 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Knowledge Injection Framework for ICD Coding
May 24, 2025
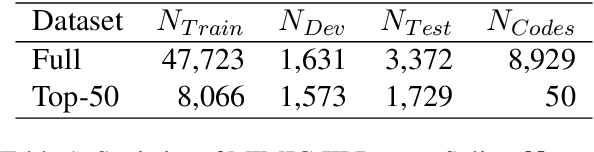
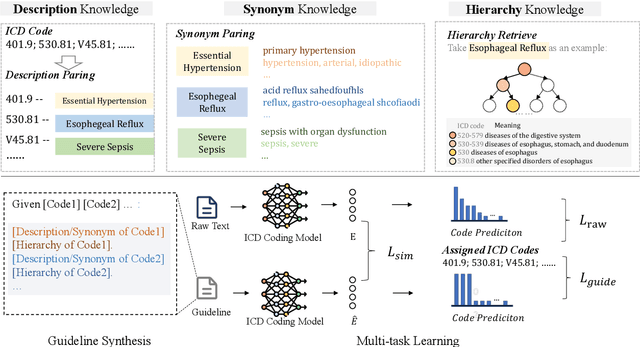
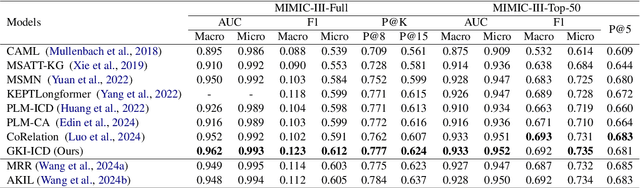
ICD Coding aims to assign a wide range of medical codes to a medical text document, which is a popular and challenging task in the healthcare domain. To alleviate the problems of long-tail distribution and the lack of annotations of code-specific evidence, many previous works have proposed incorporating code knowledge to improve coding performance. However, existing methods often focus on a single type of knowledge and design specialized modules that are complex and incompatible with each other, thereby limiting their scalability and effectiveness. To address this issue, we propose GKI-ICD, a novel, general knowledge injection framework that integrates three key types of knowledge, namely ICD Description, ICD Synonym, and ICD Hierarchy, without specialized design of additional modules. The comprehensive utilization of the above knowledge, which exhibits both differences and complementarity, can effectively enhance the ICD coding performance. Extensive experiments on existing popular ICD coding benchmarks demonstrate the effectiveness of GKI-ICD, which achieves the state-of-the-art performance on most evaluation metrics. Code is available at https://github.com/xuzhang0112/GKI-ICD.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Ultra Lowrate Image Compression with Semantic Residual Coding and Compression-aware Diffusion
May 13, 2025



Existing multimodal large model-based image compression frameworks often rely on a fragmented integration of semantic retrieval, latent compression, and generative models, resulting in suboptimal performance in both reconstruction fidelity and coding efficiency. To address these challenges, we propose a residual-guided ultra lowrate image compression named ResULIC, which incorporates residual signals into both semantic retrieval and the diffusion-based generation process. Specifically, we introduce Semantic Residual Coding (SRC) to capture the semantic disparity between the original image and its compressed latent representation. A perceptual fidelity optimizer is further applied for superior reconstruction quality. Additionally, we present the Compression-aware Diffusion Model (CDM), which establishes an optimal alignment between bitrates and diffusion time steps, improving compression-reconstruction synergy. Extensive experiments demonstrate the effectiveness of ResULIC, achieving superior objective and subjective performance compared to state-of-the-art diffusion-based methods with - 80.7%, -66.3% BD-rate saving in terms of LPIPS and FID. Project page is available at https: //njuvision.github.io/ResULIC/.
Platonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025



The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
C-FAITH: A Chinese Fine-Grained Benchmark for Automated Hallucination Evaluation
Apr 14, 2025Despite the rapid advancement of large language models, they remain highly susceptible to generating hallucinations, which significantly hinders their widespread application. Hallucination research requires dynamic and fine-grained evaluation. However, most existing hallucination benchmarks (especially in Chinese language) rely on human annotations, making automatical and cost-effective hallucination evaluation challenging. To address this, we introduce HaluAgent, an agentic framework that automatically constructs fine-grained QA dataset based on some knowledge documents. Our experiments demonstrate that the manually designed rules and prompt optimization can improve the quality of generated data. Using HaluAgent, we construct C-FAITH, a Chinese QA hallucination benchmark created from 1,399 knowledge documents obtained from web scraping, totaling 60,702 entries. We comprehensively evaluate 16 mainstream LLMs with our proposed C-FAITH, providing detailed experimental results and analysis.
Pay More Attention to the Robustness of Prompt for Instruction Data Mining
Mar 31, 2025Instruction tuning has emerged as a paramount method for tailoring the behaviors of LLMs. Recent work has unveiled the potential for LLMs to achieve high performance through fine-tuning with a limited quantity of high-quality instruction data. Building upon this approach, we further explore the impact of prompt's robustness on the selection of high-quality instruction data. This paper proposes a pioneering framework of high-quality online instruction data mining for instruction tuning, focusing on the impact of prompt's robustness on the data mining process. Our notable innovation, is to generate the adversarial instruction data by conducting the attack for the prompt of online instruction data. Then, we introduce an Adversarial Instruction-Following Difficulty metric to measure how much help the adversarial instruction data can provide to the generation of the corresponding response. Apart from it, we propose a novel Adversarial Instruction Output Embedding Consistency approach to select high-quality online instruction data. We conduct extensive experiments on two benchmark datasets to assess the performance. The experimental results serve to underscore the effectiveness of our proposed two methods. Moreover, the results underscore the critical practical significance of considering prompt's robustness.
MAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025



Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Achieving More with Less: Additive Prompt Tuning for Rehearsal-Free Class-Incremental Learning
Mar 11, 2025



Class-incremental learning (CIL) enables models to learn new classes progressively while preserving knowledge of previously learned ones. Recent advances in this field have shifted towards parameter-efficient fine-tuning techniques, with many approaches building upon the framework that maintains a pool of learnable prompts. Although effective, these methods introduce substantial computational overhead, primarily due to prompt pool querying and increased input sequence lengths from prompt concatenation. In this work, we present a novel prompt-based approach that addresses this limitation. Our method trains a single set of shared prompts across all tasks and, rather than concatenating prompts to the input, directly modifies the CLS token's attention computation by adding the prompts to it. This simple and lightweight design not only significantly reduces computational complexity-both in terms of inference costs and the number of trainable parameters-but also eliminates the need to optimize prompt lengths for different downstream tasks, offering a more efficient yet powerful solution for rehearsal-free class-incremental learning. Extensive experiments across a diverse range of CIL benchmarks demonstrate the effectiveness of our approach, highlighting its potential to establish a new prompt-based CIL paradigm. Furthermore, experiments on general recognition benchmarks beyond the CIL setting also show strong performance, positioning our method as a promising candidate for a general parameter-efficient fine-tuning approach.
AA-CLIP: Enhancing Zero-shot Anomaly Detection via Anomaly-Aware CLIP
Mar 09, 2025Anomaly detection (AD) identifies outliers for applications like defect and lesion detection. While CLIP shows promise for zero-shot AD tasks due to its strong generalization capabilities, its inherent Anomaly-Unawareness leads to limited discrimination between normal and abnormal features. To address this problem, we propose Anomaly-Aware CLIP (AA-CLIP), which enhances CLIP's anomaly discrimination ability in both text and visual spaces while preserving its generalization capability. AA-CLIP is achieved through a straightforward yet effective two-stage approach: it first creates anomaly-aware text anchors to differentiate normal and abnormal semantics clearly, then aligns patch-level visual features with these anchors for precise anomaly localization. This two-stage strategy, with the help of residual adapters, gradually adapts CLIP in a controlled manner, achieving effective AD while maintaining CLIP's class knowledge. Extensive experiments validate AA-CLIP as a resource-efficient solution for zero-shot AD tasks, achieving state-of-the-art results in industrial and medical applications. The code is available at https://github.com/Mwxinnn/AA-CLIP.
* 8 pages, 7 figures
Chemical knowledge-informed framework for privacy-aware retrosynthesis learning
Feb 26, 2025



Chemical reaction data is a pivotal asset, driving advances in competitive fields such as pharmaceuticals, materials science, and industrial chemistry. Its proprietary nature renders it sensitive, as it often includes confidential insights and competitive advantages organizations strive to protect. However, in contrast to this need for confidentiality, the current standard training paradigm for machine learning-based retrosynthesis gathers reaction data from multiple sources into one single edge to train prediction models. This paradigm poses considerable privacy risks as it necessitates broad data availability across organizational boundaries and frequent data transmission between entities, potentially exposing proprietary information to unauthorized access or interception during storage and transfer. In the present study, we introduce the chemical knowledge-informed framework (CKIF), a privacy-preserving approach for learning retrosynthesis models. CKIF enables distributed training across multiple chemical organizations without compromising the confidentiality of proprietary reaction data. Instead of gathering raw reaction data, CKIF learns retrosynthesis models through iterative, chemical knowledge-informed aggregation of model parameters. In particular, the chemical properties of predicted reactants are leveraged to quantitatively assess the observable behaviors of individual models, which in turn determines the adaptive weights used for model aggregation. On a variety of reaction datasets, CKIF outperforms several strong baselines by a clear margin (e.g., ~20% performance improvement over FedAvg on USPTO-50K), showing its feasibility and superiority to stimulate further research on privacy-preserving retrosynthesis.