 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
Oct 06, 2025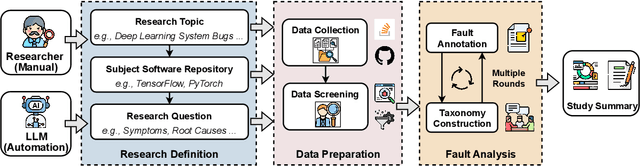

Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.
Critical Nodes Identification in Complex Networks: A Survey
Jul 08, 2025Complex networks have become essential tools for understanding diverse phenomena in social systems, traffic systems, biomolecular systems, and financial systems. Identifying critical nodes is a central theme in contemporary research, serving as a vital bridge between theoretical foundations and practical applications. Nevertheless, the intrinsic complexity and structural heterogeneity characterizing real-world networks, with particular emphasis on dynamic and higher-order networks, present substantial obstacles to the development of universal frameworks for critical node identification. This paper provides a comprehensive review of critical node identification techniques, categorizing them into seven main classes: centrality, critical nodes deletion problem, influence maximization, network control, artificial intelligence, higher-order and dynamic methods. Our review bridges the gaps in existing surveys by systematically classifying methods based on their methodological foundations and practical implications, and by highlighting their strengths, limitations, and applicability across different network types. Our work enhances the understanding of critical node research by identifying key challenges, such as algorithmic universality, real-time evaluation in dynamic networks, analysis of higher-order structures, and computational efficiency in large-scale networks. The structured synthesis consolidates current progress and highlights open questions, particularly in modeling temporal dynamics, advancing efficient algorithms, integrating machine learning approaches, and developing scalable and interpretable metrics for complex systems.
EvDetMAV: Generalized MAV Detection from Moving Event Cameras
Jun 24, 2025



Existing micro aerial vehicle (MAV) detection methods mainly rely on the target's appearance features in RGB images, whose diversity makes it difficult to achieve generalized MAV detection. We notice that different types of MAVs share the same distinctive features in event streams due to their high-speed rotating propellers, which are hard to see in RGB images. This paper studies how to detect different types of MAVs from an event camera by fully exploiting the features of propellers in the original event stream. The proposed method consists of three modules to extract the salient and spatio-temporal features of the propellers while filtering out noise from background objects and camera motion. Since there are no existing event-based MAV datasets, we introduce a novel MAV dataset for the community. This is the first event-based MAV dataset comprising multiple scenarios and different types of MAVs. Without training, our method significantly outperforms state-of-the-art methods and can deal with challenging scenarios, achieving a precision rate of 83.0\% (+30.3\%) and a recall rate of 81.5\% (+36.4\%) on the proposed testing dataset. The dataset and code are available at: https://github.com/WindyLab/EvDetMAV.
The Foundation Cracks: A Comprehensive Study on Bugs and Testing Practices in LLM Libraries
Jun 14, 2025Large Language Model (LLM) libraries have emerged as the foundational infrastructure powering today's AI revolution, serving as the backbone for LLM deployment, inference optimization, fine-tuning, and production serving across diverse applications. Despite their critical role in the LLM ecosystem, these libraries face frequent quality issues and bugs that threaten the reliability of AI systems built upon them. To address this knowledge gap, we present the first comprehensive empirical investigation into bug characteristics and testing practices in modern LLM libraries. We examine 313 bug-fixing commits extracted across two widely-adopted LLM libraries: HuggingFace Transformers and vLLM.Through rigorous manual analysis, we establish comprehensive taxonomies categorizing bug symptoms into 5 types and root causes into 14 distinct categories.Our primary discovery shows that API misuse has emerged as the predominant root cause (32.17%-48.19%), representing a notable transition from algorithm-focused defects in conventional deep learning frameworks toward interface-oriented problems. Additionally, we examine 7,748 test functions to identify 7 distinct test oracle categories employed in current testing approaches, with predefined expected outputs (such as specific tensors and text strings) being the most common strategy. Our assessment of existing testing effectiveness demonstrates that the majority of bugs escape detection due to inadequate test cases (41.73%), lack of test drivers (32.37%), and weak test oracles (25.90%). Drawing from these findings, we offer some recommendations for enhancing LLM library quality assurance.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Importance Weighted Score Matching for Diffusion Samplers with Enhanced Mode Coverage
May 26, 2025Training neural samplers directly from unnormalized densities without access to target distribution samples presents a significant challenge. A critical desideratum in these settings is achieving comprehensive mode coverage, ensuring the sampler captures the full diversity of the target distribution. However, prevailing methods often circumvent the lack of target data by optimizing reverse KL-based objectives. Such objectives inherently exhibit mode-seeking behavior, potentially leading to incomplete representation of the underlying distribution. While alternative approaches strive for better mode coverage, they typically rely on implicit mechanisms like heuristics or iterative refinement. In this work, we propose a principled approach for training diffusion-based samplers by directly targeting an objective analogous to the forward KL divergence, which is conceptually known to encourage mode coverage. We introduce \textit{Importance Weighted Score Matching}, a method that optimizes this desired mode-covering objective by re-weighting the score matching loss using tractable importance sampling estimates, thereby overcoming the absence of target distribution data. We also provide theoretical analysis of the bias and variance for our proposed Monte Carlo estimator and the practical loss function used in our method. Experiments on increasingly complex multi-modal distributions, including 2D Gaussian Mixture Models with up to 120 modes and challenging particle systems with inherent symmetries -- demonstrate that our approach consistently outperforms existing neural samplers across all distributional distance metrics, achieving state-of-the-art results on all benchmarks.
$α$-GAN by Rényi Cross Entropy
May 20, 2025This paper proposes $\alpha$-GAN, a generative adversarial network using R\'{e}nyi measures. The value function is formulated, by R\'{e}nyi cross entropy, as an expected certainty measure incurred by the discriminator's soft decision as to where the sample is from, true population or the generator. The discriminator tries to maximize the R\'{e}nyi certainty about sample source, while the generator wants to reduce it by injecting fake samples. This forms a min-max problem with the solution parameterized by the R\'{e}nyi order $\alpha$. This $\alpha$-GAN reduces to vanilla GAN at $\alpha = 1$, where the value function is exactly the binary cross entropy. The optimization of $\alpha$-GAN is over probability (vector) space. It is shown that the gradient is exponentially enlarged when R\'{e}nyi order is in the range $\alpha \in (0,1)$. This makes convergence faster, which is verified by experimental results. A discussion shows that choosing $\alpha \in (0,1)$ may be able to solve some common problems, e.g., vanishing gradient. A following observation reveals that this range has not been fully explored in the existing R\'{e}nyi version GANs.
Software Development Life Cycle Perspective: A Survey of Benchmarks for CodeLLMs and Agents
May 08, 2025Code large language models (CodeLLMs) and agents have shown great promise in tackling complex software engineering tasks.Compared to traditional software engineering methods, CodeLLMs and agents offer stronger abilities, and can flexibly process inputs and outputs in both natural and code. Benchmarking plays a crucial role in evaluating the capabilities of CodeLLMs and agents, guiding their development and deployment. However, despite their growing significance, there remains a lack of comprehensive reviews of benchmarks for CodeLLMs and agents. To bridge this gap, this paper provides a comprehensive review of existing benchmarks for CodeLLMs and agents, studying and analyzing 181 benchmarks from 461 relevant papers, covering the different phases of the software development life cycle (SDLC). Our findings reveal a notable imbalance in the coverage of current benchmarks, with approximately 60% focused on the software development phase in SDLC, while requirements engineering and software design phases receive minimal attention at only 5% and 3%, respectively. Additionally, Python emerges as the dominant programming language across the reviewed benchmarks. Finally, this paper highlights the challenges of current research and proposes future directions, aiming to narrow the gap between the theoretical capabilities of CodeLLMs and agents and their application in real-world scenarios.
Exposing Product Bias in LLM Investment Recommendation
Mar 11, 2025Large language models (LLMs), as a new generation of recommendation engines, possess powerful summarization and data analysis capabilities, surpassing traditional recommendation systems in both scope and performance. One promising application is investment recommendation. In this paper, we reveal a novel product bias in LLM investment recommendation, where LLMs exhibit systematic preferences for specific products. Such preferences can subtly influence user investment decisions, potentially leading to inflated valuations of products and financial bubbles, posing risks to both individual investors and market stability. To comprehensively study the product bias, we develop an automated pipeline to create a dataset of 567,000 samples across five asset classes (stocks, mutual funds, cryptocurrencies, savings, and portfolios). With this dataset, we present the bf first study on product bias in LLM investment recommendations. Our findings reveal that LLMs exhibit clear product preferences, such as certain stocks (e.g., `AAPL' from Apple and `MSFT' from Microsoft). Notably, this bias persists even after applying debiasing techniques. We urge AI researchers to take heed of the product bias in LLM investment recommendations and its implications, ensuring fairness and security in the digital space and market.