 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBORT: Back and Denoising Reconstruction for End-to-End Task-Oriented Dialog
May 05, 2022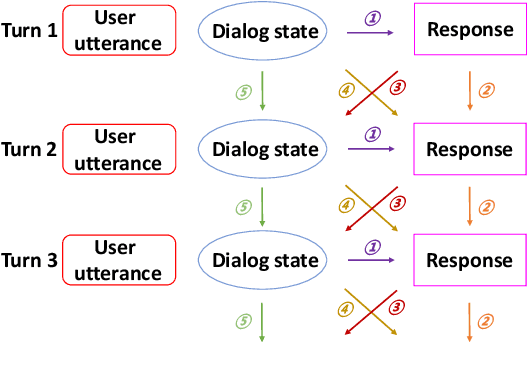
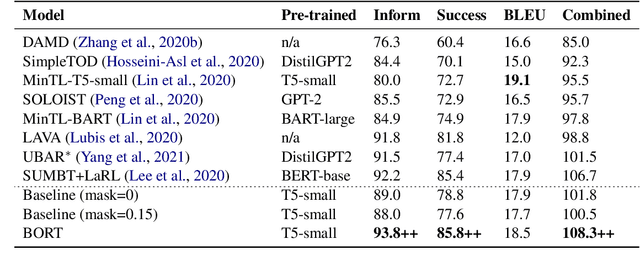
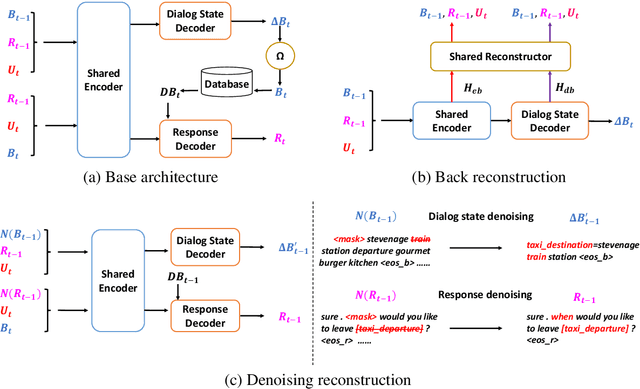
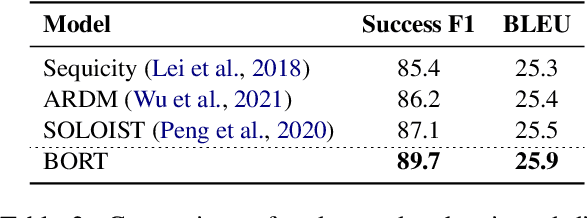
A typical end-to-end task-oriented dialog system transfers context into dialog state, and upon which generates a response, which usually faces the problem of error propagation from both previously generated inaccurate dialog states and responses, especially in low-resource scenarios. To alleviate these issues, we propose BORT, a back and denoising reconstruction approach for end-to-end task-oriented dialog system. Squarely, to improve the accuracy of dialog states, back reconstruction is used to reconstruct the original input context from the generated dialog states since inaccurate dialog states cannot recover the corresponding input context. To enhance the denoising capability of the model to reduce the impact of error propagation, denoising reconstruction is used to reconstruct the corrupted dialog state and response. Extensive experiments conducted on MultiWOZ 2.0 and CamRest676 show the effectiveness of BORT. Furthermore, BORT demonstrates its advanced capabilities in the zero-shot domain and low-resource scenarios.
OPERA:Operation-Pivoted Discrete Reasoning over Text
May 04, 2022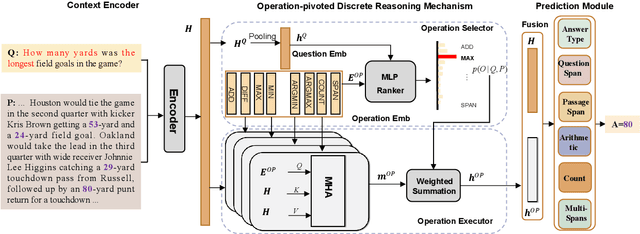

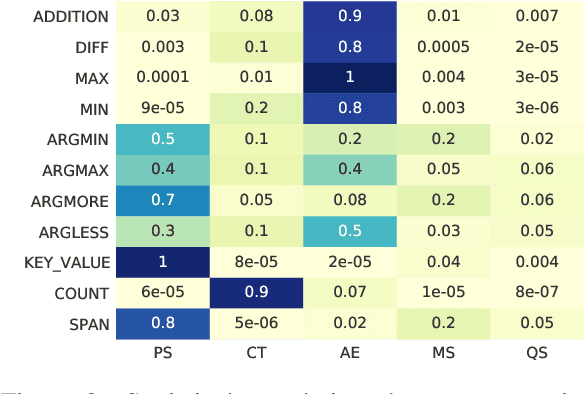

Machine reading comprehension (MRC) that requires discrete reasoning involving symbolic operations, e.g., addition, sorting, and counting, is a challenging task. According to this nature, semantic parsing-based methods predict interpretable but complex logical forms. However, logical form generation is nontrivial and even a little perturbation in a logical form will lead to wrong answers. To alleviate this issue, multi-predictor -based methods are proposed to directly predict different types of answers and achieve improvements. However, they ignore the utilization of symbolic operations and encounter a lack of reasoning ability and interpretability. To inherit the advantages of these two types of methods, we propose OPERA, an operation-pivoted discrete reasoning framework, where lightweight symbolic operations (compared with logical forms) as neural modules are utilized to facilitate the reasoning ability and interpretability. Specifically, operations are first selected and then softly executed to simulate the answer reasoning procedure. Extensive experiments on both DROP and RACENum datasets show the reasoning ability of OPERA. Moreover, further analysis verifies its interpretability.
SE-GAN: Skeleton Enhanced GAN-based Model for Brush Handwriting Font Generation
Apr 22, 2022
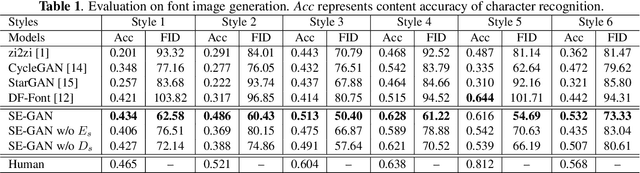
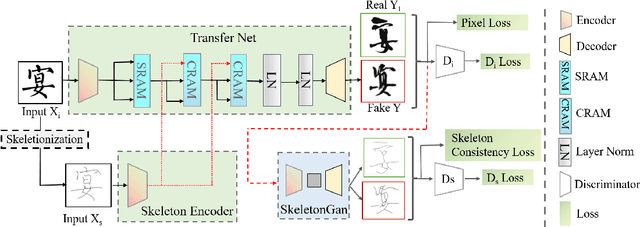
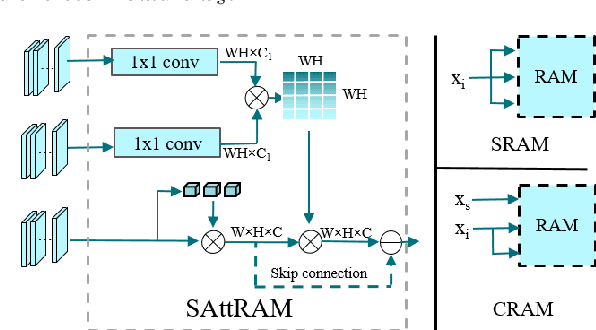
Previous works on font generation mainly focus on the standard print fonts where character's shape is stable and strokes are clearly separated. There is rare research on brush handwriting font generation, which involves holistic structure changes and complex strokes transfer. To address this issue, we propose a novel GAN-based image translation model by integrating the skeleton information. We first extract the skeleton from training images, then design an image encoder and a skeleton encoder to extract corresponding features. A self-attentive refined attention module is devised to guide the model to learn distinctive features between different domains. A skeleton discriminator is involved to first synthesize the skeleton image from the generated image with a pre-trained generator, then to judge its realness to the target one. We also contribute a large-scale brush handwriting font image dataset with six styles and 15,000 high-resolution images. Both quantitative and qualitative experimental results demonstrate the competitiveness of our proposed model.
Gated Multimodal Fusion with Contrastive Learning for Turn-taking Prediction in Human-robot Dialogue
Apr 18, 2022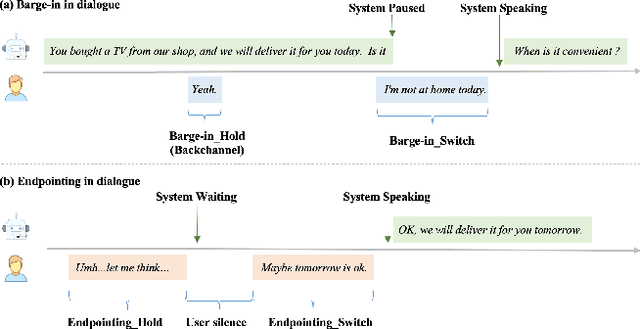
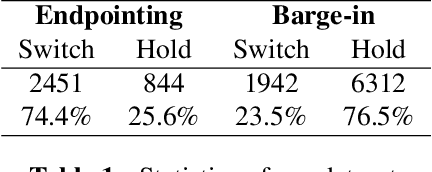
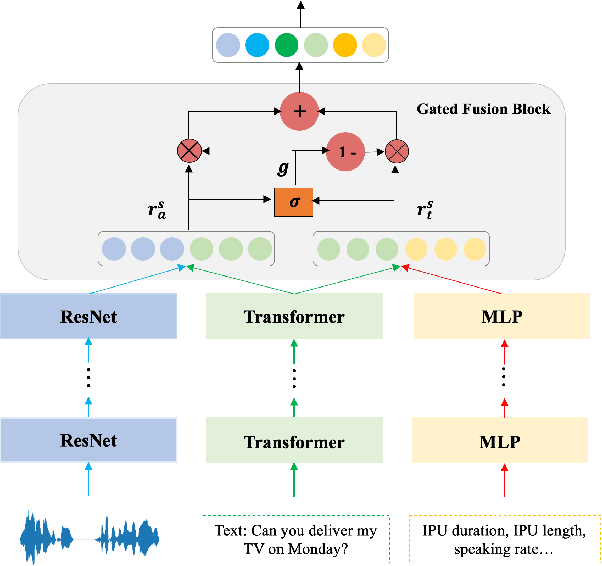
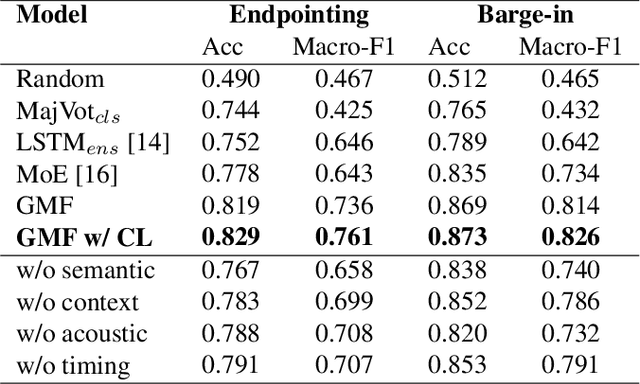
Turn-taking, aiming to decide when the next speaker can start talking, is an essential component in building human-robot spoken dialogue systems. Previous studies indicate that multimodal cues can facilitate this challenging task. However, due to the paucity of public multimodal datasets, current methods are mostly limited to either utilizing unimodal features or simplistic multimodal ensemble models. Besides, the inherent class imbalance in real scenario, e.g. sentence ending with short pause will be mostly regarded as the end of turn, also poses great challenge to the turn-taking decision. In this paper, we first collect a large-scale annotated corpus for turn-taking with over 5,000 real human-robot dialogues in speech and text modalities. Then, a novel gated multimodal fusion mechanism is devised to utilize various information seamlessly for turn-taking prediction. More importantly, to tackle the data imbalance issue, we design a simple yet effective data augmentation method to construct negative instances without supervision and apply contrastive learning to obtain better feature representations. Extensive experiments are conducted and the results demonstrate the superiority and competitiveness of our model over several state-of-the-art baselines.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Building Robust Spoken Language Understanding by Cross Attention between Phoneme Sequence and ASR Hypothesis
Mar 22, 2022
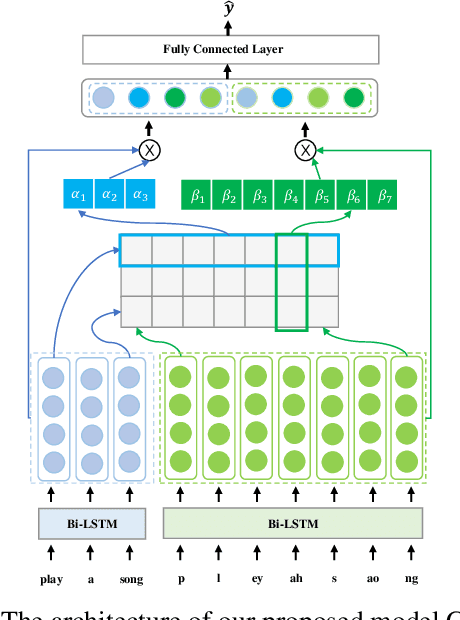
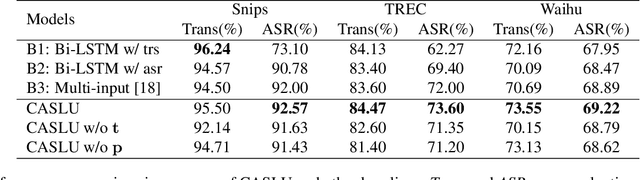
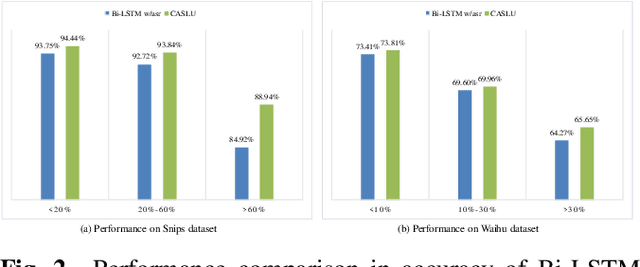
Building Spoken Language Understanding (SLU) robust to Automatic Speech Recognition (ASR) errors is an essential issue for various voice-enabled virtual assistants. Considering that most ASR errors are caused by phonetic confusion between similar-sounding expressions, intuitively, leveraging the phoneme sequence of speech can complement ASR hypothesis and enhance the robustness of SLU. This paper proposes a novel model with Cross Attention for SLU (denoted as CASLU). The cross attention block is devised to catch the fine-grained interactions between phoneme and word embeddings in order to make the joint representations catch the phonetic and semantic features of input simultaneously and for overcoming the ASR errors in downstream natural language understanding (NLU) tasks. Extensive experiments are conducted on three datasets, showing the effectiveness and competitiveness of our approach. Additionally, We also validate the universality of CASLU and prove its complementarity when combining with other robust SLU techniques.
Fine- and Coarse-Granularity Hybrid Self-Attention for Efficient BERT
Mar 17, 2022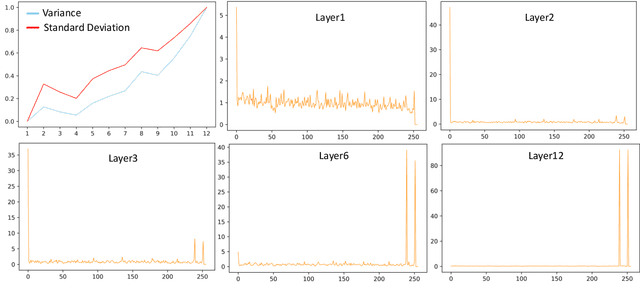
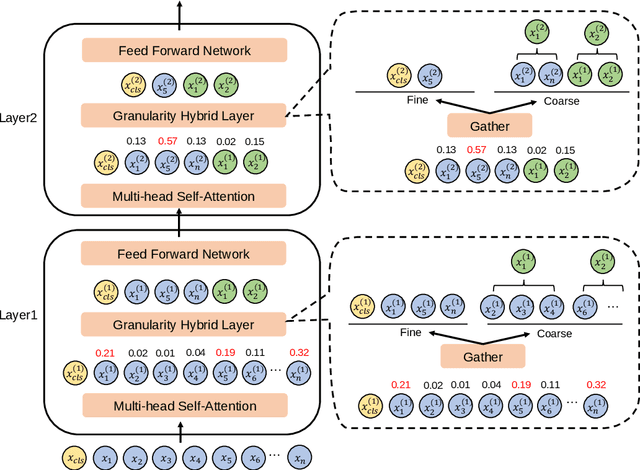
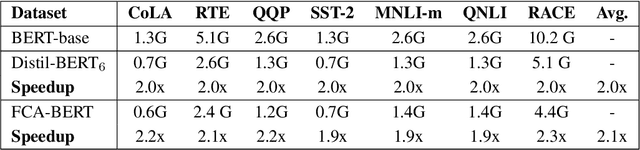
Transformer-based pre-trained models, such as BERT, have shown extraordinary success in achieving state-of-the-art results in many natural language processing applications. However, deploying these models can be prohibitively costly, as the standard self-attention mechanism of the Transformer suffers from quadratic computational cost in the input sequence length. To confront this, we propose FCA, a fine- and coarse-granularity hybrid self-attention that reduces the computation cost through progressively shortening the computational sequence length in self-attention. Specifically, FCA conducts an attention-based scoring strategy to determine the informativeness of tokens at each layer. Then, the informative tokens serve as the fine-granularity computing units in self-attention and the uninformative tokens are replaced with one or several clusters as the coarse-granularity computing units in self-attention. Experiments on GLUE and RACE datasets show that BERT with FCA achieves 2x reduction in FLOPs over original BERT with <1% loss in accuracy. We show that FCA offers a significantly better trade-off between accuracy and FLOPs compared to prior methods.
Cross-modal Contrastive Distillation for Instructional Activity Anticipation
Jan 18, 2022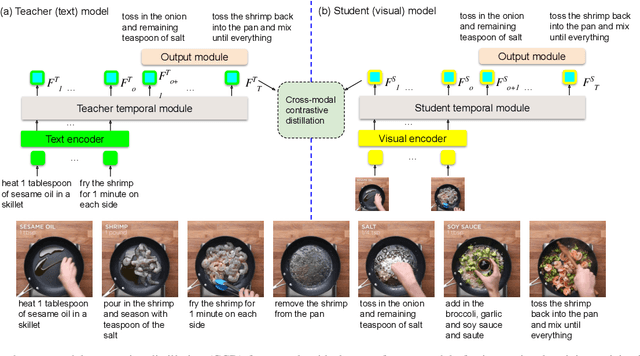
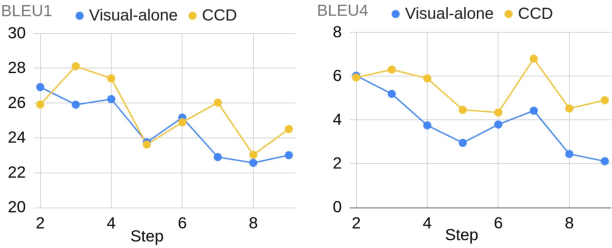

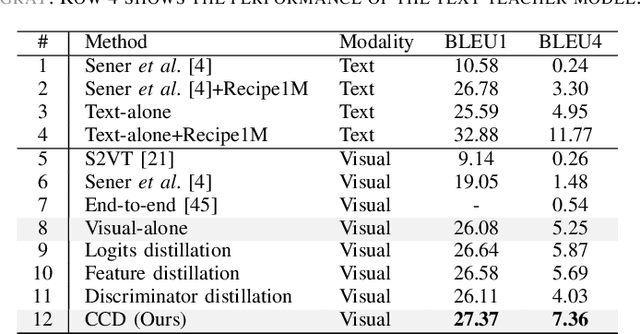
In this study, we aim to predict the plausible future action steps given an observation of the past and study the task of instructional activity anticipation. Unlike previous anticipation tasks that aim at action label prediction, our work targets at generating natural language outputs that provide interpretable and accurate descriptions of future action steps. It is a challenging task due to the lack of semantic information extracted from the instructional videos. To overcome this challenge, we propose a novel knowledge distillation framework to exploit the related external textual knowledge to assist the visual anticipation task. However, previous knowledge distillation techniques generally transfer information within the same modality. To bridge the gap between the visual and text modalities during the distillation process, we devise a novel cross-modal contrastive distillation (CCD) scheme, which facilitates knowledge distillation between teacher and student in heterogeneous modalities with the proposed cross-modal distillation loss. We evaluate our method on the Tasty Videos dataset. CCD improves the anticipation performance of the visual-alone student model by a large margin of 40.2% relatively in BLEU4. Our approach also outperforms the state-of-the-art approaches by a large margin.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021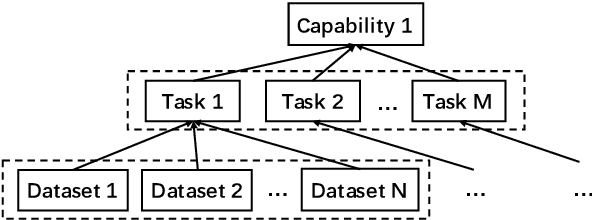
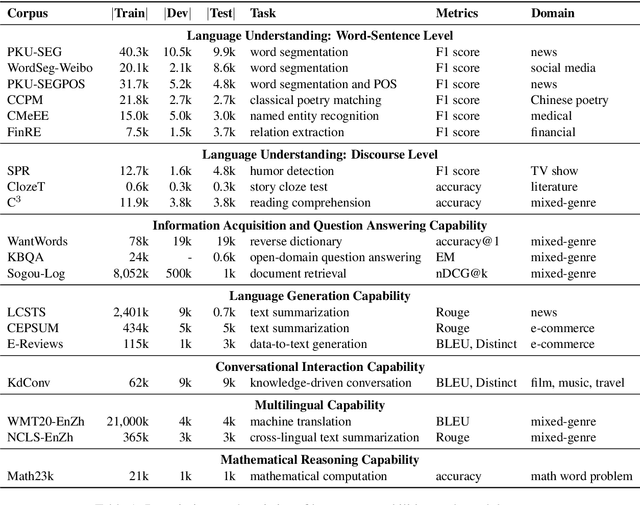

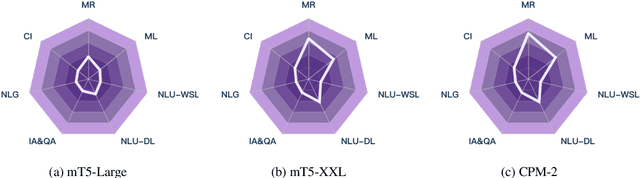
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021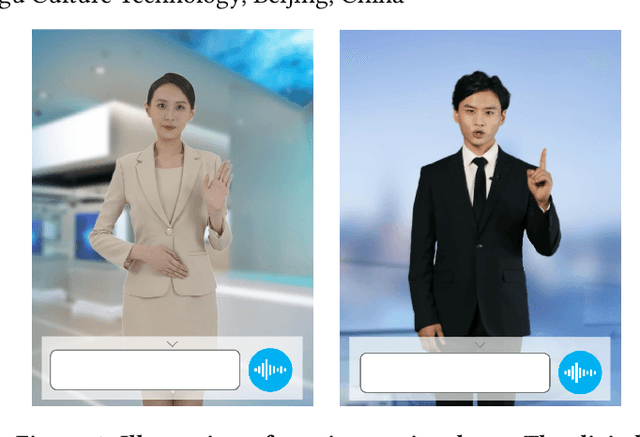
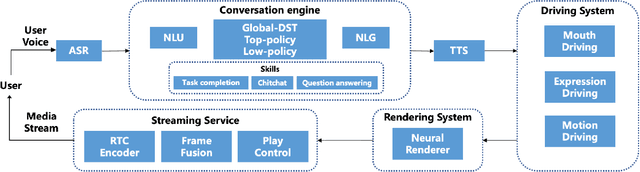
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.