 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
Collaborative Feature Learning for Fine-grained Facial Forgery Detection and Segmentation
Apr 17, 2023



Detecting maliciously falsified facial images and videos has attracted extensive attention from digital-forensics and computer-vision communities. An important topic in manipulation detection is the localization of the fake regions. Previous work related to forgery detection mostly focuses on the entire faces. However, recent forgery methods have developed to edit important facial components while maintaining others unchanged. This drives us to not only focus on the forgery detection but also fine-grained falsified region segmentation. In this paper, we propose a collaborative feature learning approach to simultaneously detect manipulation and segment the falsified components. With the collaborative manner, detection and segmentation can boost each other efficiently. To enable our study of forgery detection and segmentation, we build a facial forgery dataset consisting of both entire and partial face forgeries with their pixel-level manipulation ground-truth. Experiment results have justified the mutual promotion between forgery detection and manipulated region segmentation. The overall performance of the proposed approach is better than the state-of-the-art detection or segmentation approaches. The visualization results have shown that our proposed model always captures the artifacts on facial regions, which is more reasonable.
Robust Face-Swap Detection Based on 3D Facial Shape Information
Apr 28, 2021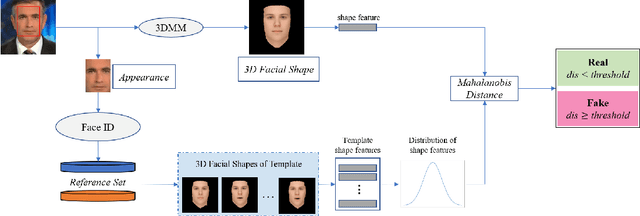

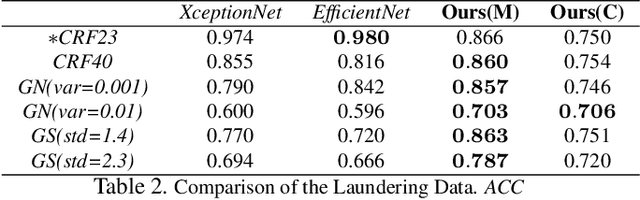
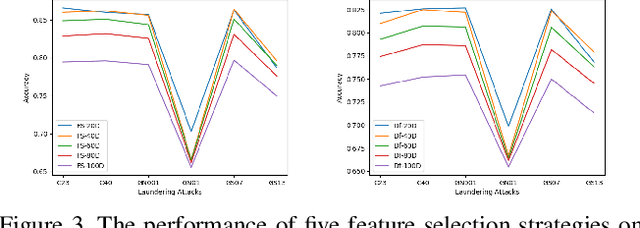
Maliciously-manipulated images or videos - so-called deep fakes - especially face-swap images and videos have attracted more and more malicious attackers to discredit some key figures. Previous pixel-level artifacts based detection techniques always focus on some unclear patterns but ignore some available semantic clues. Therefore, these approaches show weak interpretability and robustness. In this paper, we propose a biometric information based method to fully exploit the appearance and shape feature for face-swap detection of key figures. The key aspect of our method is obtaining the inconsistency of 3D facial shape and facial appearance, and the inconsistency based clue offers natural interpretability for the proposed face-swap detection method. Experimental results show the superiority of our method in robustness on various laundering and cross-domain data, which validates the effectiveness of the proposed method.