 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGM-NeRF: Learning Generalizable Model-based Neural Radiance Fields from Multi-view Images
Mar 24, 2023



In this work, we focus on synthesizing high-fidelity novel view images for arbitrary human performers, given a set of sparse multi-view images. It is a challenging task due to the large variation among articulated body poses and heavy self-occlusions. To alleviate this, we introduce an effective generalizable framework Generalizable Model-based Neural Radiance Fields (GM-NeRF) to synthesize free-viewpoint images. Specifically, we propose a geometry-guided attention mechanism to register the appearance code from multi-view 2D images to a geometry proxy which can alleviate the misalignment between inaccurate geometry prior and pixel space. On top of that, we further conduct neural rendering and partial gradient backpropagation for efficient perceptual supervision and improvement of the perceptual quality of synthesis. To evaluate our method, we conduct experiments on synthesized datasets THuman2.0 and Multi-garment, and real-world datasets Genebody and ZJUMocap. The results demonstrate that our approach outperforms state-of-the-art methods in terms of novel view synthesis and geometric reconstruction.
Dual Memory Aggregation Network for Event-Based Object Detection with Learnable Representation
Mar 17, 2023



Event-based cameras are bio-inspired sensors that capture brightness change of every pixel in an asynchronous manner. Compared with frame-based sensors, event cameras have microsecond-level latency and high dynamic range, hence showing great potential for object detection under high-speed motion and poor illumination conditions. Due to sparsity and asynchronism nature with event streams, most of existing approaches resort to hand-crafted methods to convert event data into 2D grid representation. However, they are sub-optimal in aggregating information from event stream for object detection. In this work, we propose to learn an event representation optimized for event-based object detection. Specifically, event streams are divided into grids in the x-y-t coordinates for both positive and negative polarity, producing a set of pillars as 3D tensor representation. To fully exploit information with event streams to detect objects, a dual-memory aggregation network (DMANet) is proposed to leverage both long and short memory along event streams to aggregate effective information for object detection. Long memory is encoded in the hidden state of adaptive convLSTMs while short memory is modeled by computing spatial-temporal correlation between event pillars at neighboring time intervals. Extensive experiments on the recently released event-based automotive detection dataset demonstrate the effectiveness of the proposed method.
AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
Apr 29, 2022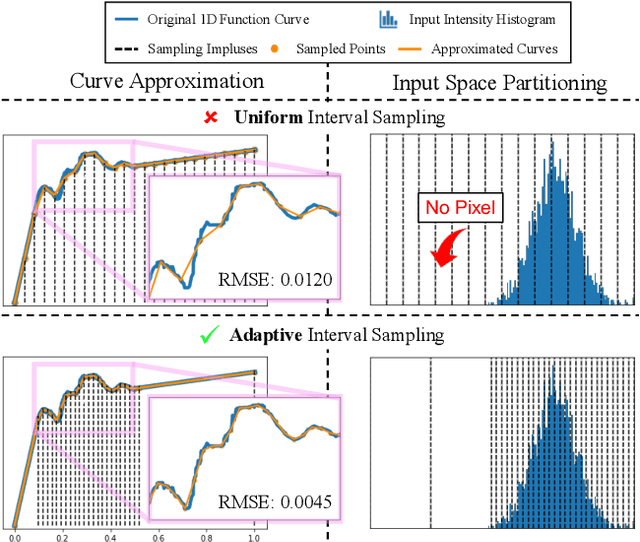

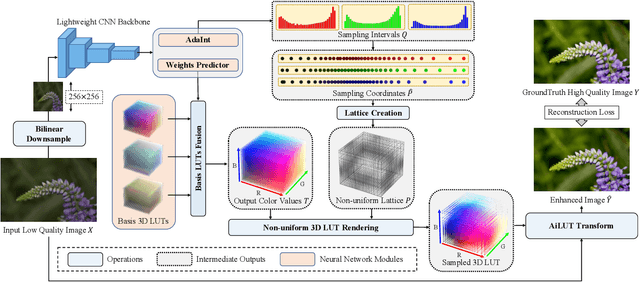
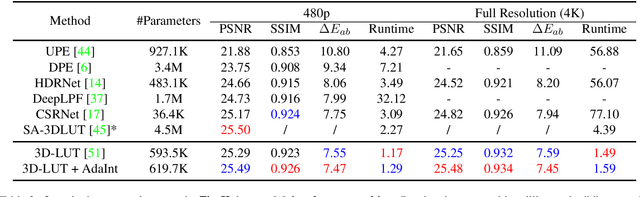
The 3D Lookup Table (3D LUT) is a highly-efficient tool for real-time image enhancement tasks, which models a non-linear 3D color transform by sparsely sampling it into a discretized 3D lattice. Previous works have made efforts to learn image-adaptive output color values of LUTs for flexible enhancement but neglect the importance of sampling strategy. They adopt a sub-optimal uniform sampling point allocation, limiting the expressiveness of the learned LUTs since the (tri-)linear interpolation between uniform sampling points in the LUT transform might fail to model local non-linearities of the color transform. Focusing on this problem, we present AdaInt (Adaptive Intervals Learning), a novel mechanism to achieve a more flexible sampling point allocation by adaptively learning the non-uniform sampling intervals in the 3D color space. In this way, a 3D LUT can increase its capability by conducting dense sampling in color ranges requiring highly non-linear transforms and sparse sampling for near-linear transforms. The proposed AdaInt could be implemented as a compact and efficient plug-and-play module for a 3D LUT-based method. To enable the end-to-end learning of AdaInt, we design a novel differentiable operator called AiLUT-Transform (Adaptive Interval LUT Transform) to locate input colors in the non-uniform 3D LUT and provide gradients to the sampling intervals. Experiments demonstrate that methods equipped with AdaInt can achieve state-of-the-art performance on two public benchmark datasets with a negligible overhead increase. Our source code is available at https://github.com/ImCharlesY/AdaInt.
Look Back and Forth: Video Super-Resolution with Explicit Temporal Difference Modeling
Apr 14, 2022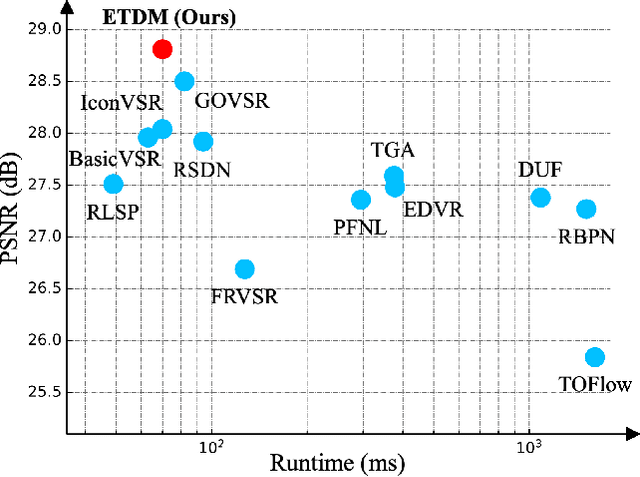
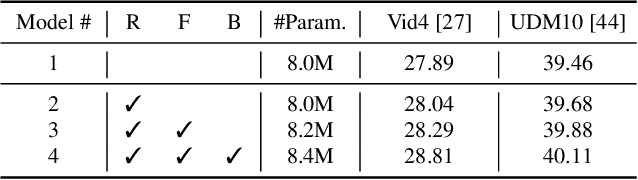
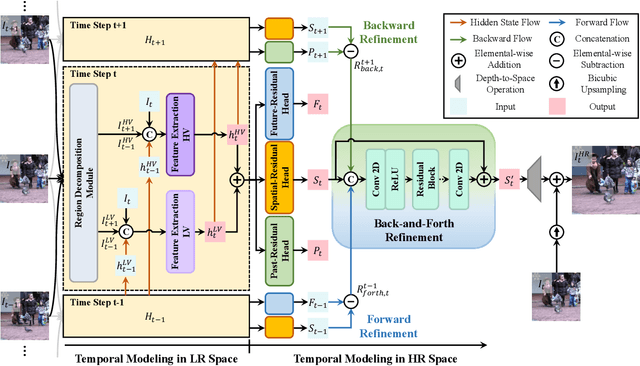
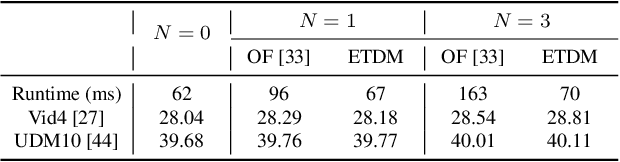
Temporal modeling is crucial for video super-resolution. Most of the video super-resolution methods adopt the optical flow or deformable convolution for explicitly motion compensation. However, such temporal modeling techniques increase the model complexity and might fail in case of occlusion or complex motion, resulting in serious distortion and artifacts. In this paper, we propose to explore the role of explicit temporal difference modeling in both LR and HR space. Instead of directly feeding consecutive frames into a VSR model, we propose to compute the temporal difference between frames and divide those pixels into two subsets according to the level of difference. They are separately processed with two branches of different receptive fields in order to better extract complementary information. To further enhance the super-resolution result, not only spatial residual features are extracted, but the difference between consecutive frames in high-frequency domain is also computed. It allows the model to exploit intermediate SR results in both future and past to refine the current SR output. The difference at different time steps could be cached such that information from further distance in time could be propagated to the current frame for refinement. Experiments on several video super-resolution benchmark datasets demonstrate the effectiveness of the proposed method and its favorable performance against state-of-the-art methods.
FoV-Net: Field-of-View Extrapolation Using Self-Attention and Uncertainty
Apr 04, 2022

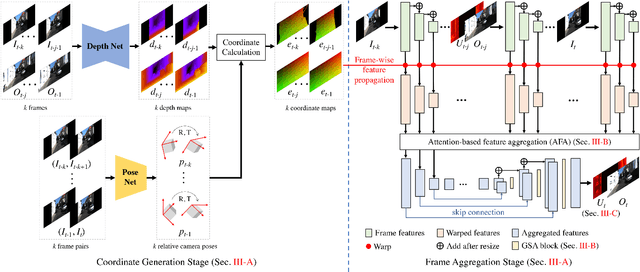
The ability to make educated predictions about their surroundings, and associate them with certain confidence, is important for intelligent systems, like autonomous vehicles and robots. It allows them to plan early and decide accordingly. Motivated by this observation, in this paper we utilize information from a video sequence with a narrow field-of-view to infer the scene at a wider field-of-view. To this end, we propose a temporally consistent field-of-view extrapolation framework, namely FoV-Net, that: (1) leverages 3D information to propagate the observed scene parts from past frames; (2) aggregates the propagated multi-frame information using an attention-based feature aggregation module and a gated self-attention module, simultaneously hallucinating any unobserved scene parts; and (3) assigns an interpretable uncertainty value at each pixel. Extensive experiments show that FoV-Net does not only extrapolate the temporally consistent wide field-of-view scene better than existing alternatives, but also provides the associated uncertainty which may benefit critical decision-making downstream applications. Project page is at http://charliememory.github.io/RAL21_FoV.
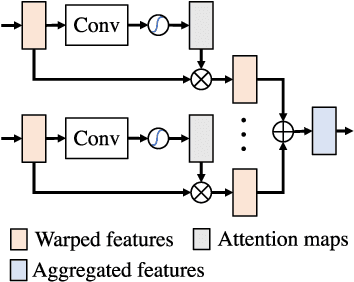
TimeReplayer: Unlocking the Potential of Event Cameras for Video Interpolation
Mar 25, 2022

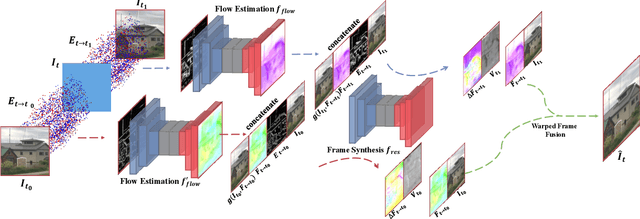
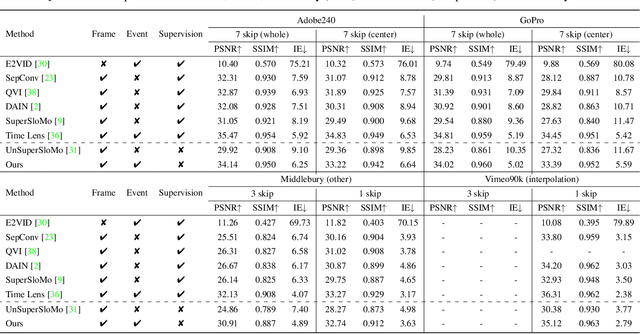
Recording fast motion in a high FPS (frame-per-second) requires expensive high-speed cameras. As an alternative, interpolating low-FPS videos from commodity cameras has attracted significant attention. If only low-FPS videos are available, motion assumptions (linear or quadratic) are necessary to infer intermediate frames, which fail to model complex motions. Event camera, a new camera with pixels producing events of brightness change at the temporal resolution of $\mu s$ $(10^{-6}$ second $)$, is a game-changing device to enable video interpolation at the presence of arbitrarily complex motion. Since event camera is a novel sensor, its potential has not been fulfilled due to the lack of processing algorithms. The pioneering work Time Lens introduced event cameras to video interpolation by designing optical devices to collect a large amount of paired training data of high-speed frames and events, which is too costly to scale. To fully unlock the potential of event cameras, this paper proposes a novel TimeReplayer algorithm to interpolate videos captured by commodity cameras with events. It is trained in an unsupervised cycle-consistent style, canceling the necessity of high-speed training data and bringing the additional ability of video extrapolation. Its state-of-the-art results and demo videos in supplementary reveal the promising future of event-based vision.
Learning Enriched Illuminants for Cross and Single Sensor Color Constancy
Mar 21, 2022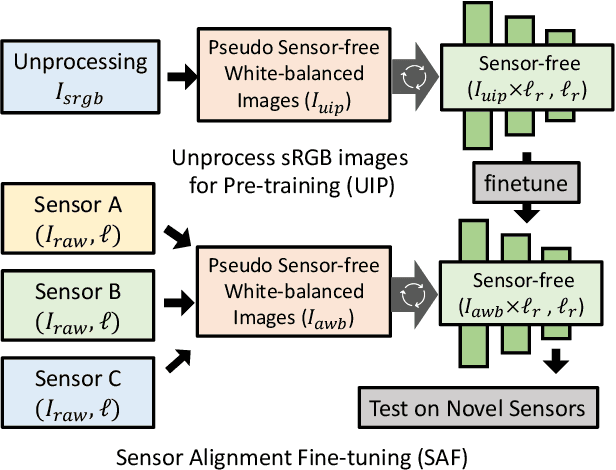
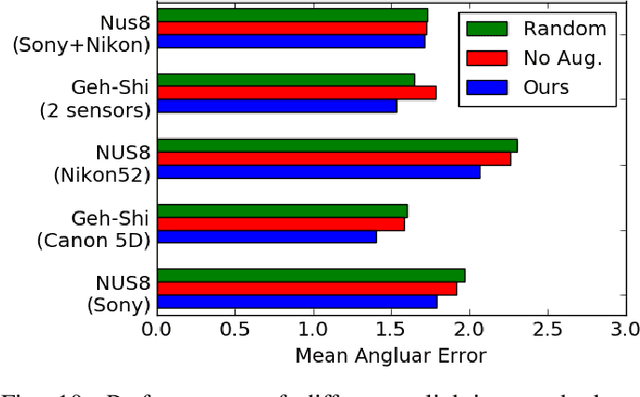

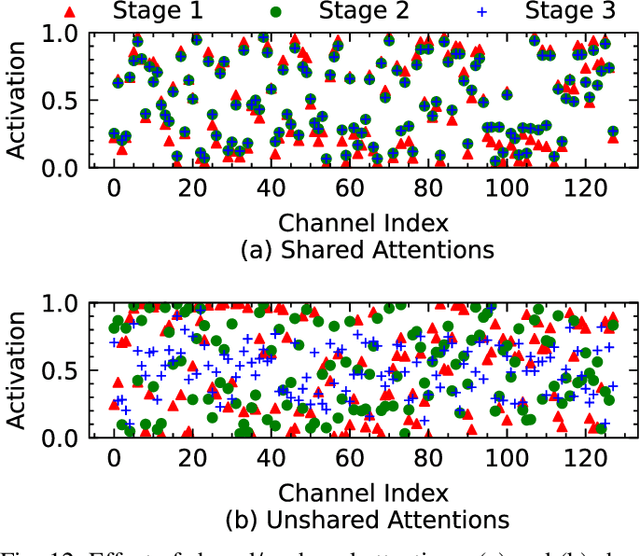
Color constancy aims to restore the constant colors of a scene under different illuminants. However, due to the existence of camera spectral sensitivity, the network trained on a certain sensor, cannot work well on others. Also, since the training datasets are collected in certain environments, the diversity of illuminants is limited for complex real world prediction. In this paper, we tackle these problems via two aspects. First, we propose cross-sensor self-supervised training to train the network. In detail, we consider both the general sRGB images and the white-balanced RAW images from current available datasets as the white-balanced agents. Then, we train the network by randomly sampling the artificial illuminants in a sensor-independent manner for scene relighting and supervision. Second, we analyze a previous cascaded framework and present a more compact and accurate model by sharing the backbone parameters with learning attention specifically. Experiments show that our cross-sensor model and single-sensor model outperform other state-of-the-art methods by a large margin on cross and single sensor evaluations, respectively, with only 16% parameters of the previous best model.
Class-Balanced Pixel-Level Self-Labeling for Domain Adaptive Semantic Segmentation
Mar 18, 2022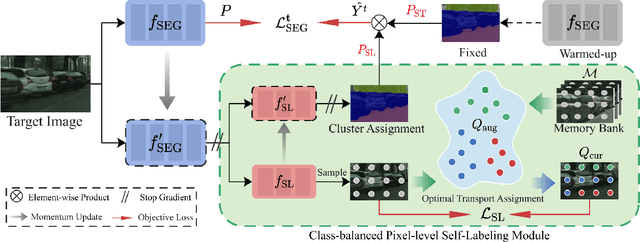
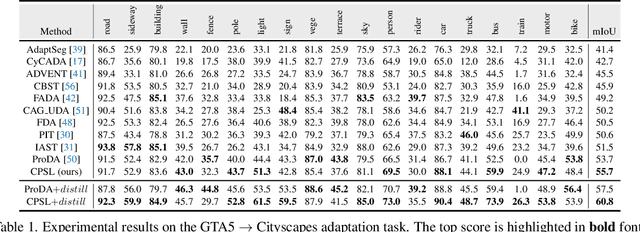
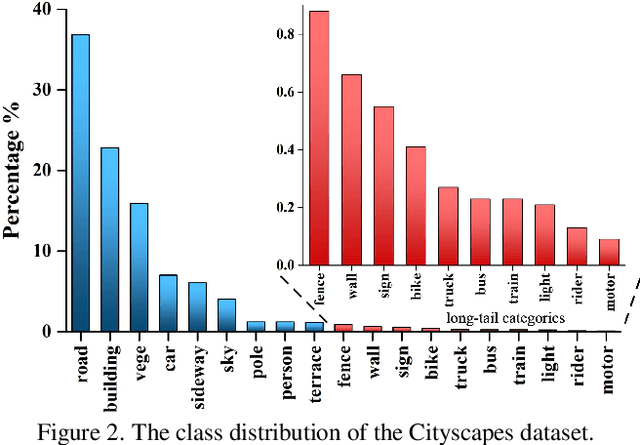

Domain adaptive semantic segmentation aims to learn a model with the supervision of source domain data, and produce satisfactory dense predictions on unlabeled target domain. One popular solution to this challenging task is self-training, which selects high-scoring predictions on target samples as pseudo labels for training. However, the produced pseudo labels often contain much noise because the model is biased to source domain as well as majority categories. To address the above issues, we propose to directly explore the intrinsic pixel distributions of target domain data, instead of heavily relying on the source domain. Specifically, we simultaneously cluster pixels and rectify pseudo labels with the obtained cluster assignments. This process is done in an online fashion so that pseudo labels could co-evolve with the segmentation model without extra training rounds. To overcome the class imbalance problem on long-tailed categories, we employ a distribution alignment technique to enforce the marginal class distribution of cluster assignments to be close to that of pseudo labels. The proposed method, namely Class-balanced Pixel-level Self-Labeling (CPSL), improves the segmentation performance on target domain over state-of-the-arts by a large margin, especially on long-tailed categories.
Transformer-based Network for RGB-D Saliency Detection
Dec 01, 2021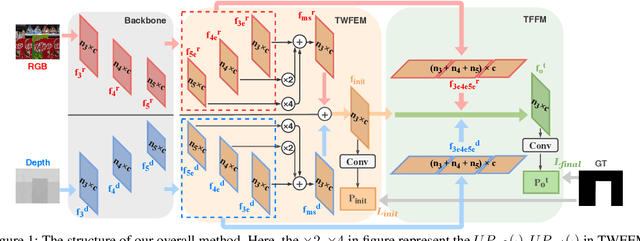
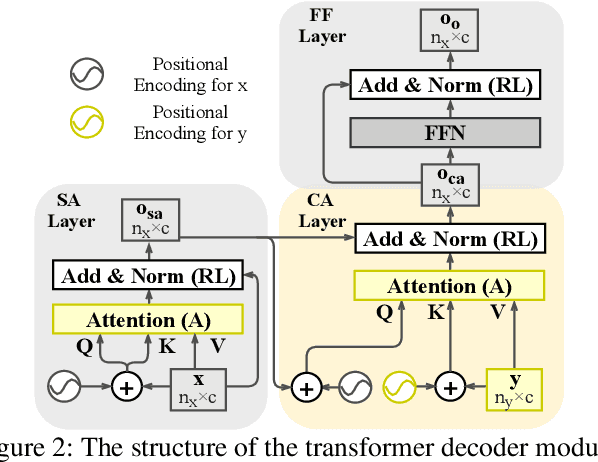
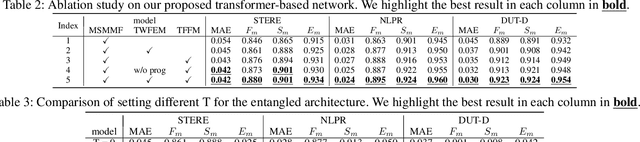
RGB-D saliency detection integrates information from both RGB images and depth maps to improve prediction of salient regions under challenging conditions. The key to RGB-D saliency detection is to fully mine and fuse information at multiple scales across the two modalities. Previous approaches tend to apply the multi-scale and multi-modal fusion separately via local operations, which fails to capture long-range dependencies. Here we propose a transformer-based network to address this issue. Our proposed architecture is composed of two modules: a transformer-based within-modality feature enhancement module (TWFEM) and a transformer-based feature fusion module (TFFM). TFFM conducts a sufficient feature fusion by integrating features from multiple scales and two modalities over all positions simultaneously. TWFEM enhances feature on each scale by selecting and integrating complementary information from other scales within the same modality before TFFM. We show that transformer is a uniform operation which presents great efficacy in both feature fusion and feature enhancement, and simplifies the model design. Extensive experimental results on six benchmark datasets demonstrate that our proposed network performs favorably against state-of-the-art RGB-D saliency detection methods.
Motion Deblurring with Real Events
Sep 28, 2021
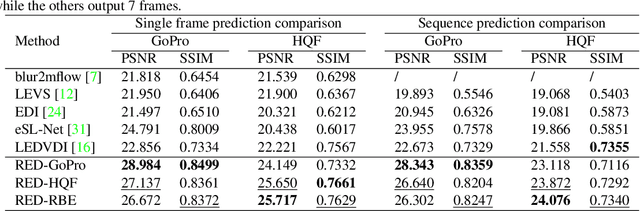
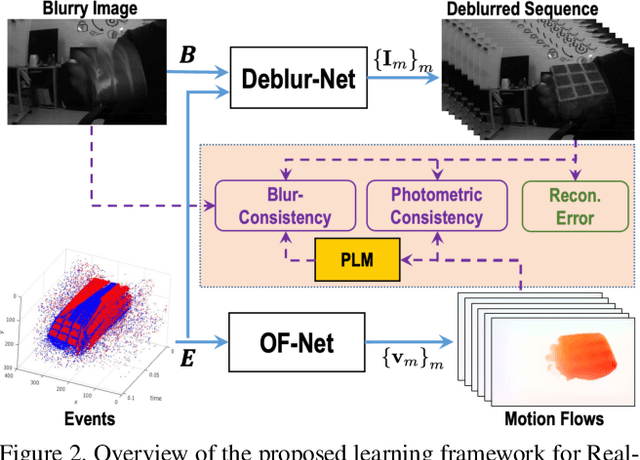
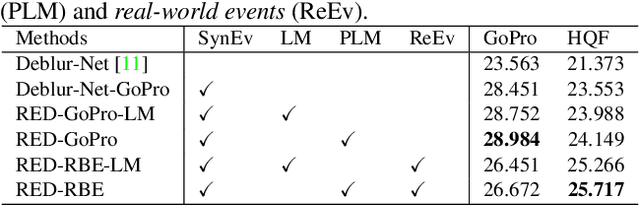
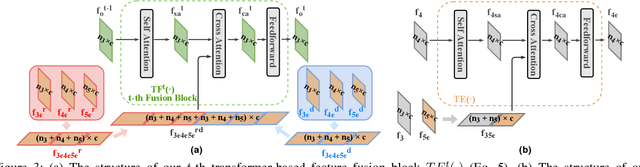
In this paper, we propose an end-to-end learning framework for event-based motion deblurring in a self-supervised manner, where real-world events are exploited to alleviate the performance degradation caused by data inconsistency. To achieve this end, optical flows are predicted from events, with which the blurry consistency and photometric consistency are exploited to enable self-supervision on the deblurring network with real-world data. Furthermore, a piece-wise linear motion model is proposed to take into account motion non-linearities and thus leads to an accurate model for the physical formation of motion blurs in the real-world scenario. Extensive evaluation on both synthetic and real motion blur datasets demonstrates that the proposed algorithm bridges the gap between simulated and real-world motion blurs and shows remarkable performance for event-based motion deblurring in real-world scenarios.