 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
Jun 09, 2026This paper introduces ARM, a discrete representation-based AutoRegressive Model that unifies image understanding, generation, and editing within a next-token prediction framework. ARM is built on three efforts: first, we train a discrete semantic visual tokenizer that maps images into compact token sequences. Our tokenizer is supervised with multiple objectives that jointly promote semantic discriminability, language alignment and faithful reconstruction, thereby supporting diverse tasks in a shared latent space. With this, we train a 7B autoregressive model over large-scale text and image token sequences, seamlessly developing vision-language perception and generation capabilities. Finally, to further improve preference-aligned behavior for text-to-image generation and instruction-guided editing, ARM applies reinforcement learning (RL) to optimize task-level objectives such as visual quality, instruction adherence, and edit consistency. Surprisingly, the results show that RL not only substantially improves performance on the target tasks (e.g., raising WISE overall from 0.50 to 0.56, GEdit-Bench-EN G_O from 5.75 to 6.68), but also induces cross-task synergy between text-to-image generation and editing. Collectively, these findings highlight autoregressive modeling, when paired with strong representations and preference optimization, as a scalable foundation for multimodal intelligence. Code: https://github.com/wdrink/ARM.
BitLM: Unlocking Multi-Token Language Generation with Bitwise Continuous Diffusion
May 12, 2026Autoregressive language models generate text one token at a time, yet natural language is inherently structured in multi-token units, including phrases, n-grams, and collocations that carry meaning jointly. This one-token bottleneck limits both the expressiveness of the model during pre-training and its throughput at inference time. Existing remedies such as speculative decoding or diffusion-based language models either leave the underlying bottleneck intact or sacrifice the causal structure essential to language modeling. We propose BitLM, a language model that represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. Crucially, BitLM preserves left-to-right causal attention across blocks while making joint lexical decisions within each block, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, BitLM reframes token generation as iterative commitment in a compact binary space, enabling more efficient pre-training and substantially faster inference without altering the causal foundation that makes language models effective. Our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement but an interface choice, and that changing it can yield a stronger and faster language model. We hope BitLM points toward a promising direction for next-generation language model architectures.
BitDance: Scaling Autoregressive Generative Models with Binary Tokens
Feb 15, 2026We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices. With high-entropy binary latents, BitDance lets each token represent up to $2^{256}$ states, yielding a compact yet highly expressive discrete representation. Sampling from such a huge token space is difficult with standard classification. To resolve this, BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens. Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference. On ImageNet 256x256, BitDance achieves an FID of 1.24, the best among AR models. With next-patch diffusion, BitDance beats state-of-the-art parallel AR models that use 1.4B parameters, while using 5.4x fewer parameters (260M) and achieving 8.7x speedup. For text-to-image generation, BitDance trains on large-scale multimodal tokens and generates high-resolution, photorealistic images efficiently, showing strong performance and favorable scaling. When generating 1024x1024 images, BitDance achieves a speedup of over 30x compared to prior AR models. We release code and models to facilitate further research on AR foundation models. Code and models are available at: https://github.com/shallowdream204/BitDance.
Implicit Neural Representation Facilitates Unified Universal Vision Encoding
Jan 20, 2026Models for image representation learning are typically designed for either recognition or generation. Various forms of contrastive learning help models learn to convert images to embeddings that are useful for classification, detection, and segmentation. On the other hand, models can be trained to reconstruct images with pixel-wise, perceptual, and adversarial losses in order to learn a latent space that is useful for image generation. We seek to unify these two directions with a first-of-its-kind model that learns representations which are simultaneously useful for recognition and generation. We train our model as a hyper-network for implicit neural representation, which learns to map images to model weights for fast, accurate reconstruction. We further integrate our INR hyper-network with knowledge distillation to improve its generalization and performance. Beyond the novel training design, the model also learns an unprecedented compressed embedding space with outstanding performance for various visual tasks. The complete model competes with state-of-the-art results for image representation learning, while also enabling generative capabilities with its high-quality tiny embeddings. The code is available at https://github.com/tiktok/huvr.
DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
May 16, 2025Diffusion Transformer (DiT), a promising diffusion model for visual generation, demonstrates impressive performance but incurs significant computational overhead. Intriguingly, analysis of pre-trained DiT models reveals that global self-attention is often redundant, predominantly capturing local patterns-highlighting the potential for more efficient alternatives. In this paper, we revisit convolution as an alternative building block for constructing efficient and expressive diffusion models. However, naively replacing self-attention with convolution typically results in degraded performance. Our investigations attribute this performance gap to the higher channel redundancy in ConvNets compared to Transformers. To resolve this, we introduce a compact channel attention mechanism that promotes the activation of more diverse channels, thereby enhancing feature diversity. This leads to Diffusion ConvNet (DiCo), a family of diffusion models built entirely from standard ConvNet modules, offering strong generative performance with significant efficiency gains. On class-conditional ImageNet benchmarks, DiCo outperforms previous diffusion models in both image quality and generation speed. Notably, DiCo-XL achieves an FID of 2.05 at 256x256 resolution and 2.53 at 512x512, with a 2.7x and 3.1x speedup over DiT-XL/2, respectively. Furthermore, our largest model, DiCo-H, scaled to 1B parameters, reaches an FID of 1.90 on ImageNet 256x256-without any additional supervision during training. Code: https://github.com/shallowdream204/DiCo.
BaFTA: Backprop-Free Test-Time Adaptation For Zero-Shot Vision-Language Models
Jun 18, 2024



Large-scale pretrained vision-language models like CLIP have demonstrated remarkable zero-shot image classification capabilities across diverse domains. To enhance CLIP's performance while preserving the zero-shot paradigm, various test-time prompt tuning methods have been introduced to refine class embeddings through unsupervised learning objectives during inference. However, these methods often encounter challenges in selecting appropriate learning rates to prevent collapsed training in the absence of validation data during test-time adaptation. In this study, we propose a novel backpropagation-free algorithm BaFTA for test-time adaptation of vision-language models. Instead of fine-tuning text prompts to refine class embeddings, our approach directly estimates class centroids using online clustering within a projected embedding space that aligns text and visual embeddings. We dynamically aggregate predictions from both estimated and original class embeddings, as well as from distinct augmented views, by assessing the reliability of each prediction using R\'enyi Entropy. Through extensive experiments, we demonstrate that BaFTA consistently outperforms state-of-the-art test-time adaptation methods in both effectiveness and efficiency.
Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Dec 07, 2023



Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023



Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
Efficient Feature Distillation for Zero-shot Detection
Mar 23, 2023The large-scale vision-language models (e.g., CLIP) are leveraged by different methods to detect unseen objects. However, most of these works require additional captions or images for training, which is not feasible in the context of zero-shot detection. In contrast, the distillation-based method is an extra-data-free method, but it has its limitations. Specifically, existing work creates distillation regions that are biased to the base categories, which limits the distillation of novel category information and harms the distillation efficiency. Furthermore, directly using the raw feature from CLIP for distillation neglects the domain gap between the training data of CLIP and the detection datasets, which makes it difficult to learn the mapping from the image region to the vision-language feature space - an essential component for detecting unseen objects. As a result, existing distillation-based methods require an excessively long training schedule. To solve these problems, we propose Efficient feature distillation for Zero-Shot Detection (EZSD). Firstly, EZSD adapts the CLIP's feature space to the target detection domain by re-normalizing CLIP to bridge the domain gap; Secondly, EZSD uses CLIP to generate distillation proposals with potential novel instances, to avoid the distillation being overly biased to the base categories. Finally, EZSD takes advantage of semantic meaning for regression to further improve the model performance. As a result, EZSD achieves state-of-the-art performance in the COCO zero-shot benchmark with a much shorter training schedule and outperforms previous work by 4% in LVIS overall setting with 1/10 training time.
MixNorm: Test-Time Adaptation Through Online Normalization Estimation
Oct 21, 2021
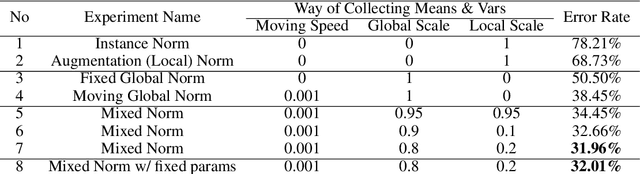
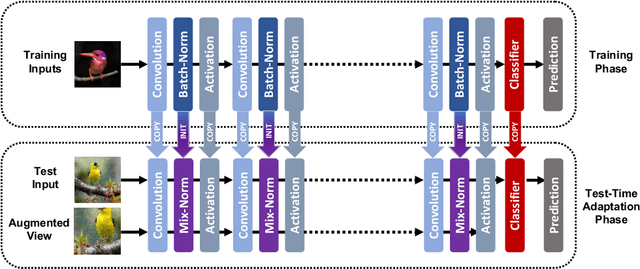
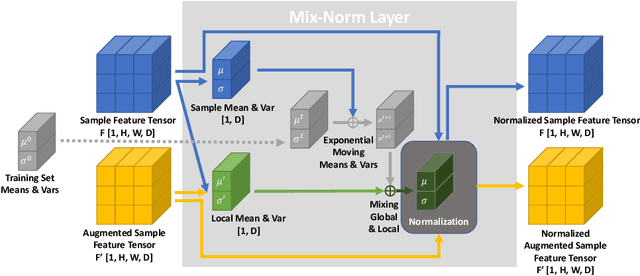
We present a simple and effective way to estimate the batch-norm statistics during test time, to fast adapt a source model to target test samples. Known as Test-Time Adaptation, most prior works studying this task follow two assumptions in their evaluation where (1) test samples come together as a large batch, and (2) all from a single test distribution. However, in practice, these two assumptions may not stand, the reasons for which we propose two new evaluation settings where batch sizes are arbitrary and multiple distributions are considered. Unlike the previous methods that require a large batch of single distribution during test time to calculate stable batch-norm statistics, our method avoid any dependency on large online batches and is able to estimate accurate batch-norm statistics with a single sample. The proposed method significantly outperforms the State-Of-The-Art in the newly proposed settings in Test-Time Adaptation Task, and also demonstrates improvements in various other settings such as Source-Free Unsupervised Domain Adaptation and Zero-Shot Classification.