 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting the Trace: A Principled Black-Box Approach Against Distillation Attacks
Apr 25, 2026Frontier models push the boundaries of what is learnable at extreme computational costs, yet distillation via sampling reasoning traces exposes closed-source frontier models to adversarial third parties who can bypass their guardrails and misappropriate their capabilities, raising safety, security, and intellectual privacy concerns. To address this, there is growing interest in building antidistillation methods, which aim to poison reasoning traces to hinder downstream student model learning while maintaining teacher performance. However, current techniques lack theoretical grounding, requiring either heavy fine-tuning or access to student model proxies for gradient based attacks, and often lead to a significant teacher performance degradation. In this work, we present a theoretical formulation of antidistillation as a Stackelberg game, grounding a problem that has so far largely been approached heuristically. Guided by the desired design properties our formulation reveals, we propose \texttt{TraceGuard}, an efficient, post-generation black-box method to poison sentences with high importance for teacher reasoning. Our work offers a scalable solution to share model insights safely, ensuring that the advancement of reasoning capabilities does not come at the cost of intellectual privacy or AI safety alignment.
Your Model Diversity, Not Method, Determines Reasoning Strategy
Apr 12, 2026Compute scaling for LLM reasoning requires allocating budget between exploring solution approaches ($breadth$) and refining promising solutions ($depth$). Most methods implicitly trade off one for the other, yet why a given trade-off works remains unclear, and validation on a single model obscures the role of the model itself. We argue that $\textbf{the optimal strategy depends on the model's diversity profile, the spread of probability mass across solution approaches, and that this must be characterized before any exploration strategy is adopted.}$ We formalize this through a theoretical framework decomposing reasoning uncertainty and derive conditions under which tree-style depth refinement outperforms parallel sampling. We validate it on Qwen-3 4B and Olmo-3 7B families, showing that lightweight signals suffice for depth-based refinement on low-diversity aligned models while yielding limited utility for high-diversity base models, which we hypothesize require stronger compensation for lower exploration coverage.
Platonic Grounding for Efficient Multimodal Language Models
Apr 27, 2025



The hyperscaling of data and parameter count in Transformer-based models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing indicates the importance of methods for more efficient finetuning and inference, while retaining similar performance. This is especially relevant for multimodal learning paradigms, where inference costs of processing multimodal tokens can determine the model's practical viability. At the same time, research on representations and mechanistic interpretability has improved our understanding of the inner workings of Transformer-based models; one such line of work reveals an implicit alignment in the deeper layers of pretrained models, across modalities. Taking inspiration from this, we motivate and propose a simple modification to existing multimodal frameworks that rely on aligning pretrained models. We demonstrate that our approach maintains and, in some cases, even improves performance of baseline methods while achieving significant gains in both training and inference-time compute. Our work also has implications for combining pretrained models into larger systems efficiently.
Language Grounded QFormer for Efficient Vision Language Understanding
Nov 13, 2023



Large-scale pretraining and instruction tuning have been successful for training general-purpose language models with broad competencies. However, extending to general-purpose vision-language models is challenging due to the distributional diversity in visual inputs. A recent line of work explores vision-language instruction tuning, taking inspiration from the Query Transformer (QFormer) approach proposed in BLIP-2 models for bridging frozen modalities. However, these approaches rely heavily on large-scale multi-modal pretraining for representation learning before eventual finetuning, incurring a huge computational overhead, poor scaling, and limited accessibility. To that end, we propose a more efficient method for QFormer-based vision-language alignment and demonstrate the effectiveness of our strategy compared to existing baselines in improving the efficiency of vision-language pretraining.
Transformers are Universal Predictors
Jul 15, 2023



We find limits to the Transformer architecture for language modeling and show it has a universal prediction property in an information-theoretic sense. We further analyze performance in non-asymptotic data regimes to understand the role of various components of the Transformer architecture, especially in the context of data-efficient training. We validate our theoretical analysis with experiments on both synthetic and real datasets.
Learning Optimal Features via Partial Invariance
Jan 28, 2023Learning models that are robust to test-time distribution shifts is a key concern in domain generalization, and in the wider context of their real-life applicability. Invariant Risk Minimization (IRM) is one particular framework that aims to learn deep invariant features from multiple domains and has subsequently led to further variants. A key assumption for the success of these methods requires that the underlying causal mechanisms/features remain invariant across domains and the true invariant features be sufficient to learn the optimal predictor. In practical problem settings, these assumptions are often not satisfied, which leads to IRM learning a sub-optimal predictor for that task. In this work, we propose the notion of partial invariance as a relaxation of the IRM framework. Under our problem setting, we first highlight the sub-optimality of the IRM solution. We then demonstrate how partitioning the training domains, assuming access to some meta-information about the domains, can help improve the performance of invariant models via partial invariance. Finally, we conduct several experiments, both in linear settings as well as with classification tasks in language and images with deep models, which verify our conclusions.
The Spectral Bias of Polynomial Neural Networks
Feb 27, 2022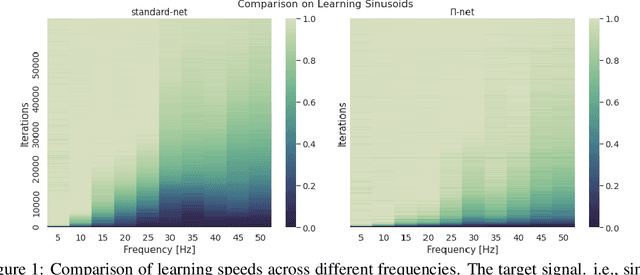
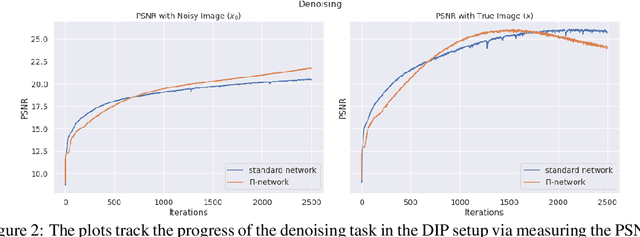
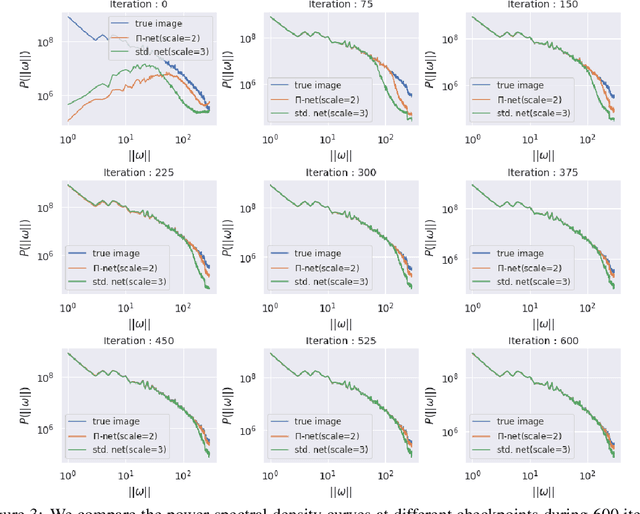
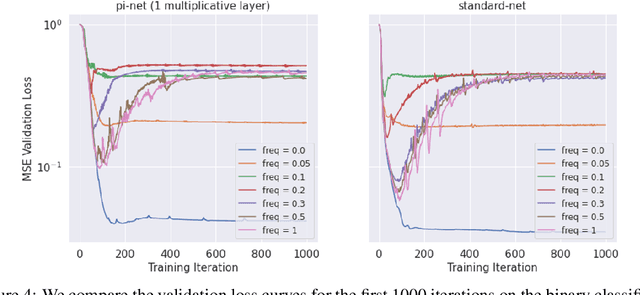
Polynomial neural networks (PNNs) have been recently shown to be particularly effective at image generation and face recognition, where high-frequency information is critical. Previous studies have revealed that neural networks demonstrate a $\textit{spectral bias}$ towards low-frequency functions, which yields faster learning of low-frequency components during training. Inspired by such studies, we conduct a spectral analysis of the Neural Tangent Kernel (NTK) of PNNs. We find that the $\Pi$-Net family, i.e., a recently proposed parametrization of PNNs, speeds up the learning of the higher frequencies. We verify the theoretical bias through extensive experiments. We expect our analysis to provide novel insights into designing architectures and learning frameworks by incorporating multiplicative interactions via polynomials.
Balancing Fairness and Robustness via Partial Invariance
Dec 24, 2021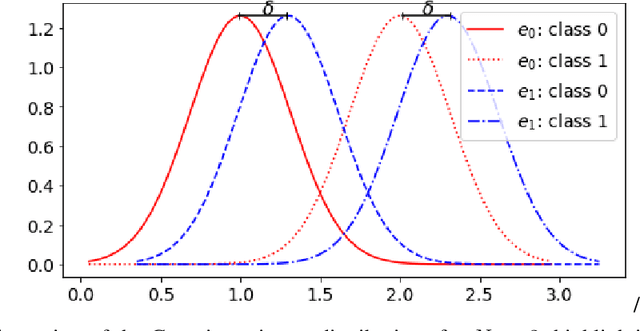
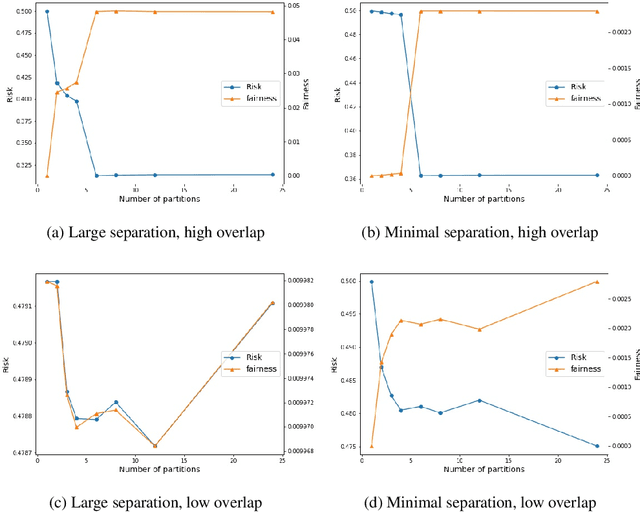
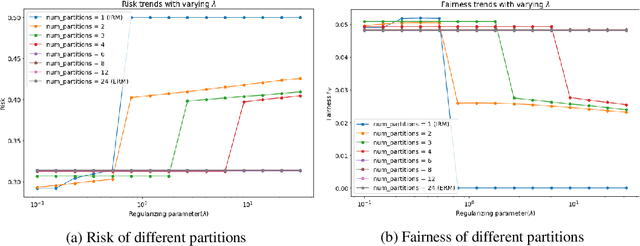
The Invariant Risk Minimization (IRM) framework aims to learn invariant features from a set of environments for solving the out-of-distribution (OOD) generalization problem. The underlying assumption is that the causal components of the data generating distributions remain constant across the environments or alternately, the data "overlaps" across environments to find meaningful invariant features. Consequently, when the "overlap" assumption does not hold, the set of truly invariant features may not be sufficient for optimal prediction performance. Such cases arise naturally in networked settings and hierarchical data-generating models, wherein the IRM performance becomes suboptimal. To mitigate this failure case, we argue for a partial invariance framework. The key idea is to introduce flexibility into the IRM framework by partitioning the environments based on hierarchical differences, while enforcing invariance locally within the partitions. We motivate this framework in classification settings with causal distribution shifts across environments. Our results show the capability of the partial invariant risk minimization to alleviate the trade-off between fairness and risk in certain settings.