 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWASD: Locating Critical Neurons as Sufficient Conditions for Explaining and Controlling LLM Behavior
Mar 19, 2026Precise behavioral control of large language models (LLMs) is critical for complex applications. However, existing methods often incur high training costs, lack natural language controllability, or compromise semantic coherence. To bridge this gap, we propose WASD (unWeaving Actionable Sufficient Directives), a novel framework that explains model behavior by identifying sufficient neural conditions for token generation. Our method represents candidate conditions as neuron-activation predicates and iteratively searches for a minimal set that guarantees the current output under input perturbations. Experiments on SST-2 and CounterFact with the Gemma-2-2B model demonstrate that our approach produces explanations that are more stable, accurate, and concise than conventional attribution graphs. Moreover, through a case study on controlling cross-lingual output generation, we validated the practical effectiveness of WASD in controlling model behavior.
Focus-LIME: Surgical Interpretation of Long-Context Large Language Models via Proxy-Based Neighborhood Selection
Feb 04, 2026As Large Language Models (LLMs) scale to handle massive context windows, achieving surgical feature-level interpretation is essential for high-stakes tasks like legal auditing and code debugging. However, existing local model-agnostic explanation methods face a critical dilemma in these scenarios: feature-based methods suffer from attribution dilution due to high feature dimensionality, thus failing to provide faithful explanations. In this paper, we propose Focus-LIME, a coarse-to-fine framework designed to restore the tractability of surgical interpretation. Focus-LIME utilizes a proxy model to curate the perturbation neighborhood, allowing the target model to perform fine-grained attribution exclusively within the optimized context. Empirical evaluations on long-context benchmarks demonstrate that our method makes surgical explanations practicable and provides faithful explanations to users.
Learning Multi-Stage Pick-and-Place with a Legged Mobile Manipulator
Sep 04, 2025Quadruped-based mobile manipulation presents significant challenges in robotics due to the diversity of required skills, the extended task horizon, and partial observability. After presenting a multi-stage pick-and-place task as a succinct yet sufficiently rich setup that captures key desiderata for quadruped-based mobile manipulation, we propose an approach that can train a visuo-motor policy entirely in simulation, and achieve nearly 80\% success in the real world. The policy efficiently performs search, approach, grasp, transport, and drop into actions, with emerged behaviors such as re-grasping and task chaining. We conduct an extensive set of real-world experiments with ablation studies highlighting key techniques for efficient training and effective sim-to-real transfer. Additional experiments demonstrate deployment across a variety of indoor and outdoor environments. Demo videos and additional resources are available on the project page: https://horizonrobotics.github.io/gail/SLIM.
Towards Budget-Friendly Model-Agnostic Explanation Generation for Large Language Models
May 18, 2025



With Large language models (LLMs) becoming increasingly prevalent in various applications, the need for interpreting their predictions has become a critical challenge. As LLMs vary in architecture and some are closed-sourced, model-agnostic techniques show great promise without requiring access to the model's internal parameters. However, existing model-agnostic techniques need to invoke LLMs many times to gain sufficient samples for generating faithful explanations, which leads to high economic costs. In this paper, we show that it is practical to generate faithful explanations for large-scale LLMs by sampling from some budget-friendly models through a series of empirical studies. Moreover, we show that such proxy explanations also perform well on downstream tasks. Our analysis provides a new paradigm of model-agnostic explanation methods for LLMs, by including information from budget-friendly models.
ConLUX: Concept-Based Local Unified Explanations
Oct 16, 2024



With the rapid advancements of various machine learning models, there is a significant demand for model-agnostic explanation techniques, which can explain these models across different architectures. Mainstream model-agnostic explanation techniques generate local explanations based on basic features (e.g., words for text models and (super-)pixels for image models). However, these explanations often do not align with the decision-making processes of the target models and end-users, resulting in explanations that are unfaithful and difficult for users to understand. On the other hand, concept-based techniques provide explanations based on high-level features (e.g., topics for text models and objects for image models), but most are model-specific or require additional pre-defined external concept knowledge. To address this limitation, we propose \toolname, a general framework to provide concept-based local explanations for any machine learning models. Our key insight is that we can automatically extract high-level concepts from large pre-trained models, and uniformly extend existing local model-agnostic techniques to provide unified concept-based explanations. We have instantiated \toolname on four different types of explanation techniques: LIME, Kernel SHAP, Anchor, and LORE, and applied these techniques to text and image models. Our evaluation results demonstrate that 1) compared to the vanilla versions, \toolname offers more faithful explanations and makes them more understandable to users, and 2) by offering multiple forms of explanations, \toolname outperforms state-of-the-art concept-based explanation techniques specifically designed for text and image models, respectively.
VONet: Unsupervised Video Object Learning With Parallel U-Net Attention and Object-wise Sequential VAE
Jan 20, 2024Unsupervised video object learning seeks to decompose video scenes into structural object representations without any supervision from depth, optical flow, or segmentation. We present VONet, an innovative approach that is inspired by MONet. While utilizing a U-Net architecture, VONet employs an efficient and effective parallel attention inference process, generating attention masks for all slots simultaneously. Additionally, to enhance the temporal consistency of each mask across consecutive video frames, VONet develops an object-wise sequential VAE framework. The integration of these innovative encoder-side techniques, in conjunction with an expressive transformer-based decoder, establishes VONet as the leading unsupervised method for object learning across five MOVI datasets, encompassing videos of diverse complexities. Code is available at https://github.com/hnyu/vonet.
Policy Expansion for Bridging Offline-to-Online Reinforcement Learning
Feb 02, 2023



Pre-training with offline data and online fine-tuning using reinforcement learning is a promising strategy for learning control policies by leveraging the best of both worlds in terms of sample efficiency and performance. One natural approach is to initialize the policy for online learning with the one trained offline. In this work, we introduce a policy expansion scheme for this task. After learning the offline policy, we use it as one candidate policy in a policy set. We then expand the policy set with another policy which will be responsible for further learning. The two policies will be composed in an adaptive manner for interacting with the environment. With this approach, the policy previously learned offline is fully retained during online learning, thus mitigating the potential issues such as destroying the useful behaviors of the offline policy in the initial stage of online learning while allowing the offline policy participate in the exploration naturally in an adaptive manner. Moreover, new useful behaviors can potentially be captured by the newly added policy through learning. Experiments are conducted on a number of tasks and the results demonstrate the effectiveness of the proposed approach.
Generative Planning for Temporally Coordinated Exploration in Reinforcement Learning
Feb 03, 2022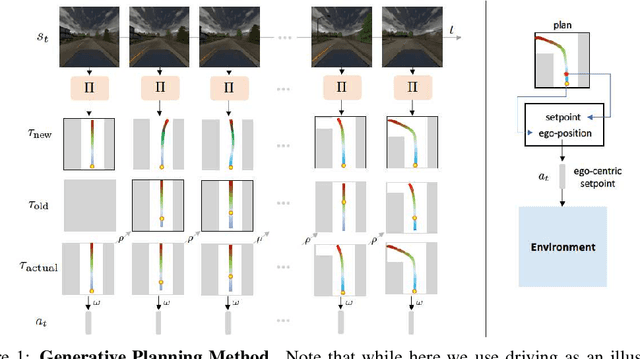

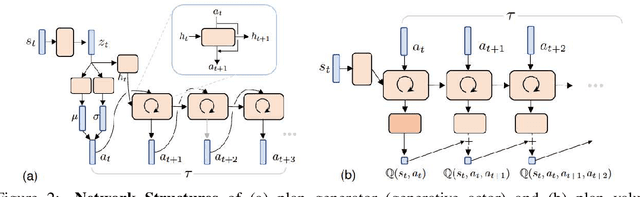
Standard model-free reinforcement learning algorithms optimize a policy that generates the action to be taken in the current time step in order to maximize expected future return. While flexible, it faces difficulties arising from the inefficient exploration due to its single step nature. In this work, we present Generative Planning method (GPM), which can generate actions not only for the current step, but also for a number of future steps (thus termed as generative planning). This brings several benefits to GPM. Firstly, since GPM is trained by maximizing value, the plans generated from it can be regarded as intentional action sequences for reaching high value regions. GPM can therefore leverage its generated multi-step plans for temporally coordinated exploration towards high value regions, which is potentially more effective than a sequence of actions generated by perturbing each action at single step level, whose consistent movement decays exponentially with the number of exploration steps. Secondly, starting from a crude initial plan generator, GPM can refine it to be adaptive to the task, which, in return, benefits future explorations. This is potentially more effective than commonly used action-repeat strategy, which is non-adaptive in its form of plans. Additionally, since the multi-step plan can be interpreted as the intent of the agent from now to a span of time period into the future, it offers a more informative and intuitive signal for interpretation. Experiments are conducted on several benchmark environments and the results demonstrated its effectiveness compared with several baseline methods.
Do You Need the Entropy Reward (in Practice)?
Jan 28, 2022
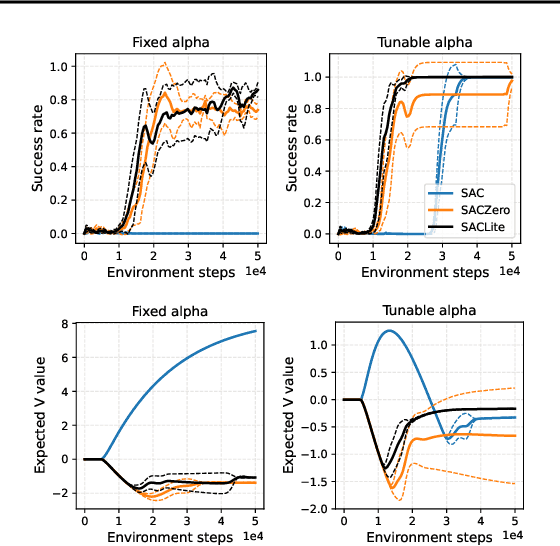

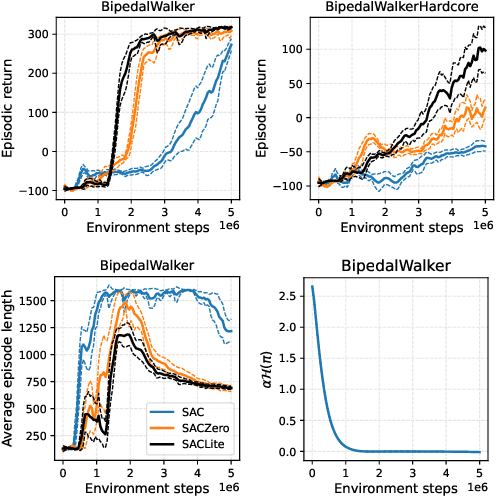
Maximum entropy (MaxEnt) RL maximizes a combination of the original task reward and an entropy reward. It is believed that the regularization imposed by entropy, on both policy improvement and policy evaluation, together contributes to good exploration, training convergence, and robustness of learned policies. This paper takes a closer look at entropy as an intrinsic reward, by conducting various ablation studies on soft actor-critic (SAC), a popular representative of MaxEnt RL. Our findings reveal that in general, entropy rewards should be applied with caution to policy evaluation. On one hand, the entropy reward, like any other intrinsic reward, could obscure the main task reward if it is not properly managed. We identify some failure cases of the entropy reward especially in episodic Markov decision processes (MDPs), where it could cause the policy to be overly optimistic or pessimistic. On the other hand, our large-scale empirical study shows that using entropy regularization alone in policy improvement, leads to comparable or even better performance and robustness than using it in both policy improvement and policy evaluation. Based on these observations, we recommend either normalizing the entropy reward to a zero mean (SACZero), or simply removing it from policy evaluation (SACLite) for better practical results.
Towards Safe Reinforcement Learning with a Safety Editor Policy
Jan 28, 2022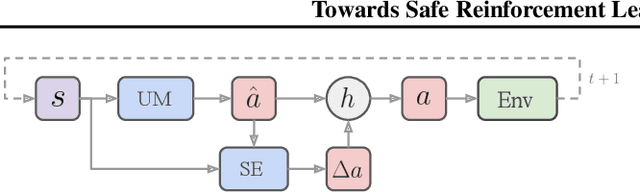
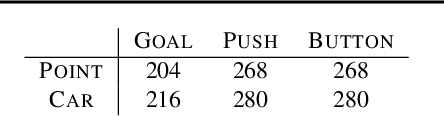
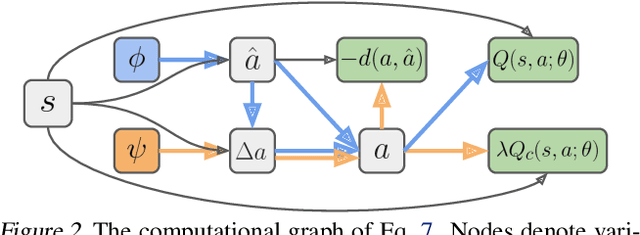

We consider the safe reinforcement learning (RL) problem of maximizing utility while satisfying provided constraints. Since we do not assume any prior knowledge or pre-training of the safety concept, we are interested in asymptotic constraint satisfaction. A popular approach in this line of research is to combine the Lagrangian method with a model-free RL algorithm to adjust the weight of the constraint reward dynamically. It relies on a single policy to handle the conflict between utility and constraint rewards, which is often challenging. Inspired by the safety layer design (Dalal et al., 2018), we propose to separately learn a safety editor policy that transforms potentially unsafe actions output by a utility maximizer policy into safe ones. The safety editor is trained to maximize the constraint reward while minimizing a hinge loss of the utility Q values of actions before and after the edit. On 12 custom Safety Gym (Ray et al., 2019) tasks and 2 safe racing tasks with very harsh constraint thresholds, our approach demonstrates outstanding utility performance while complying with the constraints. Ablation studies reveal that our two-policy design is critical. Simply doubling the model capacity of typical single-policy approaches will not lead to comparable results. The Q hinge loss is also important in certain circumstances, and replacing it with the usual L2 distance could fail badly.