 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025



Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Robustness Disparities in Face Detection
Nov 29, 2022



Facial analysis systems have been deployed by large companies and critiqued by scholars and activists for the past decade. Many existing algorithmic audits examine the performance of these systems on later stage elements of facial analysis systems like facial recognition and age, emotion, or perceived gender prediction; however, a core component to these systems has been vastly understudied from a fairness perspective: face detection, sometimes called face localization. Since face detection is a pre-requisite step in facial analysis systems, the bias we observe in face detection will flow downstream to the other components like facial recognition and emotion prediction. Additionally, no prior work has focused on the robustness of these systems under various perturbations and corruptions, which leaves open the question of how various people are impacted by these phenomena. We present the first of its kind detailed benchmark of face detection systems, specifically examining the robustness to noise of commercial and academic models. We use both standard and recently released academic facial datasets to quantitatively analyze trends in face detection robustness. Across all the datasets and systems, we generally find that photos of individuals who are $\textit{masculine presenting}$, $\textit{older}$, of $\textit{darker skin type}$, or have $\textit{dim lighting}$ are more susceptible to errors than their counterparts in other identities.
Are Commercial Face Detection Models as Biased as Academic Models?
Jan 25, 2022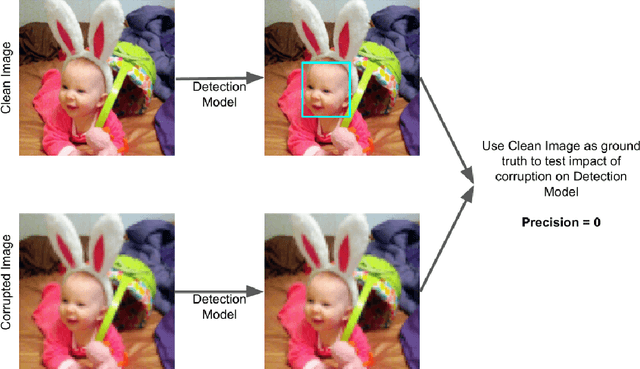
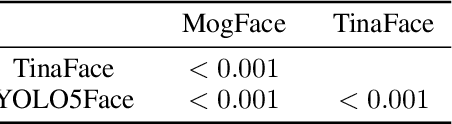
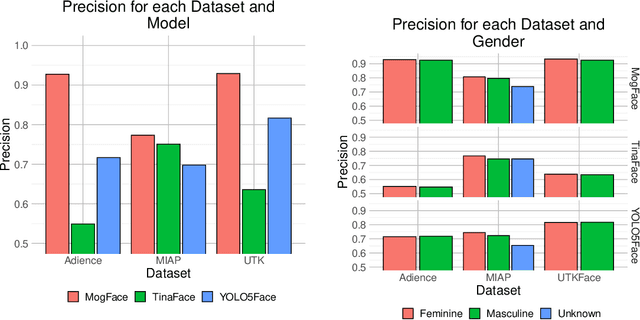
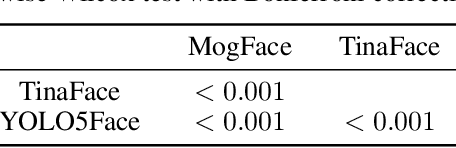
As facial recognition systems are deployed more widely, scholars and activists have studied their biases and harms. Audits are commonly used to accomplish this and compare the algorithmic facial recognition systems' performance against datasets with various metadata labels about the subjects of the images. Seminal works have found discrepancies in performance by gender expression, age, perceived race, skin type, etc. These studies and audits often examine algorithms which fall into two categories: academic models or commercial models. We present a detailed comparison between academic and commercial face detection systems, specifically examining robustness to noise. We find that state-of-the-art academic face detection models exhibit demographic disparities in their noise robustness, specifically by having statistically significant decreased performance on older individuals and those who present their gender in a masculine manner. When we compare the size of these disparities to that of commercial models, we conclude that commercial models - in contrast to their relatively larger development budget and industry-level fairness commitments - are always as biased or more biased than an academic model.