 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Mar 10, 2026Self-evolving has emerged as a key paradigm for improving foundational models such as Large Language Models (LLMs) and Vision Language Models (VLMs) with minimal human intervention. While recent approaches have demonstrated that LLM agents can self-evolve from scratch with little to no data, VLMs introduce an additional visual modality that typically requires at least some seed data, such as images, to bootstrap the self-evolution process. In this work, we present Multi-model Multimodal Zero (MM-Zero), the first RL-based framework to achieve zero-data self-evolution for VLM reasoning. Moving beyond prior dual-role (Proposer and Solver) setups, MM-Zero introduces a multi-role self-evolving training framework comprising three specialized roles: a Proposer that generates abstract visual concepts and formulates questions; a Coder that translates these concepts into executable code (e.g., Python, SVG) to render visual images; and a Solver that performs multimodal reasoning over the generated visual content. All three roles are initialized from the same base model and trained using Group Relative Policy Optimization (GRPO), with carefully designed reward mechanisms that integrate execution feedback, visual verification, and difficulty balancing. Our experiments show that MM-Zero improves VLM reasoning performance across a wide range of multimodal benchmarks. MM-Zero establishes a scalable path toward self-evolving multi-model systems for multimodal models, extending the frontier of self-improvement beyond the conventional two-model paradigm.
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Feb 12, 2026Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose \textit{GigaBrain-0.5M*}, a VLA model trained via world model-based reinforcement learning. Built upon \textit{GigaBrain-0.5}, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. \textit{GigaBrain-0.5M*} further integrates world model-based reinforcement learning via \textit{RAMP} (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that \textit{RAMP} achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30\% on challenging tasks including \texttt{Laundry Folding}, \texttt{Box Packing}, and \texttt{Espresso Preparation}. Critically, \textit{GigaBrain-0.5M$^*$} exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our \href{https://gigabrain05m.github.io}{project page}.
Towards Long-Horizon Interpretability: Efficient and Faithful Multi-Token Attribution for Reasoning LLMs
Feb 02, 2026Token attribution methods provide intuitive explanations for language model outputs by identifying causally important input tokens. However, as modern LLMs increasingly rely on extended reasoning chains, existing schemes face two critical challenges: (1) efficiency bottleneck, where attributing a target span of M tokens within a context of length N requires O(M*N) operations, making long-context attribution prohibitively slow; and (2) faithfulness drop, where intermediate reasoning tokens absorb attribution mass, preventing importance from propagating back to the original input. To address these, we introduce FlashTrace, an efficient multi-token attribution method that employs span-wise aggregation to compute attribution over multi-token targets in a single pass, while maintaining faithfulness. Moreover, we design a recursive attribution mechanism that traces importance through intermediate reasoning chains back to source inputs. Extensive experiments on long-context retrieval (RULER) and multi-step reasoning (MATH, MorehopQA) tasks demonstrate that FlashTrace achieves over 130x speedup over existing baselines while maintaining superior faithfulness. We further analyze the dynamics of recursive attribution, showing that even a single recursive hop improves faithfulness by tracing importance through the reasoning chain.
First Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Confidence Adjusted Surprise Measure for Active Resourceful Trials (CA-SMART): A Data-driven Active Learning Framework for Accelerating Material Discovery under Resource Constraints
Mar 27, 2025Accelerating the discovery and manufacturing of advanced materials with specific properties is a critical yet formidable challenge due to vast search space, high costs of experiments, and time-intensive nature of material characterization. In recent years, active learning, where a surrogate machine learning (ML) model mimics the scientific discovery process of a human scientist, has emerged as a promising approach to address these challenges by guiding experimentation toward high-value outcomes with a limited budget. Among the diverse active learning philosophies, the concept of surprise (capturing the divergence between expected and observed outcomes) has demonstrated significant potential to drive experimental trials and refine predictive models. Scientific discovery often stems from surprise thereby making it a natural driver to guide the search process. Despite its promise, prior studies leveraging surprise metrics such as Shannon and Bayesian surprise lack mechanisms to account for prior confidence, leading to excessive exploration of uncertain regions that may not yield useful information. To address this, we propose the Confidence-Adjusted Surprise Measure for Active Resourceful Trials (CA-SMART), a novel Bayesian active learning framework tailored for optimizing data-driven experimentation. On a high level, CA-SMART incorporates Confidence-Adjusted Surprise (CAS) to dynamically balance exploration and exploitation by amplifying surprises in regions where the model is more certain while discounting them in highly uncertain areas. We evaluated CA-SMART on two benchmark functions (Six-Hump Camelback and Griewank) and in predicting the fatigue strength of steel. The results demonstrate superior accuracy and efficiency compared to traditional surprise metrics, standard Bayesian Optimization (BO) acquisition functions and conventional ML methods.
In-Situ Melt Pool Characterization via Thermal Imaging for Defect Detection in Directed Energy Deposition Using Vision Transformers
Nov 18, 2024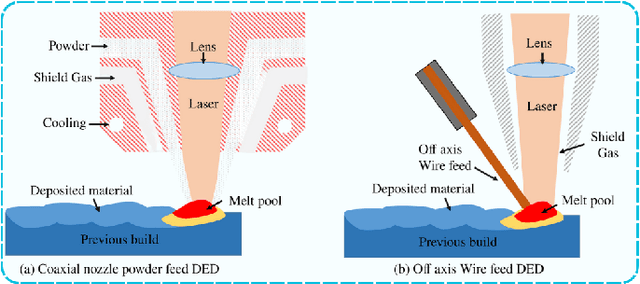
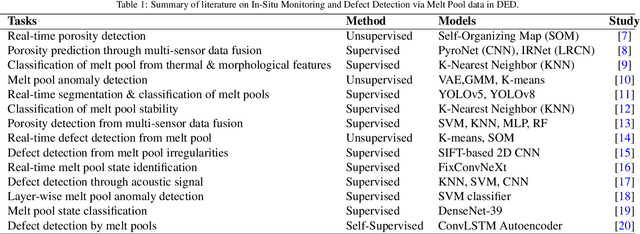

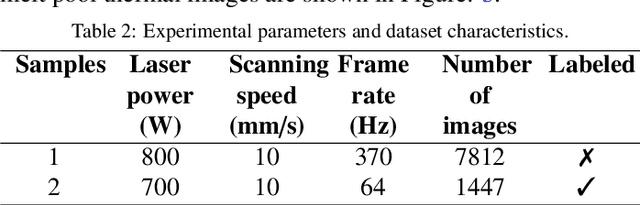
Directed Energy Deposition (DED) offers significant potential for manufacturing complex and multi-material parts. However, internal defects such as porosity and cracks can compromise mechanical properties and overall performance. This study focuses on in-situ monitoring and characterization of melt pools associated with porosity, aiming to improve defect detection and quality control in DED-printed parts. Traditional machine learning approaches for defect identification rely on extensive labeled datasets, often scarce and expensive to generate in real-world manufacturing. To address this, our framework employs self-supervised learning on unlabeled melt pool data using a Vision Transformer-based Masked Autoencoder (MAE) to produce highly representative embeddings. These fine-tuned embeddings are leveraged via transfer learning to train classifiers on a limited labeled dataset, enabling the effective identification of melt pool anomalies. We evaluate two classifiers: (1) a Vision Transformer (ViT) classifier utilizing the fine-tuned MAE Encoder's parameters and (2) the fine-tuned MAE Encoder combined with an MLP classifier head. Our framework achieves overall accuracy ranging from 95.44% to 99.17% and an average F1 score exceeding 80%, with the ViT Classifier slightly outperforming the MAE Encoder Classifier. This demonstrates the scalability and cost-effectiveness of our approach for automated quality control in DED, effectively detecting defects with minimal labeled data.
Language-guided Robust Navigation for Mobile Robots in Dynamically-changing Environments
Sep 28, 2024



In this paper, we develop an embodied AI system for human-in-the-loop navigation with a wheeled mobile robot. We propose a direct yet effective method of monitoring the robot's current plan to detect changes in the environment that impact the intended trajectory of the robot significantly and then query a human for feedback. We also develop a means to parse human feedback expressed in natural language into local navigation waypoints and integrate it into a global planning system, by leveraging a map of semantic features and an aligned obstacle map. Extensive testing in simulation and physical hardware experiments with a resource-constrained wheeled robot tasked to navigate in a real-world environment validate the efficacy and robustness of our method. This work can support applications like precision agriculture and construction, where persistent monitoring of the environment provides a human with information about the environment state.
Hierarchical Tri-manual Planning for Vision-assisted Fruit Harvesting with Quadrupedal Robots
Sep 25, 2024



This paper addresses the challenge of developing a multi-arm quadrupedal robot capable of efficiently harvesting fruit in complex, natural environments. To overcome the inherent limitations of traditional bimanual manipulation, we introduce the first three-arm quadrupedal robot LocoHarv-3 and propose a novel hierarchical tri-manual planning approach, enabling automated fruit harvesting with collision-free trajectories. Our comprehensive semi-autonomous framework integrates teleoperation, supported by LiDAR-based odometry and mapping, with learning-based visual perception for accurate fruit detection and pose estimation. Validation is conducted through a series of controlled indoor experiments using motion capture and extensive field tests in natural settings. Results demonstrate a 90\% success rate in in-lab settings with a single attempt, and field trials further verify the system's robustness and efficiency in more challenging real-world environments.