 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasHost Builds It All: Autonomous Multi-Agent System Directed by Reinforcement Learning
Jun 12, 2025Large Language Model (LLM)-driven Multi-agent systems (Mas) have recently emerged as a powerful paradigm for tackling complex real-world tasks. However, existing Mas construction methods typically rely on manually crafted interaction mechanisms or heuristic rules, introducing human biases and constraining the autonomous ability. Even with recent advances in adaptive Mas construction, existing systems largely remain within the paradigm of semi-autonomous patterns. In this work, we propose MasHost, a Reinforcement Learning (RL)-based framework for autonomous and query-adaptive Mas design. By formulating Mas construction as a graph search problem, our proposed MasHost jointly samples agent roles and their interactions through a unified probabilistic sampling mechanism. Beyond the accuracy and efficiency objectives pursued in prior works, we introduce component rationality as an additional and novel design principle in Mas. To achieve this multi-objective optimization, we propose Hierarchical Relative Policy Optimization (HRPO), a novel RL strategy that collaboratively integrates group-relative advantages and action-wise rewards. To our knowledge, our proposed MasHost is the first RL-driven framework for autonomous Mas graph construction. Extensive experiments on six benchmarks demonstrate that MasHost consistently outperforms most competitive baselines, validating its effectiveness, efficiency, and structure rationality.
Model Unlearning via Sparse Autoencoder Subspace Guided Projections
May 30, 2025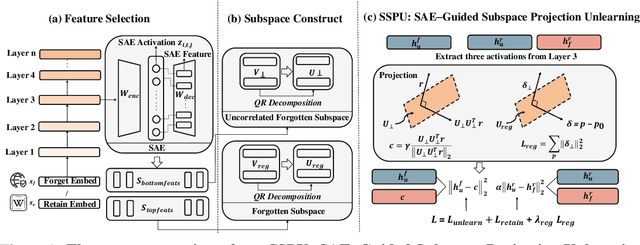



Large language models (LLMs) store vast amounts of information, making them powerful yet raising privacy and safety concerns when selective knowledge removal is required. Existing unlearning strategies, ranging from gradient-based fine-tuning and model editing to sparse autoencoder (SAE) steering, either lack interpretability or fail to provide a robust defense against adversarial prompts. We propose SAE-Guided Subspace Projection Unlearning (SSPU), a novel framework that leverages SAE features to drive targeted updates in the model's parameter space, enabling precise, interpretable, and robust unlearning. SSPU's three-stage pipeline performs data-driven layer and feature selection, subspace construction via QR decomposition, and constrained optimization that controls activations into an "irrelevant" subspace while preserving retained knowledge. Overall, we use SAE features to construct a subspace that supervises unlearning, refining the loss and adding a regularization term to guide interpretable parameter updates. In experiments on the WMDP-Cyber forget set and three utility benchmarks (MMLU, TruthfulQA, GSM8K), SSPU reduces harmful knowledge accuracy by 3.22% compared to the strongest baseline. It also improves adversarial robustness, lowering malicious accuracy under jailbreak prompts compared to baselines. Our findings expose the limitations of prior unlearning methods and demonstrate how interpretable subspace-guided optimization can achieve robust, controllable model behavior.
DetailFlow: 1D Coarse-to-Fine Autoregressive Image Generation via Next-Detail Prediction
May 27, 2025This paper presents DetailFlow, a coarse-to-fine 1D autoregressive (AR) image generation method that models images through a novel next-detail prediction strategy. By learning a resolution-aware token sequence supervised with progressively degraded images, DetailFlow enables the generation process to start from the global structure and incrementally refine details. This coarse-to-fine 1D token sequence aligns well with the autoregressive inference mechanism, providing a more natural and efficient way for the AR model to generate complex visual content. Our compact 1D AR model achieves high-quality image synthesis with significantly fewer tokens than previous approaches, i.e. VAR/VQGAN. We further propose a parallel inference mechanism with self-correction that accelerates generation speed by approximately 8x while reducing accumulation sampling error inherent in teacher-forcing supervision. On the ImageNet 256x256 benchmark, our method achieves 2.96 gFID with 128 tokens, outperforming VAR (3.3 FID) and FlexVAR (3.05 FID), which both require 680 tokens in their AR models. Moreover, due to the significantly reduced token count and parallel inference mechanism, our method runs nearly 2x faster inference speed compared to VAR and FlexVAR. Extensive experimental results demonstrate DetailFlow's superior generation quality and efficiency compared to existing state-of-the-art methods.
YOLO-FireAD: Efficient Fire Detection via Attention-Guided Inverted Residual Learning and Dual-Pooling Feature Preservation
May 27, 2025Fire detection in dynamic environments faces continuous challenges, including the interference of illumination changes, many false detections or missed detections, and it is difficult to achieve both efficiency and accuracy. To address the problem of feature extraction limitation and information loss in the existing YOLO-based models, this study propose You Only Look Once for Fire Detection with Attention-guided Inverted Residual and Dual-pooling Downscale Fusion (YOLO-FireAD) with two core innovations: (1) Attention-guided Inverted Residual Block (AIR) integrates hybrid channel-spatial attention with inverted residuals to adaptively enhance fire features and suppress environmental noise; (2) Dual Pool Downscale Fusion Block (DPDF) preserves multi-scale fire patterns through learnable fusion of max-average pooling outputs, mitigating small-fire detection failures. Extensive evaluation on two public datasets shows the efficient performance of our model. Our proposed model keeps the sum amount of parameters (1.45M, 51.8% lower than YOLOv8n) (4.6G, 43.2% lower than YOLOv8n), and mAP75 is higher than the mainstream real-time object detection models YOLOv8n, YOL-Ov9t, YOLOv10n, YOLO11n, YOLOv12n and other YOLOv8 variants 1.3-5.5%.
SuperGS: Consistent and Detailed 3D Super-Resolution Scene Reconstruction via Gaussian Splatting
May 24, 2025Recently, 3D Gaussian Splatting (3DGS) has excelled in novel view synthesis (NVS) with its real-time rendering capabilities and superior quality. However, it encounters challenges for high-resolution novel view synthesis (HRNVS) due to the coarse nature of primitives derived from low-resolution input views. To address this issue, we propose SuperGS, an expansion of Scaffold-GS designed with a two-stage coarse-to-fine training framework. In the low-resolution stage, we introduce a latent feature field to represent the low-resolution scene, which serves as both the initialization and foundational information for super-resolution optimization. In the high-resolution stage, we propose a multi-view consistent densification strategy that backprojects high-resolution depth maps based on error maps and employs a multi-view voting mechanism, mitigating ambiguities caused by multi-view inconsistencies in the pseudo labels provided by 2D prior models while avoiding Gaussian redundancy. Furthermore, we model uncertainty through variational feature learning and use it to guide further scene representation refinement and adjust the supervisory effect of pseudo-labels, ensuring consistent and detailed scene reconstruction. Extensive experiments demonstrate that SuperGS outperforms state-of-the-art HRNVS methods on both forward-facing and 360-degree datasets.
Exploring LLM-Generated Feedback for Economics Essays: How Teaching Assistants Evaluate and Envision Its Use
May 21, 2025


This project examines the prospect of using AI-generated feedback as suggestions to expedite and enhance human instructors' feedback provision. In particular, we focus on understanding the teaching assistants' perspectives on the quality of AI-generated feedback and how they may or may not utilize AI feedback in their own workflows. We situate our work in a foundational college Economics class, which has frequent short essay assignments. We developed an LLM-powered feedback engine that generates feedback on students' essays based on grading rubrics used by the teaching assistants (TAs). To ensure that TAs can meaningfully critique and engage with the AI feedback, we had them complete their regular grading jobs. For a randomly selected set of essays that they had graded, we used our feedback engine to generate feedback and displayed the feedback as in-text comments in a Word document. We then performed think-aloud studies with 5 TAs over 20 1-hour sessions to have them evaluate the AI feedback, contrast the AI feedback with their handwritten feedback, and share how they envision using the AI feedback if they were offered as suggestions. The study highlights the importance of providing detailed rubrics for AI to generate high-quality feedback for knowledge-intensive essays. TAs considered that using AI feedback as suggestions during their grading could expedite grading, enhance consistency, and improve overall feedback quality. We discuss the importance of decomposing the feedback generation task into steps and presenting intermediate results, in order for TAs to use the AI feedback.
SynEVO: A neuro-inspired spatiotemporal evolutional framework for cross-domain adaptation
May 21, 2025Discovering regularities from spatiotemporal systems can benefit various scientific and social planning. Current spatiotemporal learners usually train an independent model from a specific source data that leads to limited transferability among sources, where even correlated tasks requires new design and training. The key towards increasing cross-domain knowledge is to enable collective intelligence and model evolution. In this paper, inspired by neuroscience theories, we theoretically derive the increased information boundary via learning cross-domain collective intelligence and propose a Synaptic EVOlutional spatiotemporal network, SynEVO, where SynEVO breaks the model independence and enables cross-domain knowledge to be shared and aggregated. Specifically, we first re-order the sample groups to imitate the human curriculum learning, and devise two complementary learners, elastic common container and task-independent extractor to allow model growth and task-wise commonality and personality disentanglement. Then an adaptive dynamic coupler with a new difference metric determines whether the new sample group should be incorporated into common container to achieve model evolution under various domains. Experiments show that SynEVO improves the generalization capacity by at most 42% under cross-domain scenarios and SynEVO provides a paradigm of NeuroAI for knowledge transfer and adaptation.
Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models
May 21, 2025Large Language Models (LLMs) demonstrate the ability to solve reasoning and mathematical problems using the Chain-of-Thought (CoT) technique. Expanding CoT length, as seen in models such as DeepSeek-R1, significantly enhances this reasoning for complex problems, but requires costly and high-quality long CoT data and fine-tuning. This work, inspired by the deep thinking paradigm of DeepSeek-R1, utilizes a steering technique to enhance the reasoning ability of an LLM without external datasets. Our method first employs Sparse Autoencoders (SAEs) to extract interpretable features from vanilla CoT. These features are then used to steer the LLM's internal states during generation. Recognizing that many LLMs do not have corresponding pre-trained SAEs, we further introduce a novel SAE-free steering algorithm, which directly computes steering directions from the residual activations of an LLM, obviating the need for an explicit SAE. Experimental results demonstrate that both our SAE-based and subsequent SAE-free steering algorithms significantly enhance the reasoning capabilities of LLMs.
PoLO: Proof-of-Learning and Proof-of-Ownership at Once with Chained Watermarking
May 18, 2025Machine learning models are increasingly shared and outsourced, raising requirements of verifying training effort (Proof-of-Learning, PoL) to ensure claimed performance and establishing ownership (Proof-of-Ownership, PoO) for transactions. When models are trained by untrusted parties, PoL and PoO must be enforced together to enable protection, attribution, and compensation. However, existing studies typically address them separately, which not only weakens protection against forgery and privacy breaches but also leads to high verification overhead. We propose PoLO, a unified framework that simultaneously achieves PoL and PoO using chained watermarks. PoLO splits the training process into fine-grained training shards and embeds a dedicated watermark in each shard. Each watermark is generated using the hash of the preceding shard, certifying the training process of the preceding shard. The chained structure makes it computationally difficult to forge any individual part of the whole training process. The complete set of watermarks serves as the PoL, while the final watermark provides the PoO. PoLO offers more efficient and privacy-preserving verification compared to the vanilla PoL solutions that rely on gradient-based trajectory tracing and inadvertently expose training data during verification, while maintaining the same level of ownership assurance of watermark-based PoO schemes. Our evaluation shows that PoLO achieves 99% watermark detection accuracy for ownership verification, while preserving data privacy and cutting verification costs to just 1.5-10% of traditional methods. Forging PoLO demands 1.1-4x more resources than honest proof generation, with the original proof retaining over 90% detection accuracy even after attacks.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.