 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Representation Facilitates Unified Universal Vision Encoding
Jan 20, 2026Models for image representation learning are typically designed for either recognition or generation. Various forms of contrastive learning help models learn to convert images to embeddings that are useful for classification, detection, and segmentation. On the other hand, models can be trained to reconstruct images with pixel-wise, perceptual, and adversarial losses in order to learn a latent space that is useful for image generation. We seek to unify these two directions with a first-of-its-kind model that learns representations which are simultaneously useful for recognition and generation. We train our model as a hyper-network for implicit neural representation, which learns to map images to model weights for fast, accurate reconstruction. We further integrate our INR hyper-network with knowledge distillation to improve its generalization and performance. Beyond the novel training design, the model also learns an unprecedented compressed embedding space with outstanding performance for various visual tasks. The complete model competes with state-of-the-art results for image representation learning, while also enabling generative capabilities with its high-quality tiny embeddings. The code is available at https://github.com/tiktok/huvr.
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
Deep learning-enhanced dual-mode multiplexed optical sensor for point-of-care diagnostics of cardiovascular diseases
Dec 24, 2025Rapid and accessible cardiac biomarker testing is essential for the timely diagnosis and risk assessment of myocardial infarction (MI) and heart failure (HF), two interrelated conditions that frequently coexist and drive recurrent hospitalizations with high mortality. However, current laboratory and point-of-care testing systems are limited by long turnaround times, narrow dynamic ranges for the tested biomarkers, and single-analyte formats that fail to capture the complexity of cardiovascular disease. Here, we present a deep learning-enhanced dual-mode multiplexed vertical flow assay (xVFA) with a portable optical reader and a neural network-based quantification pipeline. This optical sensor integrates colorimetric and chemiluminescent detection within a single paper-based cartridge to complementarily cover a large dynamic range (spanning ~6 orders of magnitude) for both low- and high-abundance biomarkers, while maintaining quantitative accuracy. Using 50 uL of serum, the optical sensor simultaneously quantifies cardiac troponin I (cTnI), creatine kinase-MB (CK-MB), and N-terminal pro-B-type natriuretic peptide (NT-proBNP) within 23 min. The xVFA achieves sub-pg/mL sensitivity for cTnI and sub-ng/mL sensitivity for CK-MB and NT-proBNP, spanning the clinically relevant ranges for these biomarkers. Neural network models trained and blindly tested on 92 patient serum samples yielded a robust quantification performance (Pearson's r > 0.96 vs. reference assays). By combining high sensitivity, multiplexing, and automation in a compact and cost-effective optical sensor format, the dual-mode xVFA enables rapid and quantitative cardiovascular diagnostics at the point of care.
Vehicle-centric Perception via Multimodal Structured Pre-training
Dec 22, 2025Vehicle-centric perception plays a crucial role in many intelligent systems, including large-scale surveillance systems, intelligent transportation, and autonomous driving. Existing approaches lack effective learning of vehicle-related knowledge during pre-training, resulting in poor capability for modeling general vehicle perception representations. To handle this problem, we propose VehicleMAE-V2, a novel vehicle-centric pre-trained large model. By exploring and exploiting vehicle-related multimodal structured priors to guide the masked token reconstruction process, our approach can significantly enhance the model's capability to learn generalizable representations for vehicle-centric perception. Specifically, we design the Symmetry-guided Mask Module (SMM), Contour-guided Representation Module (CRM) and Semantics-guided Representation Module (SRM) to incorporate three kinds of structured priors into token reconstruction including symmetry, contour and semantics of vehicles respectively. SMM utilizes the vehicle symmetry constraints to avoid retaining symmetric patches and can thus select high-quality masked image patches and reduce information redundancy. CRM minimizes the probability distribution divergence between contour features and reconstructed features and can thus preserve holistic vehicle structure information during pixel-level reconstruction. SRM aligns image-text features through contrastive learning and cross-modal distillation to address the feature confusion caused by insufficient semantic understanding during masked reconstruction. To support the pre-training of VehicleMAE-V2, we construct Autobot4M, a large-scale dataset comprising approximately 4 million vehicle images and 12,693 text descriptions. Extensive experiments on five downstream tasks demonstrate the superior performance of VehicleMAE-V2.
SLCFormer: Spectral-Local Context Transformer with Physics-Grounded Flare Synthesis for Nighttime Flare Removal
Dec 17, 2025Lens flare is a common nighttime artifact caused by strong light sources scattering within camera lenses, leading to hazy streaks, halos, and glare that degrade visual quality. However, existing methods usually fail to effectively address nonuniform scattered flares, which severely reduces their applicability to complex real-world scenarios with diverse lighting conditions. To address this issue, we propose SLCFormer, a novel spectral-local context transformer framework for effective nighttime lens flare removal. SLCFormer integrates two key modules: the Frequency Fourier and Excitation Module (FFEM), which captures efficient global contextual representations in the frequency domain to model flare characteristics, and the Directionally-Enhanced Spatial Module (DESM) for local structural enhancement and directional features in the spatial domain for precise flare removal. Furthermore, we introduce a ZernikeVAE-based scatter flare generation pipeline to synthesize physically realistic scatter flares with spatially varying PSFs, bridging optical physics and data-driven training. Extensive experiments on the Flare7K++ dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches in both quantitative metrics and perceptual visual quality, and generalizing robustly to real nighttime scenes with complex flare artifacts.
Diffusion Model Regularized Implicit Neural Representation for CT Metal Artifact Reduction
Dec 09, 2025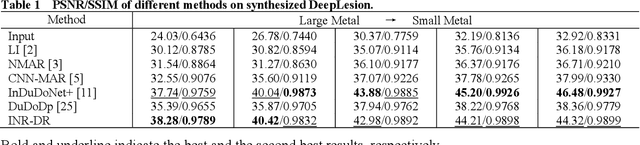
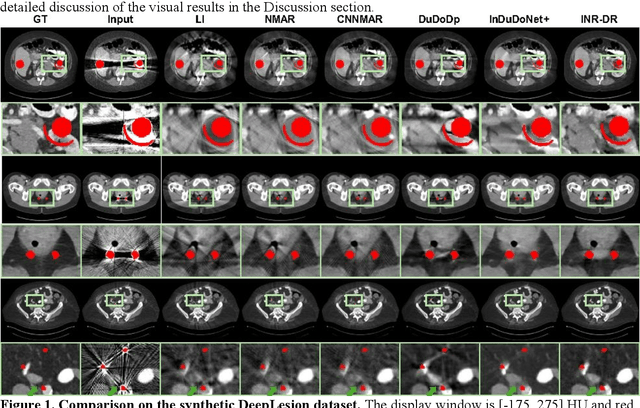
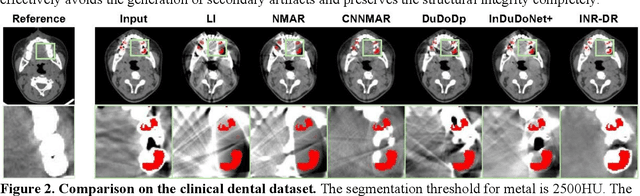

Computed tomography (CT) images are often severely corrupted by artifacts in the presence of metals. Existing supervised metal artifact reduction (MAR) approaches suffer from performance instability on known data due to their reliance on limited paired metal-clean data, which limits their clinical applicability. Moreover, existing unsupervised methods face two main challenges: 1) the CT physical geometry is not effectively incorporated into the MAR process to ensure data fidelity; 2) traditional heuristics regularization terms cannot fully capture the abundant prior knowledge available. To overcome these shortcomings, we propose diffusion model regularized implicit neural representation framework for MAR. The implicit neural representation integrates physical constraints and imposes data fidelity, while the pre-trained diffusion model provides prior knowledge to regularize the solution. Experimental results on both simulated and clinical data demonstrate the effectiveness and generalization ability of our method, highlighting its potential to be applied to clinical settings.
Unsupervised Motion-Compensated Decomposition for Cardiac MRI Reconstruction via Neural Representation
Nov 17, 2025Cardiac magnetic resonance (CMR) imaging is widely used to characterize cardiac morphology and function. To accelerate CMR imaging, various methods have been proposed to recover high-quality spatiotemporal CMR images from highly undersampled k-t space data. However, current CMR reconstruction techniques either fail to achieve satisfactory image quality or are restricted by the scarcity of ground truth data, leading to limited applicability in clinical scenarios. In this work, we proposed MoCo-INR, a new unsupervised method that integrates implicit neural representations (INR) with the conventional motion-compensated (MoCo) framework. Using explicit motion modeling and the continuous prior of INRs, MoCo-INR can produce accurate cardiac motion decomposition and high-quality CMR reconstruction. Furthermore, we introduce a new INR network architecture tailored to the CMR problem, which significantly stabilizes model optimization. Experiments on retrospective (simulated) datasets demonstrate the superiority of MoCo-INR over state-of-the-art methods, achieving fast convergence and fine-detailed reconstructions at ultra-high acceleration factors (e.g., 20x in VISTA sampling). Additionally, evaluations on prospective (real-acquired) free-breathing CMR scans highlight the clinical practicality of MoCo-INR for real-time imaging. Several ablation studies further confirm the effectiveness of the critical components of MoCo-INR.
Self-Supervised Visual Prompting for Cross-Domain Road Damage Detection
Nov 16, 2025



The deployment of automated pavement defect detection is often hindered by poor cross-domain generalization. Supervised detectors achieve strong in-domain accuracy but require costly re-annotation for new environments, while standard self-supervised methods capture generic features and remain vulnerable to domain shift. We propose \ours, a self-supervised framework that \emph{visually probes} target domains without labels. \ours introduces a Self-supervised Prompt Enhancement Module (SPEM), which derives defect-aware prompts from unlabeled target data to guide a frozen ViT backbone, and a Domain-Aware Prompt Alignment (DAPA) objective, which aligns prompt-conditioned source and target representations. Experiments on four challenging benchmarks show that \ours consistently outperforms strong supervised, self-supervised, and adaptation baselines, achieving robust zero-shot transfer, improved resilience to domain variations, and high data efficiency in few-shot adaptation. These results highlight self-supervised prompting as a practical direction for building scalable and adaptive visual inspection systems. Source code is publicly available: https://github.com/xixiaouab/PROBE/tree/main
Bid Farewell to Seesaw: Towards Accurate Long-tail Session-based Recommendation via Dual Constraints of Hybrid Intents
Nov 11, 2025



Session-based recommendation (SBR) aims to predict anonymous users' next interaction based on their interaction sessions. In the practical recommendation scenario, low-exposure items constitute the majority of interactions, creating a long-tail distribution that severely compromises recommendation diversity. Existing approaches attempt to address this issue by promoting tail items but incur accuracy degradation, exhibiting a "see-saw" effect between long-tail and accuracy performance. We attribute such conflict to session-irrelevant noise within the tail items, which existing long-tail approaches fail to identify and constrain effectively. To resolve this fundamental conflict, we propose \textbf{HID} (\textbf{H}ybrid \textbf{I}ntent-based \textbf{D}ual Constraint Framework), a plug-and-play framework that transforms the conventional "see-saw" into "win-win" through introducing the hybrid intent-based dual constraints for both long-tail and accuracy. Two key innovations are incorporated in this framework: (i) \textit{Hybrid Intent Learning}, where we reformulate the intent extraction strategies by employing attribute-aware spectral clustering to reconstruct the item-to-intent mapping. Furthermore, discrimination of session-irrelevant noise is achieved through the assignment of the target and noise intents to each session. (ii) \textit{Intent Constraint Loss}, which incorporates two novel constraint paradigms regarding the \textit{diversity} and \textit{accuracy} to regulate the representation learning process of both items and sessions. These two objectives are unified into a single training loss through rigorous theoretical derivation. Extensive experiments across multiple SBR models and datasets demonstrate that HID can enhance both long-tail performance and recommendation accuracy, establishing new state-of-the-art performance in long-tail recommender systems.
DeepBooTS: Dual-Stream Residual Boosting for Drift-Resilient Time-Series Forecasting
Nov 10, 2025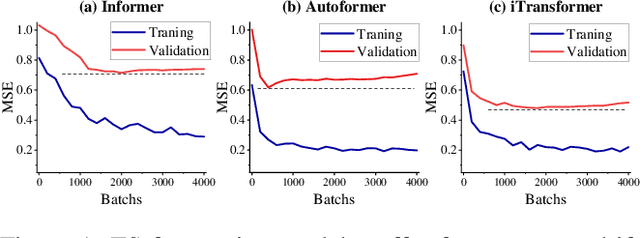
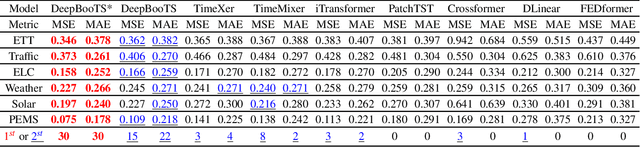
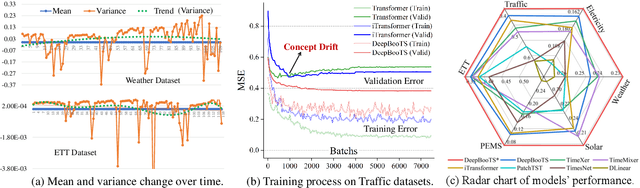
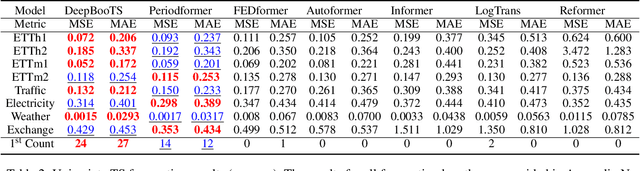
Time-Series (TS) exhibits pronounced non-stationarity. Consequently, most forecasting methods display compromised robustness to concept drift, despite the prevalent application of instance normalization. We tackle this challenge by first analysing concept drift through a bias-variance lens and proving that weighted ensemble reduces variance without increasing bias. These insights motivate DeepBooTS, a novel end-to-end dual-stream residual-decreasing boosting method that progressively reconstructs the intrinsic signal. In our design, each block of a deep model becomes an ensemble of learners with an auxiliary output branch forming a highway to the final prediction. The block-wise outputs correct the residuals of previous blocks, leading to a learning-driven decomposition of both inputs and targets. This method enhances versatility and interpretability while substantially improving robustness to concept drift. Extensive experiments, including those on large-scale datasets, show that the proposed method outperforms existing methods by a large margin, yielding an average performance improvement of 15.8% across various datasets, establishing a new benchmark for TS forecasting.