 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePasteGAN: A Semi-Parametric Method to Generate Image from Scene Graph
May 05, 2019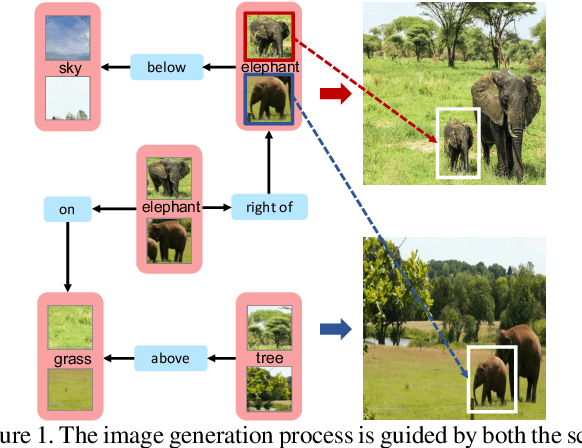
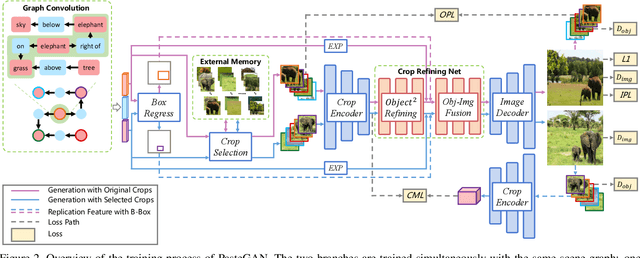
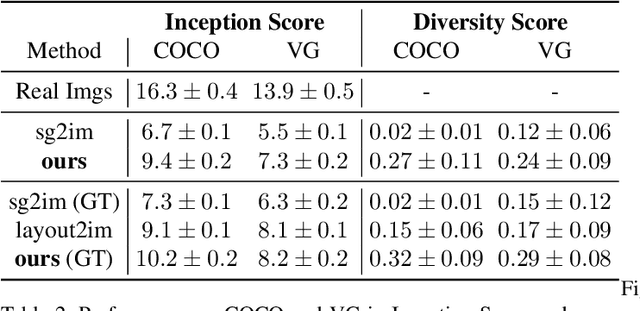
Despite some exciting progress on high-quality image generation from structured~(scene graphs) or free-form~(sentences) descriptions, most of them only guarantee the image-level semantical consistency, \ie the generated image matching the semantic meaning of the description. However, it still lacks the investigations on synthesizing the images in a more controllable way, like finely manipulating the visual appearance of every object. Therefore, to generate the images with preferred objects and rich interactions, we propose a semi-parametric method, denoted as PasteGAN, for generating the image from the scene graph, where spatial arrangements of the objects and their pair-wise relationships are defined by the scene graph and the object appearances are determined by given object crops. To enhance the interactions of the objects in the output, we design a Crop Refining Network to embed the objects as well as their relationships into one map. Multiple losses work collaboratively to guarantee the generated images highly respecting the crops and complying with the scene graphs while maintaining excellent image quality. A crop selector is also proposed to pick the most-compatible crops from our external object tank by encoding the interactions around the objects in the scene graph if the crops are not provided. Evaluated on Visual Genome and COCO-Stuff, our proposed method significantly outperforms the SOTA methods on both Inception Score and Diversity Score with a huge margin. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with given objects.
Disentangling Pose from Appearance in Monochrome Hand Images
Apr 16, 2019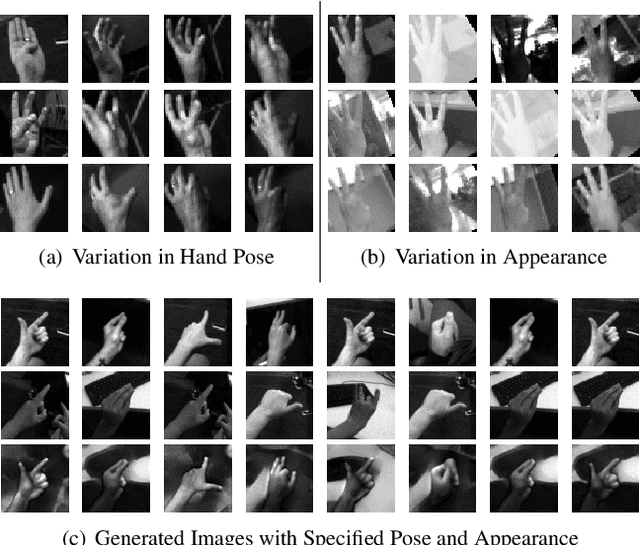

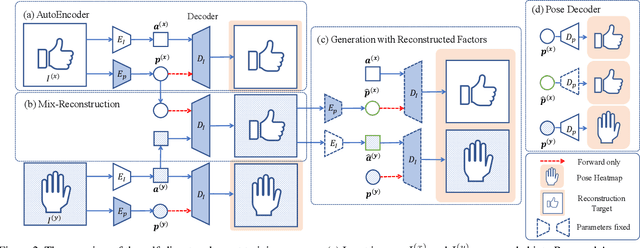

Hand pose estimation from the monocular 2D image is challenging due to the variation in lighting, appearance, and background. While some success has been achieved using deep neural networks, they typically require collecting a large dataset that adequately samples all the axes of variation of hand images. It would, therefore, be useful to find a representation of hand pose which is independent of the image appearance~(like hand texture, lighting, background), so that we can synthesize unseen images by mixing pose-appearance combinations. In this paper, we present a novel technique that disentangles the representation of pose from a complementary appearance factor in 2D monochrome images. We supervise this disentanglement process using a network that learns to generate images of hand using specified pose+appearance features. Unlike previous work, we do not require image pairs with a matching pose; instead, we use the pose annotations already available and introduce a novel use of cycle consistency to ensure orthogonality between the factors. Experimental results show that our self-disentanglement scheme successfully decomposes the hand image into the pose and its complementary appearance features of comparable quality as the method using paired data. Additionally, training the model with extra synthesized images with unseen hand-appearance combinations by re-mixing pose and appearance factors from different images can improve the 2D pose estimation performance.
Conditional Adversarial Generative Flow for Controllable Image Synthesis
Apr 03, 2019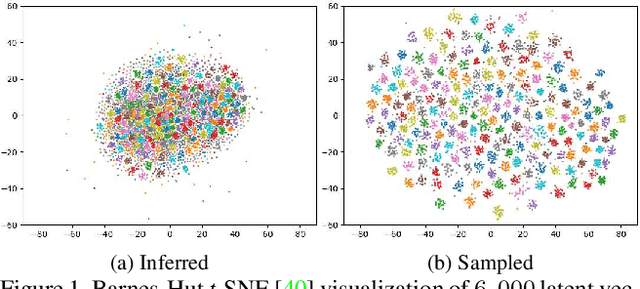
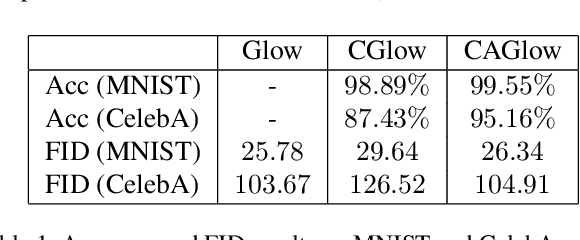
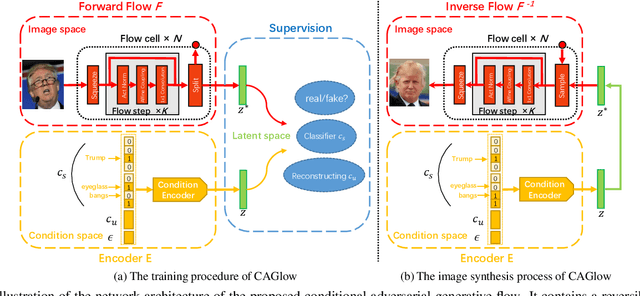
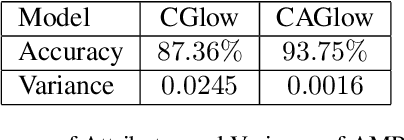
Flow-based generative models show great potential in image synthesis due to its reversible pipeline and exact log-likelihood target, yet it suffers from weak ability for conditional image synthesis, especially for multi-label or unaware conditions. This is because the potential distribution of image conditions is hard to measure precisely from its latent variable $z$. In this paper, based on modeling a joint probabilistic density of an image and its conditions, we propose a novel flow-based generative model named conditional adversarial generative flow (CAGlow). Instead of disentangling attributes from latent space, we blaze a new trail for learning an encoder to estimate the mapping from condition space to latent space in an adversarial manner. Given a specific condition $c$, CAGlow can encode it to a sampled $z$, and then enable robust conditional image synthesis in complex situations like combining person identity with multiple attributes. The proposed CAGlow can be implemented in both supervised and unsupervised manners, thus can synthesize images with conditional information like categories, attributes, and even some unknown properties. Extensive experiments show that CAGlow ensures the independence of different conditions and outperforms regular Glow to a significant extent.
Semantics Disentangling for Text-to-Image Generation
Apr 02, 2019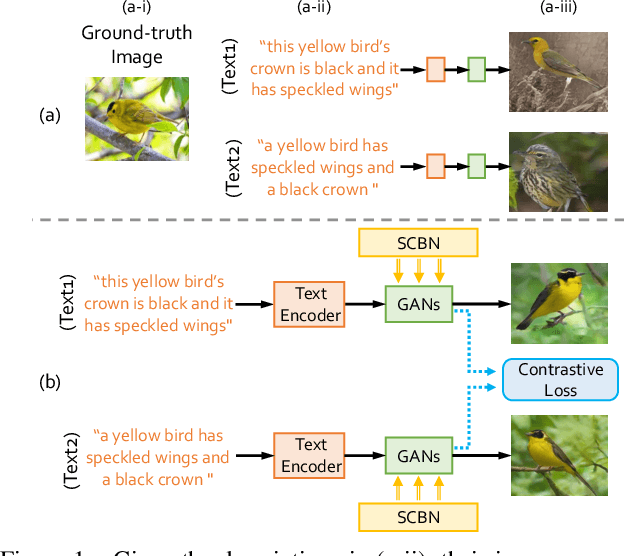
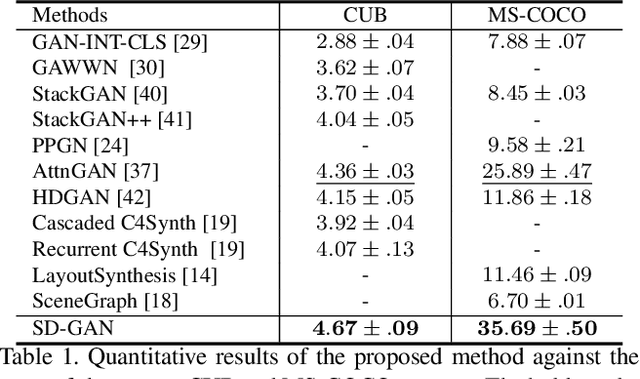
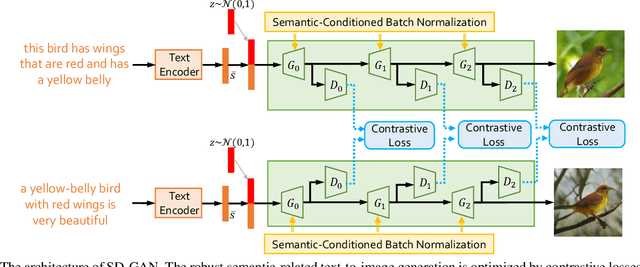
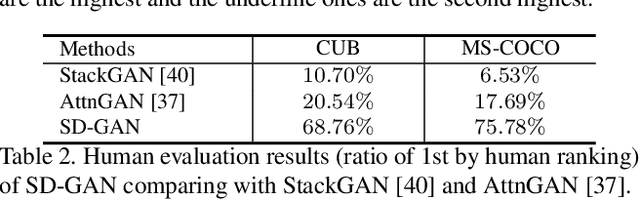
Synthesizing photo-realistic images from text descriptions is a challenging problem. Previous studies have shown remarkable progresses on visual quality of the generated images. In this paper, we consider semantics from the input text descriptions in helping render photo-realistic images. However, diverse linguistic expressions pose challenges in extracting consistent semantics even they depict the same thing. To this end, we propose a novel photo-realistic text-to-image generation model that implicitly disentangles semantics to both fulfill the high-level semantic consistency and low-level semantic diversity. To be specific, we design (1) a Siamese mechanism in the discriminator to learn consistent high-level semantics, and (2) a visual-semantic embedding strategy by semantic-conditioned batch normalization to find diverse low-level semantics. Extensive experiments and ablation studies on CUB and MS-COCO datasets demonstrate the superiority of the proposed method in comparison to state-of-the-art methods.
Context and Attribute Grounded Dense Captioning
Apr 02, 2019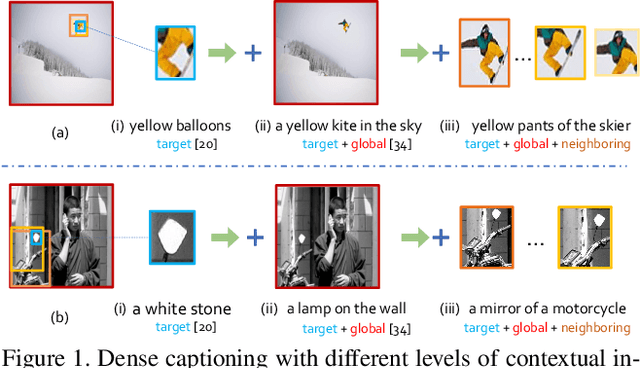
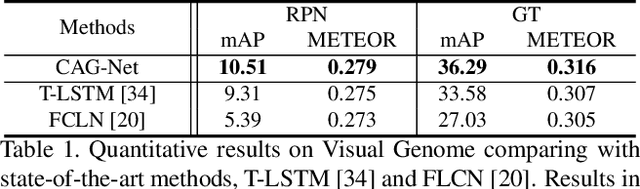
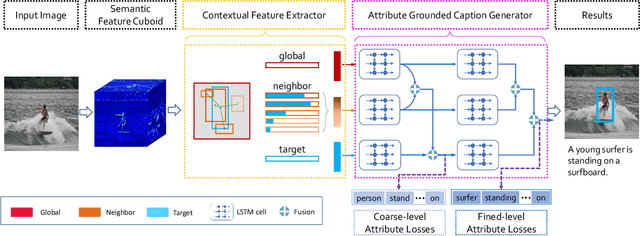

Dense captioning aims at simultaneously localizing semantic regions and describing these regions-of-interest (ROIs) with short phrases or sentences in natural language. Previous studies have shown remarkable progresses, but they are often vulnerable to the aperture problem that a caption generated by the features inside one ROI lacks contextual coherence with its surrounding context in the input image. In this work, we investigate contextual reasoning based on multi-scale message propagations from the neighboring contents to the target ROIs. To this end, we design a novel end-to-end context and attribute grounded dense captioning framework consisting of 1) a contextual visual mining module and 2) a multi-level attribute grounded description generation module. Knowing that captions often co-occur with the linguistic attributes (such as who, what and where), we also incorporate an auxiliary supervision from hierarchical linguistic attributes to augment the distinctiveness of the learned captions. Extensive experiments and ablation studies on Visual Genome dataset demonstrate the superiority of the proposed model in comparison to state-of-the-art methods.
Improving Referring Expression Grounding with Cross-modal Attention-guided Erasing
Apr 02, 2019
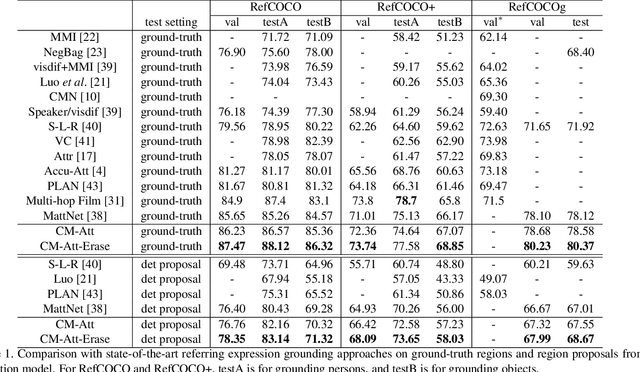
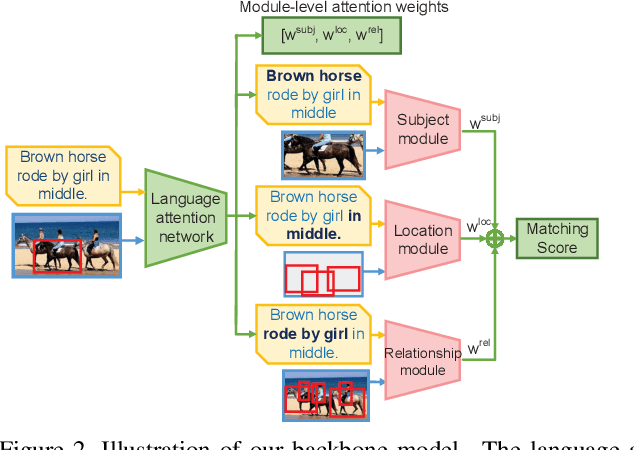
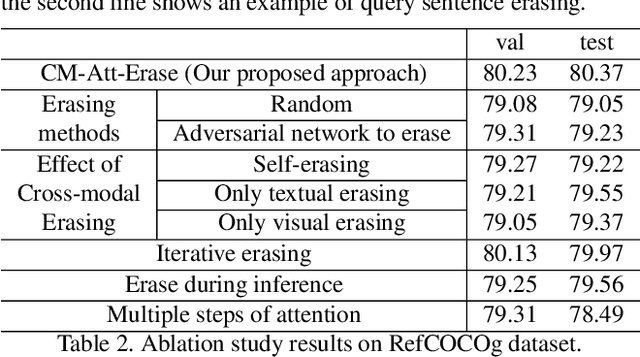
Referring expression grounding aims at locating certain objects or persons in an image with a referring expression, where the key challenge is to comprehend and align various types of information from visual and textual domain, such as visual attributes, location and interactions with surrounding regions. Although the attention mechanism has been successfully applied for cross-modal alignments, previous attention models focus on only the most dominant features of both modalities, and neglect the fact that there could be multiple comprehensive textual-visual correspondences between images and referring expressions. To tackle this issue, we design a novel cross-modal attention-guided erasing approach, where we discard the most dominant information from either textual or visual domains to generate difficult training samples online, and to drive the model to discover complementary textual-visual correspondences. Extensive experiments demonstrate the effectiveness of our proposed method, which achieves state-of-the-art performance on three referring expression grounding datasets.
Feature Intertwiner for Object Detection
Mar 28, 2019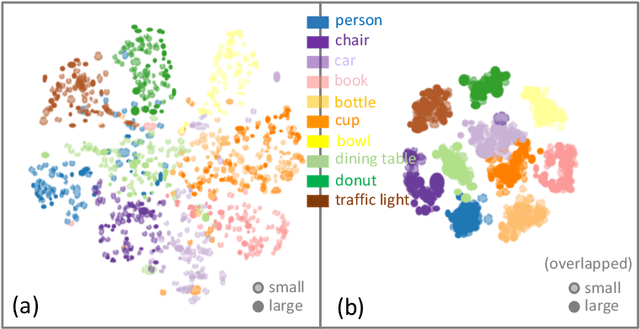

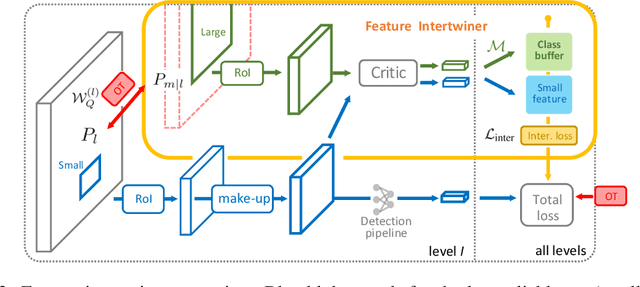
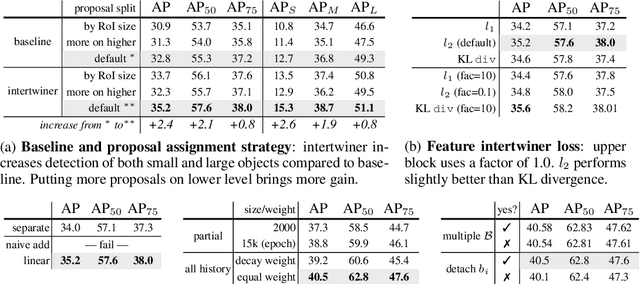
A well-trained model should classify objects with a unanimous score for every category. This requires the high-level semantic features should be as much alike as possible among samples. To achive this, previous works focus on re-designing the loss or proposing new regularization constraints. In this paper, we provide a new perspective. For each category, it is assumed that there are two feature sets: one with reliable information and the other with less reliable source. We argue that the reliable set could guide the feature learning of the less reliable set during training - in spirit of student mimicking teacher behavior and thus pushing towards a more compact class centroid in the feature space. Such a scheme also benefits the reliable set since samples become closer within the same category - implying that it is easier for the classifier to identify. We refer to this mutual learning process as feature intertwiner and embed it into object detection. It is well-known that objects of low resolution are more difficult to detect due to the loss of detailed information during network forward pass (e.g., RoI operation). We thus regard objects of high resolution as the reliable set and objects of low resolution as the less reliable set. Specifically, an intertwiner is designed to minimize the distribution divergence between two sets. The choice of generating an effective feature representation for the reliable set is further investigated, where we introduce the optimal transport (OT) theory into the framework. Samples in the less reliable set are better aligned with aid of OT metric. Incorporated with such a plug-and-play intertwiner, we achieve an evident improvement over previous state-of-the-arts.
Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation
Mar 27, 2019
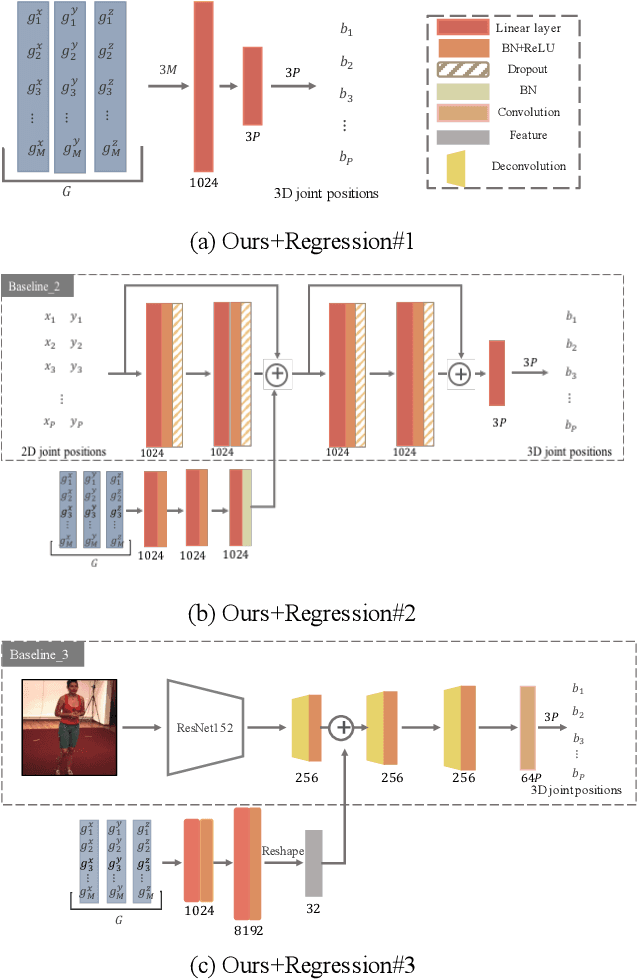
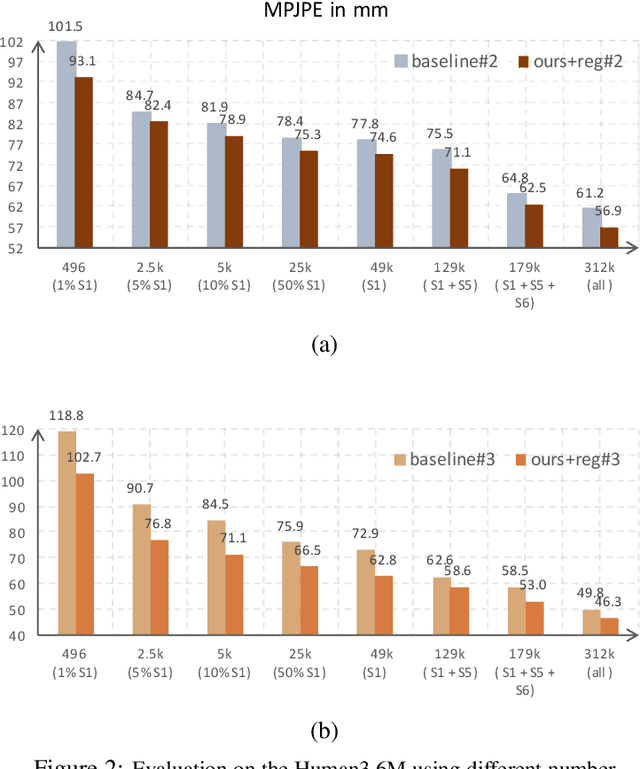
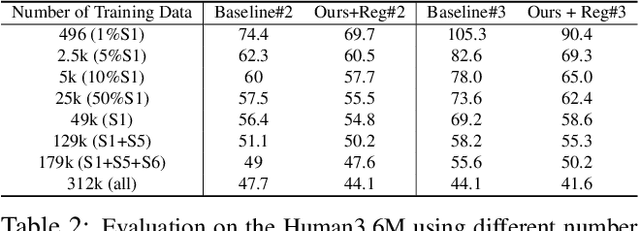
Recent studies have shown remarkable advances in 3D human pose estimation from monocular images, with the help of large-scale in-door 3D datasets and sophisticated network architectures. However, the generalizability to different environments remains an elusive goal. In this work, we propose a geometry-aware 3D representation for the human pose to address this limitation by using multiple views in a simple auto-encoder model at the training stage and only 2D keypoint information as supervision. A view synthesis framework is proposed to learn the shared 3D representation between viewpoints with synthesizing the human pose from one viewpoint to the other one. Instead of performing a direct transfer in the raw image-level, we propose a skeleton-based encoder-decoder mechanism to distil only pose-related representation in the latent space. A learning-based representation consistency constraint is further introduced to facilitate the robustness of latent 3D representation. Since the learnt representation encodes 3D geometry information, mapping it to 3D pose will be much easier than conventional frameworks that use an image or 2D coordinates as the input of 3D pose estimator. We demonstrate our approach on the task of 3D human pose estimation. Comprehensive experiments on three popular benchmarks show that our model can significantly improve the performance of state-of-the-art methods with simply injecting the representation as a robust 3D prior.
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
Mar 27, 2019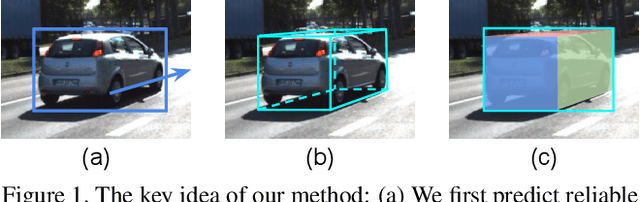
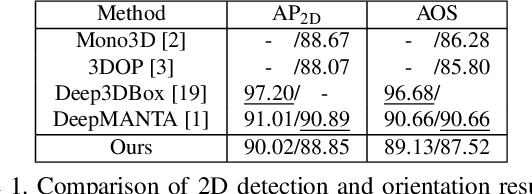

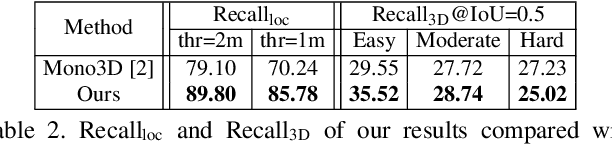
We present an efficient 3D object detection framework based on a single RGB image in the scenario of autonomous driving. Our efforts are put on extracting the underlying 3D information in a 2D image and determining the accurate 3D bounding box of the object without point cloud or stereo data. Leveraging the off-the-shelf 2D object detector, we propose an artful approach to efficiently obtain a coarse cuboid for each predicted 2D box. The coarse cuboid has enough accuracy to guide us to determine the 3D box of the object by refinement. In contrast to previous state-of-the-art methods that only use the features extracted from the 2D bounding box for box refinement, we explore the 3D structure information of the object by employing the visual features of visible surfaces. The new features from surfaces are utilized to eliminate the problem of representation ambiguity brought by only using a 2D bounding box. Moreover, we investigate different methods of 3D box refinement and discover that a classification formulation with quality aware loss has much better performance than regression. Evaluated on the KITTI benchmark, our approach outperforms current state-of-the-art methods for single RGB image based 3D object detection.
Shape2Motion: Joint Analysis of Motion Parts and Attributes from 3D Shapes
Mar 12, 2019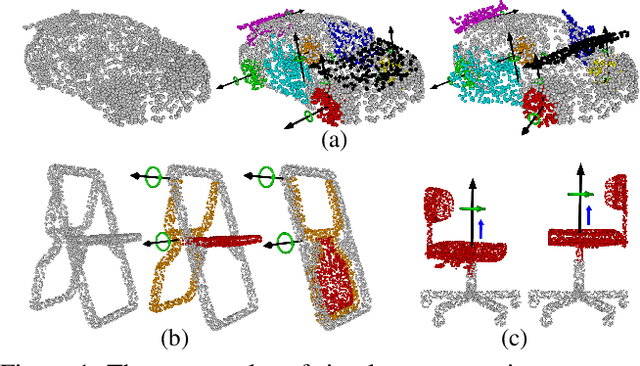
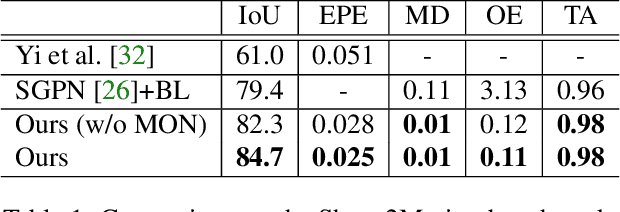
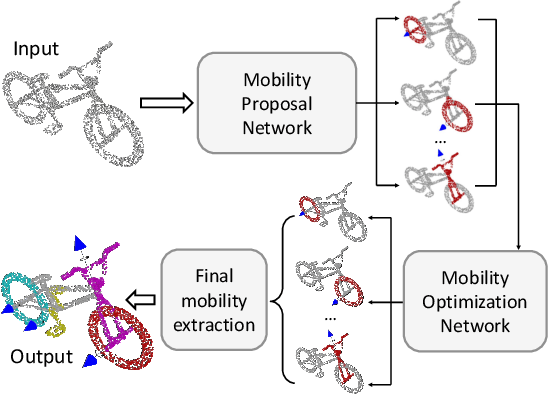
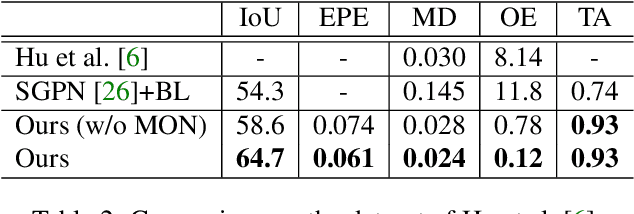
For the task of mobility analysis of 3D shapes, we propose joint analysis for simultaneous motion part segmentation and motion attribute estimation, taking a single 3D model as input. The problem is significantly different from those tackled in the existing works which assume the availability of either a pre-existing shape segmentation or multiple 3D models in different motion states. To that end, we develop Shape2Motion which takes a single 3D point cloud as input, and jointly computes a mobility-oriented segmentation and the associated motion attributes. Shape2Motion is comprised of two deep neural networks designed for mobility proposal generation and mobility optimization, respectively. The key contribution of these networks is the novel motion-driven features and losses used in both motion part segmentation and motion attribute estimation. This is based on the observation that the movement of a functional part preserves the shape structure. We evaluate Shape2Motion with a newly proposed benchmark for mobility analysis of 3D shapes. Results demonstrate that our method achieves the state-of-the-art performance both in terms of motion part segmentation and motion attribute estimation.