 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
Deep k-grouping: An Unsupervised Learning Framework for Combinatorial Optimization on Graphs and Hypergraphs
May 27, 2025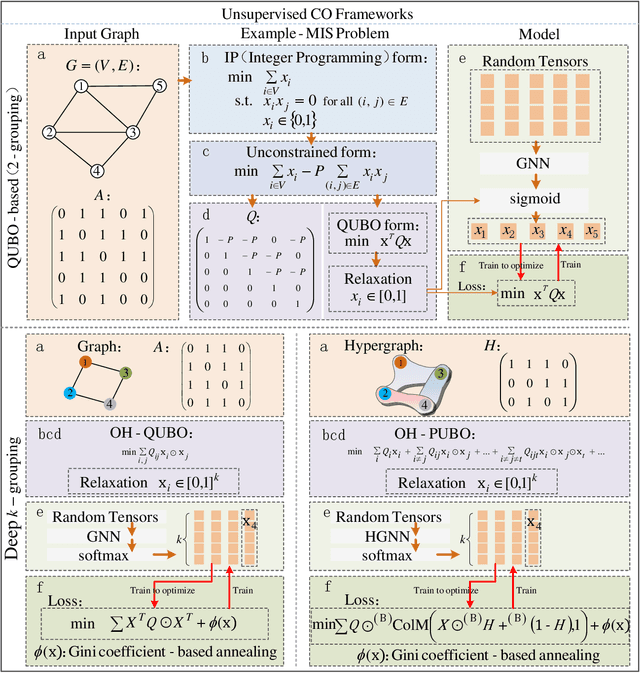

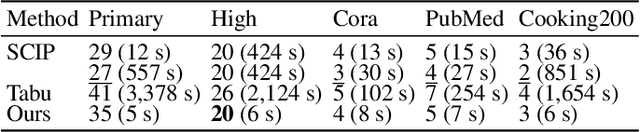
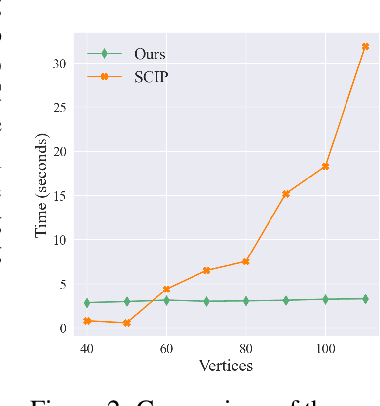
Along with AI computing shining in scientific discovery, its potential in the combinatorial optimization (CO) domain has also emerged in recent years. Yet, existing unsupervised neural network solvers struggle to solve $k$-grouping problems (e.g., coloring, partitioning) on large-scale graphs and hypergraphs, due to limited computational frameworks. In this work, we propose Deep $k$-grouping, an unsupervised learning-based CO framework. Specifically, we contribute: Novel one-hot encoded polynomial unconstrained binary optimization (OH-PUBO), a formulation for modeling k-grouping problems on graphs and hypergraphs (e.g., graph/hypergraph coloring and partitioning); GPU-accelerated algorithms for large-scale k-grouping CO problems. Deep $k$-grouping employs the relaxation of large-scale OH-PUBO objectives as differentiable loss functions and trains to optimize them in an unsupervised manner. To ensure scalability, it leverages GPU-accelerated algorithms to unify the training pipeline; A Gini coefficient-based continuous relaxation annealing strategy to enforce discreteness of solutions while preventing convergence to local optima. Experimental results demonstrate that Deep $k$-grouping outperforms existing neural network solvers and classical heuristics such as SCIP and Tabu.
BIPNN: Learning to Solve Binary Integer Programming via Hypergraph Neural Networks
May 27, 2025



Binary (0-1) integer programming (BIP) is pivotal in scientific domains requiring discrete decision-making. As the advance of AI computing, recent works explore neural network-based solvers for integer linear programming (ILP) problems. Yet, they lack scalability for tackling nonlinear challenges. To handle nonlinearities, state-of-the-art Branch-and-Cut solvers employ linear relaxations, leading to exponential growth in auxiliary variables and severe computation limitations. To overcome these limitations, we propose BIPNN (Binary Integer Programming Neural Network), an unsupervised learning framework to solve nonlinear BIP problems via hypergraph neural networks (HyperGNN). Specifically, BIPNN reformulates BIPs-constrained, discrete, and nonlinear (sin, log, exp) optimization problems-into unconstrained, differentiable, and polynomial loss functions. The reformulation stems from the observation of a precise one-to-one mapping between polynomial BIP objectives and hypergraph structures, enabling the unsupervised training of HyperGNN to optimize BIP problems in an end-to-end manner. On this basis, we propose a GPU-accelerated and continuous-annealing-enhanced training pipeline for BIPNN. The pipeline enables BIPNN to optimize large-scale nonlinear terms in BIPs fully in parallel via straightforward gradient descent, thus significantly reducing the training cost while ensuring the generation of discrete, high-quality solutions. Extensive experiments on synthetic and real-world datasets highlight the superiority of our approach.
DISTA-Net: Dynamic Closely-Spaced Infrared Small Target Unmixing
May 25, 2025Resolving closely-spaced small targets in dense clusters presents a significant challenge in infrared imaging, as the overlapping signals hinder precise determination of their quantity, sub-pixel positions, and radiation intensities. While deep learning has advanced the field of infrared small target detection, its application to closely-spaced infrared small targets has not yet been explored. This gap exists primarily due to the complexity of separating superimposed characteristics and the lack of an open-source infrastructure. In this work, we propose the Dynamic Iterative Shrinkage Thresholding Network (DISTA-Net), which reconceptualizes traditional sparse reconstruction within a dynamic framework. DISTA-Net adaptively generates convolution weights and thresholding parameters to tailor the reconstruction process in real time. To the best of our knowledge, DISTA-Net is the first deep learning model designed specifically for the unmixing of closely-spaced infrared small targets, achieving superior sub-pixel detection accuracy. Moreover, we have established the first open-source ecosystem to foster further research in this field. This ecosystem comprises three key components: (1) CSIST-100K, a publicly available benchmark dataset; (2) CSO-mAP, a custom evaluation metric for sub-pixel detection; and (3) GrokCSO, an open-source toolkit featuring DISTA-Net and other models. Our code and dataset are available at https://github.com/GrokCV/GrokCSO.
Understanding and Mitigating Overrefusal in LLMs from an Unveiling Perspective of Safety Decision Boundary
May 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet they often refuse to answer legitimate queries-a phenomenon known as overrefusal. Overrefusal typically stems from over-conservative safety alignment, causing models to treat many reasonable prompts as potentially risky. To systematically understand this issue, we probe and leverage the models'safety decision boundaries to analyze and mitigate overrefusal. Our findings reveal that overrefusal is closely tied to misalignment at these boundary regions, where models struggle to distinguish subtle differences between benign and harmful content. Building on these insights, we present RASS, an automated framework for prompt generation and selection that strategically targets overrefusal prompts near the safety boundary. By harnessing steering vectors in the representation space, RASS efficiently identifies and curates boundary-aligned prompts, enabling more effective and targeted mitigation of overrefusal. This approach not only provides a more precise and interpretable view of model safety decisions but also seamlessly extends to multilingual scenarios.We have explored the safety decision boundaries of various LLMs and construct the MORBench evaluation set to facilitate robust assessment of model safety and helpfulness across multiple languages. Code and datasets will be released at https://anonymous.4open.science/r/RASS-80D3.
$\text{R}^2\text{ec}$: Towards Large Recommender Models with Reasoning
May 22, 2025Large recommender models have extended LLMs as powerful recommenders via encoding or item generation, and recent breakthroughs in LLM reasoning synchronously motivate the exploration of reasoning in recommendation. Current studies usually position LLMs as external reasoning modules to yield auxiliary thought for augmenting conventional recommendation pipelines. However, such decoupled designs are limited in significant resource cost and suboptimal joint optimization. To address these issues, we propose \name, a unified large recommender model with intrinsic reasoning capabilities. Initially, we reconceptualize the model architecture to facilitate interleaved reasoning and recommendation in the autoregressive process. Subsequently, we propose RecPO, a corresponding reinforcement learning framework that optimizes \name\ both the reasoning and recommendation capabilities simultaneously in a single policy update; RecPO introduces a fused reward scheme that solely leverages recommendation labels to simulate the reasoning capability, eliminating dependency on specialized reasoning annotations. Experiments on three datasets with various baselines verify the effectiveness of \name, showing relative improvements of 68.67\% in Hit@5 and 45.21\% in NDCG@20. Code available at https://github.com/YRYangang/RRec.
Satellites Reveal Mobility: A Commuting Origin-destination Flow Generator for Global Cities
May 21, 2025Commuting Origin-destination~(OD) flows, capturing daily population mobility of citizens, are vital for sustainable development across cities around the world. However, it is challenging to obtain the data due to the high cost of travel surveys and privacy concerns. Surprisingly, we find that satellite imagery, publicly available across the globe, contains rich urban semantic signals to support high-quality OD flow generation, with over 98\% expressiveness of traditional multisource hard-to-collect urban sociodemographic, economics, land use, and point of interest data. This inspires us to design a novel data generator, GlODGen, which can generate OD flow data for any cities of interest around the world. Specifically, GlODGen first leverages Vision-Language Geo-Foundation Models to extract urban semantic signals related to human mobility from satellite imagery. These features are then combined with population data to form region-level representations, which are used to generate OD flows via graph diffusion models. Extensive experiments on 4 continents and 6 representative cities show that GlODGen has great generalizability across diverse urban environments on different continents and can generate OD flow data for global cities highly consistent with real-world mobility data. We implement GlODGen as an automated tool, seamlessly integrating data acquisition and curation, urban semantic feature extraction, and OD flow generation together. It has been released at https://github.com/tsinghua-fib-lab/generate-od-pubtools.
EAVIT: Efficient and Accurate Human Value Identification from Text data via LLMs
May 19, 2025The rapid evolution of large language models (LLMs) has revolutionized various fields, including the identification and discovery of human values within text data. While traditional NLP models, such as BERT, have been employed for this task, their ability to represent textual data is significantly outperformed by emerging LLMs like GPTs. However, the performance of online LLMs often degrades when handling long contexts required for value identification, which also incurs substantial computational costs. To address these challenges, we propose EAVIT, an efficient and accurate framework for human value identification that combines the strengths of both locally fine-tunable and online black-box LLMs. Our framework employs a value detector - a small, local language model - to generate initial value estimations. These estimations are then used to construct concise input prompts for online LLMs, enabling accurate final value identification. To train the value detector, we introduce explanation-based training and data generation techniques specifically tailored for value identification, alongside sampling strategies to optimize the brevity of LLM input prompts. Our approach effectively reduces the number of input tokens by up to 1/6 compared to directly querying online LLMs, while consistently outperforming traditional NLP methods and other LLM-based strategies.
Towards Budget-Friendly Model-Agnostic Explanation Generation for Large Language Models
May 18, 2025



With Large language models (LLMs) becoming increasingly prevalent in various applications, the need for interpreting their predictions has become a critical challenge. As LLMs vary in architecture and some are closed-sourced, model-agnostic techniques show great promise without requiring access to the model's internal parameters. However, existing model-agnostic techniques need to invoke LLMs many times to gain sufficient samples for generating faithful explanations, which leads to high economic costs. In this paper, we show that it is practical to generate faithful explanations for large-scale LLMs by sampling from some budget-friendly models through a series of empirical studies. Moreover, we show that such proxy explanations also perform well on downstream tasks. Our analysis provides a new paradigm of model-agnostic explanation methods for LLMs, by including information from budget-friendly models.
UrbanMind: Urban Dynamics Prediction with Multifaceted Spatial-Temporal Large Language Models
May 16, 2025Understanding and predicting urban dynamics is crucial for managing transportation systems, optimizing urban planning, and enhancing public services. While neural network-based approaches have achieved success, they often rely on task-specific architectures and large volumes of data, limiting their ability to generalize across diverse urban scenarios. Meanwhile, Large Language Models (LLMs) offer strong reasoning and generalization capabilities, yet their application to spatial-temporal urban dynamics remains underexplored. Existing LLM-based methods struggle to effectively integrate multifaceted spatial-temporal data and fail to address distributional shifts between training and testing data, limiting their predictive reliability in real-world applications. To bridge this gap, we propose UrbanMind, a novel spatial-temporal LLM framework for multifaceted urban dynamics prediction that ensures both accurate forecasting and robust generalization. At its core, UrbanMind introduces Muffin-MAE, a multifaceted fusion masked autoencoder with specialized masking strategies that capture intricate spatial-temporal dependencies and intercorrelations among multifaceted urban dynamics. Additionally, we design a semantic-aware prompting and fine-tuning strategy that encodes spatial-temporal contextual details into prompts, enhancing LLMs' ability to reason over spatial-temporal patterns. To further improve generalization, we introduce a test time adaptation mechanism with a test data reconstructor, enabling UrbanMind to dynamically adjust to unseen test data by reconstructing LLM-generated embeddings. Extensive experiments on real-world urban datasets across multiple cities demonstrate that UrbanMind consistently outperforms state-of-the-art baselines, achieving high accuracy and robust generalization, even in zero-shot settings.