 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymphonyGen: 3D Hierarchical Orchestral Generation with Controllable Harmony Skeleton
Apr 28, 2026Generating symphonic music requires simultaneously managing high-level structural form and dense, multi-track orchestration. Existing symbolic models often struggle with a "complexity-control imbalance", in which scaling bottlenecks limit long-term granular steerability. We present SymphonyGen, a 3D hierarchical framework for contemporary cinematic orchestration. SymphonyGen employs a cascading decoder architecture that decomposes the Bar, Track, and Event axes, improving computational efficiency and scalability over conventional 1D or 2D models. We introduce "short-score" conditioning via a beat-quantized multi-voice harmony skeleton, enabling outline control while preserving textural diversity. The model is further refined using Group Relative Policy Optimization (GRPO) with a cross-modal audio-perceptual reward, aligning symbolic output with modern acoustic expectations. Additionally, we implement a dissonance-averse sampling algorithm to suppress unintended tonal clashes during inference. Objective evaluations show that both reinforcement learning and dissonance-averse sampling effectively enhance harmonic cleanliness while maintaining melodic expression. Subjective evaluations demonstrate that SymphonyGen outperforms baselines in musicality and preference for orchestral music generation. Demo page: https://symphonygen.github.io/
Exposing Product Bias in LLM Investment Recommendation
Mar 11, 2025Large language models (LLMs), as a new generation of recommendation engines, possess powerful summarization and data analysis capabilities, surpassing traditional recommendation systems in both scope and performance. One promising application is investment recommendation. In this paper, we reveal a novel product bias in LLM investment recommendation, where LLMs exhibit systematic preferences for specific products. Such preferences can subtly influence user investment decisions, potentially leading to inflated valuations of products and financial bubbles, posing risks to both individual investors and market stability. To comprehensively study the product bias, we develop an automated pipeline to create a dataset of 567,000 samples across five asset classes (stocks, mutual funds, cryptocurrencies, savings, and portfolios). With this dataset, we present the bf first study on product bias in LLM investment recommendations. Our findings reveal that LLMs exhibit clear product preferences, such as certain stocks (e.g., `AAPL' from Apple and `MSFT' from Microsoft). Notably, this bias persists even after applying debiasing techniques. We urge AI researchers to take heed of the product bias in LLM investment recommendations and its implications, ensuring fairness and security in the digital space and market.
How Vital is the Jurisprudential Relevance: Law Article Intervened Legal Case Retrieval and Matching
Feb 25, 2025



Legal case retrieval (LCR) aims to automatically scour for comparable legal cases based on a given query, which is crucial for offering relevant precedents to support the judgment in intelligent legal systems. Due to similar goals, it is often associated with a similar case matching (LCM) task. To address them, a daunting challenge is assessing the uniquely defined legal-rational similarity within the judicial domain, which distinctly deviates from the semantic similarities in general text retrieval. Past works either tagged domain-specific factors or incorporated reference laws to capture legal-rational information. However, their heavy reliance on expert or unrealistic assumptions restricts their practical applicability in real-world scenarios. In this paper, we propose an end-to-end model named LCM-LAI to solve the above challenges. Through meticulous theoretical analysis, LCM-LAI employs a dependent multi-task learning framework to capture legal-rational information within legal cases by a law article prediction (LAP) sub-task, without any additional assumptions in inference. Besides, LCM-LAI proposes an article-aware attention mechanism to evaluate the legal-rational similarity between across-case sentences based on law distribution, which is more effective than conventional semantic similarity. Weperform a series of exhaustive experiments including two different tasks involving four real-world datasets. Results demonstrate that LCM-LAI achieves state-of-the-art performance.
Distinguish Confusion in Legal Judgment Prediction via Revised Relation Knowledge
Aug 18, 2024



Legal Judgment Prediction (LJP) aims to automatically predict a law case's judgment results based on the text description of its facts. In practice, the confusing law articles (or charges) problem frequently occurs, reflecting that the law cases applicable to similar articles (or charges) tend to be misjudged. Although some recent works based on prior knowledge solve this issue well, they ignore that confusion also occurs between law articles with a high posterior semantic similarity due to the data imbalance problem instead of only between the prior highly similar ones, which is this work's further finding. This paper proposes an end-to-end model named \textit{D-LADAN} to solve the above challenges. On the one hand, D-LADAN constructs a graph among law articles based on their text definition and proposes a graph distillation operation (GDO) to distinguish the ones with a high prior semantic similarity. On the other hand, D-LADAN presents a novel momentum-updated memory mechanism to dynamically sense the posterior similarity between law articles (or charges) and a weighted GDO to adaptively capture the distinctions for revising the inductive bias caused by the data imbalance problem. We perform extensive experiments to demonstrate that D-LADAN significantly outperforms state-of-the-art methods in accuracy and robustness.
A Survey of Deep Learning Library Testing Methods
Apr 27, 2024



In recent years, software systems powered by deep learning (DL) techniques have significantly facilitated people's lives in many aspects. As the backbone of these DL systems, various DL libraries undertake the underlying optimization and computation. However, like traditional software, DL libraries are not immune to bugs, which can pose serious threats to users' personal property and safety. Studying the characteristics of DL libraries, their associated bugs, and the corresponding testing methods is crucial for enhancing the security of DL systems and advancing the widespread application of DL technology. This paper provides an overview of the testing research related to various DL libraries, discusses the strengths and weaknesses of existing methods, and provides guidance and reference for the application of the DL library. This paper first introduces the workflow of DL underlying libraries and the characteristics of three kinds of DL libraries involved, namely DL framework, DL compiler, and DL hardware library. It then provides definitions for DL underlying library bugs and testing. Additionally, this paper summarizes the existing testing methods and tools tailored to these DL libraries separately and analyzes their effectiveness and limitations. It also discusses the existing challenges of DL library testing and outlines potential directions for future research.
Model-Free Load Frequency Control of Nonlinear Power Systems Based on Deep Reinforcement Learning
Mar 07, 2024



Load frequency control (LFC) is widely employed in power systems to stabilize frequency fluctuation and guarantee power quality. However, most existing LFC methods rely on accurate power system modeling and usually ignore the nonlinear characteristics of the system, limiting controllers' performance. To solve these problems, this paper proposes a model-free LFC method for nonlinear power systems based on deep deterministic policy gradient (DDPG) framework. The proposed method establishes an emulator network to emulate power system dynamics. After defining the action-value function, the emulator network is applied for control actions evaluation instead of the critic network. Then the actor network controller is effectively optimized by estimating the policy gradient based on zeroth-order optimization (ZOO) and backpropagation algorithm. Simulation results and corresponding comparisons demonstrate the designed controller can generate appropriate control actions and has strong adaptability for nonlinear power systems.
Fast Gumbel-Max Sketch and its Applications
Feb 10, 2023



The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a non-negative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and weighted cardinality estimation require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, FastGM, which reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. FastGM stops the procedure of Gumbel random variables computing for many elements, especially for those with small weights. We perform experiments on a variety of real-world datasets and the experimental results demonstrate that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy or incurring additional expenses.
Federated Learning over Coupled Graphs
Jan 26, 2023Graphs are widely used to represent the relations among entities. When one owns the complete data, an entire graph can be easily built, therefore performing analysis on the graph is straightforward. However, in many scenarios, it is impractical to centralize the data due to data privacy concerns. An organization or party only keeps a part of the whole graph data, i.e., graph data is isolated from different parties. Recently, Federated Learning (FL) has been proposed to solve the data isolation issue, mainly for Euclidean data. It is still a challenge to apply FL on graph data because graphs contain topological information which is notorious for its non-IID nature and is hard to partition. In this work, we propose a novel FL framework for graph data, FedCog, to efficiently handle coupled graphs that are a kind of distributed graph data, but widely exist in a variety of real-world applications such as mobile carriers' communication networks and banks' transaction networks. We theoretically prove the correctness and security of FedCog. Experimental results demonstrate that our method FedCog significantly outperforms traditional FL methods on graphs. Remarkably, our FedCog improves the accuracy of node classification tasks by up to 14.7%.
Uncertainty Set Prediction of Aggregated Wind Power Generation based on Bayesian LSTM and Spatio-Temporal Analysis
Oct 07, 2021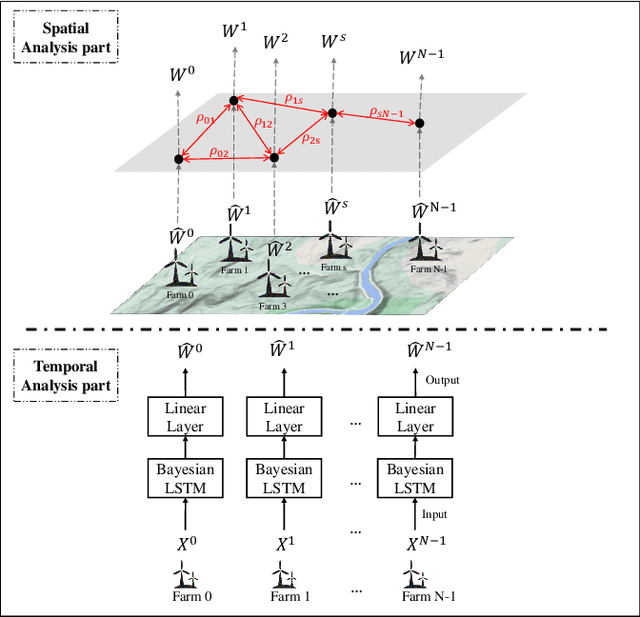
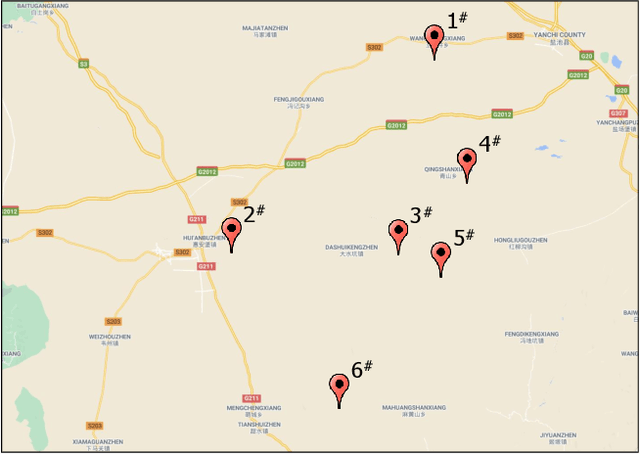
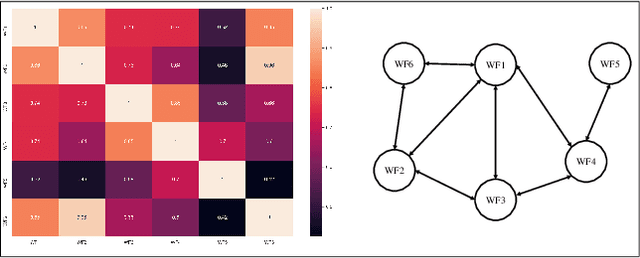
Aggregated stochastic characteristics of geographically distributed wind generation will provide valuable information for secured and economical system operation in electricity markets. This paper focuses on the uncertainty set prediction of the aggregated generation of geographically distributed wind farms. A Spatio-temporal model is proposed to learn the dynamic features from partial observation in near-surface wind fields of neighboring wind farms. We use Bayesian LSTM, a probabilistic prediction model, to obtain the uncertainty set of the generation in individual wind farms. Then, spatial correlation between different wind farms is presented to correct the output results. Numerical testing results based on the actual data with 6 wind farms in northwest China show that the uncertainty set of aggregated wind generation of distributed wind farms is less volatile than that of a single wind farm.
Infer-AVAE: An Attribute Inference Model Based on Adversarial Variational Autoencoder
Dec 30, 2020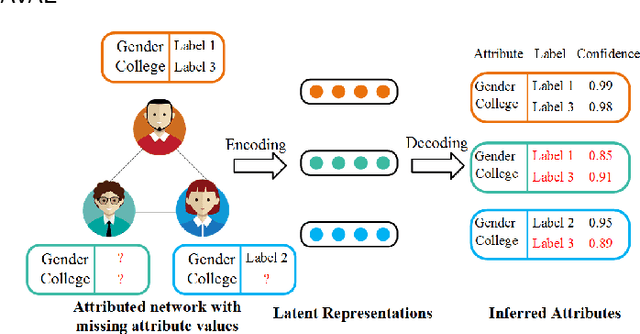
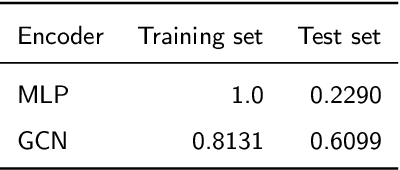
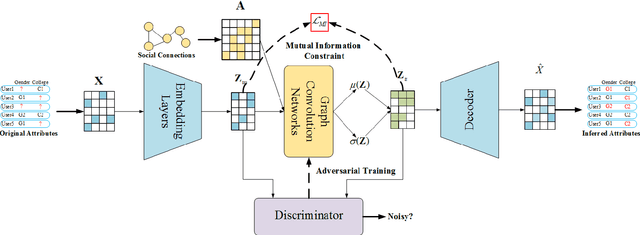
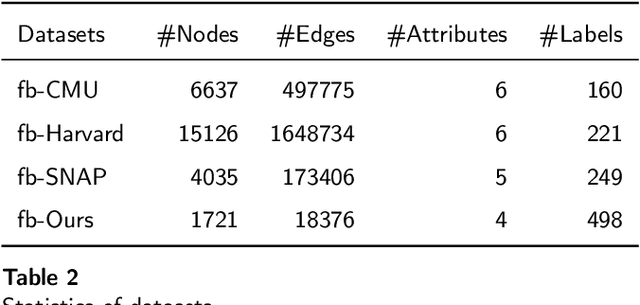
Facing the sparsity of user attributes on social networks, attribute inference aims at inferring missing attributes based on existing data and additional information such as social connections between users. Recently, Variational Autoencoders (VAEs) have been successfully applied to solve the problem in a semi-supervised way. However, the latent representations learned by the encoder contain either insufficient or useless information: i) MLPs can successfully reconstruct the input data but fail in completing missing part, ii) GNNs merge information according to social connections but suffer from over-smoothing, which is a common problem with GNNs. Moreover, existing methods neglect regulating the decoder, as a result, it lacks adequate inference ability and faces severe overfitting. To address the above issues, we propose an attribute inference model based on adversarial VAE (Infer-AVAE). Our model deliberately unifies MLPs and GNNs in encoder to learn dual latent representations: one contains only the observed attributes of each user, the other converges extra information from the neighborhood. Then, an adversarial network is trained to leverage the differences between the two representations and adversarial training is conducted to guide GNNs using MLPs for robust representations. What's more, mutual information constraint is introduced in loss function to specifically train the decoder as a discriminator. Thus, it can make better use of auxiliary information in the representations for attribute inference. Based on real-world social network datasets, experimental results demonstrate that our model averagely outperforms state-of-art by 7.0% in accuracy.