structure modeling. Third, our method reduces the sensitivity of pre-trained Mamba-based models to varying input lengths by introducing a sequence length-adaptive strategy. Experimental results across four downstream tasks showcase the superior performance of our method. In addition, our method attains the SOTA 95.1% accuracy on ModelNet40 and 92.75% accuracy on the most challenging split of ScanObjectNN without voting strategy.
Structure-Aware Correspondence Learning for Relative Pose Estimation
Mar 24, 2025Relative pose estimation provides a promising way for achieving object-agnostic pose estimation. Despite the success of existing 3D correspondence-based methods, the reliance on explicit feature matching suffers from small overlaps in visible regions and unreliable feature estimation for invisible regions. Inspired by humans' ability to assemble two object parts that have small or no overlapping regions by considering object structure, we propose a novel Structure-Aware Correspondence Learning method for Relative Pose Estimation, which consists of two key modules. First, a structure-aware keypoint extraction module is designed to locate a set of kepoints that can represent the structure of objects with different shapes and appearance, under the guidance of a keypoint based image reconstruction loss. Second, a structure-aware correspondence estimation module is designed to model the intra-image and inter-image relationships between keypoints to extract structure-aware features for correspondence estimation. By jointly leveraging these two modules, the proposed method can naturally estimate 3D-3D correspondences for unseen objects without explicit feature matching for precise relative pose estimation. Experimental results on the CO3D, Objaverse and LineMOD datasets demonstrate that the proposed method significantly outperforms prior methods, i.e., with 5.7{\deg}reduction in mean angular error on the CO3D dataset.