 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025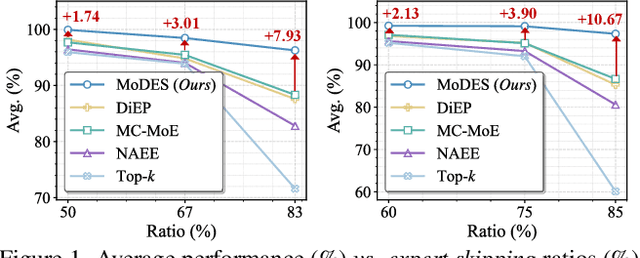
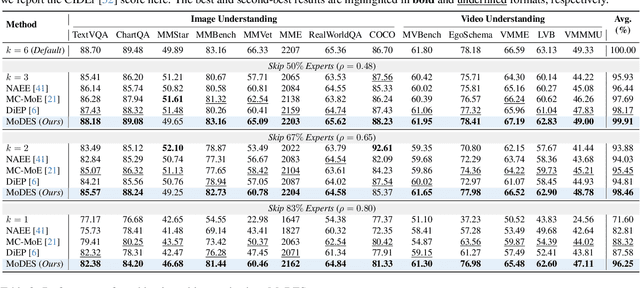
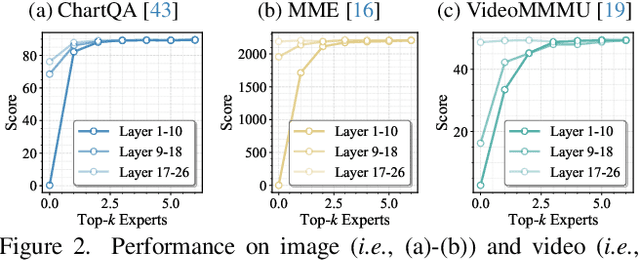
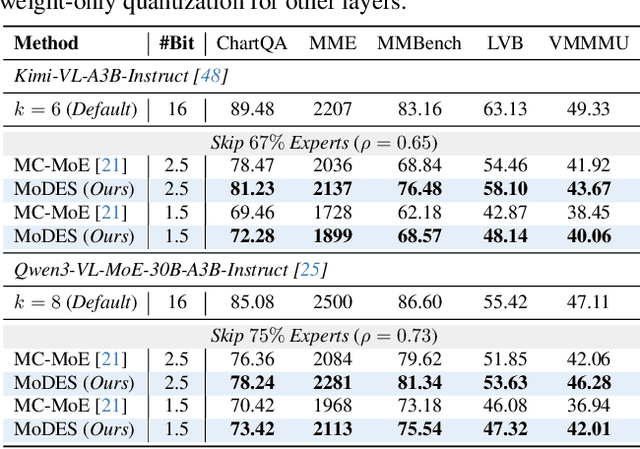
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
VEIL: Jailbreaking Text-to-Video Models via Visual Exploitation from Implicit Language
Nov 17, 2025Jailbreak attacks can circumvent model safety guardrails and reveal critical blind spots. Prior attacks on text-to-video (T2V) models typically add adversarial perturbations to obviously unsafe prompts, which are often easy to detect and defend. In contrast, we show that benign-looking prompts containing rich, implicit cues can induce T2V models to generate semantically unsafe videos that both violate policy and preserve the original (blocked) intent. To realize this, we propose VEIL, a jailbreak framework that leverages T2V models' cross-modal associative patterns via a modular prompt design. Specifically, our prompts combine three components: neutral scene anchors, which provide the surface-level scene description extracted from the blocked intent to maintain plausibility; latent auditory triggers, textual descriptions of innocuous-sounding audio events (e.g., creaking, muffled noises) that exploit learned audio-visual co-occurrence priors to bias the model toward particular unsafe visual concepts; and stylistic modulators, cinematic directives (e.g., camera framing, atmosphere) that amplify and stabilize the latent trigger's effect. We formalize attack generation as a constrained optimization over the above modular prompt space and solve it with a guided search procedure that balances stealth and effectiveness. Extensive experiments over 7 T2V models demonstrate the efficacy of our attack, achieving a 23 percent improvement in average attack success rate in commercial models.
SLMQuant:Benchmarking Small Language Model Quantization for Practical Deployment
Nov 17, 2025Despite the growing interest in Small Language Models (SLMs) as resource-efficient alternatives to Large Language Models (LLMs), their deployment on edge devices remains challenging due to unresolved efficiency gaps in model compression. While quantization has proven effective for LLMs, its applicability to SLMs is significantly underexplored, with critical questions about differing quantization bottlenecks and efficiency profiles. This paper introduces SLMQuant, the first systematic benchmark for evaluating LLM compression techniques when applied to SLMs. Through comprehensive multi-track evaluations across diverse architectures and tasks, we analyze how state-of-the-art quantization methods perform on SLMs. Our findings reveal fundamental disparities between SLMs and LLMs in quantization sensitivity, demonstrating that direct transfer of LLM-optimized techniques leads to suboptimal results due to SLMs' unique architectural characteristics and training dynamics. We identify key factors governing effective SLM quantization and propose actionable design principles for SLM-tailored compression. SLMQuant establishes a foundational framework for advancing efficient SLM deployment on low-end devices in edge applications, and provides critical insights for deploying lightweight language models in resource-constrained scenarios.
Exploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025



Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles
Aug 20, 2025The generation of safety-critical scenarios in simulation has become increasingly crucial for safety evaluation in autonomous vehicles prior to road deployment in society. However, current approaches largely rely on predefined threat patterns or rule-based strategies, which limit their ability to expose diverse and unforeseen failure modes. To overcome these, we propose ScenGE, a framework that can generate plentiful safety-critical scenarios by reasoning novel adversarial cases and then amplifying them with complex traffic flows. Given a simple prompt of a benign scene, it first performs Meta-Scenario Generation, where a large language model, grounded in structured driving knowledge, infers an adversarial agent whose behavior poses a threat that is both plausible and deliberately challenging. This meta-scenario is then specified in executable code for precise in-simulator control. Subsequently, Complex Scenario Evolution uses background vehicles to amplify the core threat introduced by Meta-Scenario. It builds an adversarial collaborator graph to identify key agent trajectories for optimization. These perturbations are designed to simultaneously reduce the ego vehicle's maneuvering space and create critical occlusions. Extensive experiments conducted on multiple reinforcement learning based AV models show that ScenGE uncovers more severe collision cases (+31.96%) on average than SoTA baselines. Additionally, our ScenGE can be applied to large model based AV systems and deployed on different simulators; we further observe that adversarial training on our scenarios improves the model robustness. Finally, we validate our framework through real-world vehicle tests and human evaluation, confirming that the generated scenarios are both plausible and critical. We hope our paper can build up a critical step towards building public trust and ensuring their safe deployment.
Investigating Training Data Detection in AI Coders
Jul 23, 2025Recent advances in code large language models (CodeLLMs) have made them indispensable tools in modern software engineering. However, these models occasionally produce outputs that contain proprietary or sensitive code snippets, raising concerns about potential non-compliant use of training data, and posing risks to privacy and intellectual property. To ensure responsible and compliant deployment of CodeLLMs, training data detection (TDD) has become a critical task. While recent TDD methods have shown promise in natural language settings, their effectiveness on code data remains largely underexplored. This gap is particularly important given code's structured syntax and distinct similarity criteria compared to natural language. To address this, we conduct a comprehensive empirical study of seven state-of-the-art TDD methods on source code data, evaluating their performance across eight CodeLLMs. To support this evaluation, we introduce CodeSnitch, a function-level benchmark dataset comprising 9,000 code samples in three programming languages, each explicitly labeled as either included or excluded from CodeLLM training. Beyond evaluation on the original CodeSnitch, we design targeted mutation strategies to test the robustness of TDD methods under three distinct settings. These mutation strategies are grounded in the well-established Type-1 to Type-4 code clone detection taxonomy. Our study provides a systematic assessment of current TDD techniques for code and offers insights to guide the development of more effective and robust detection methods in the future.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
LARGO: Low-Rank Regulated Gradient Projection for Robust Parameter Efficient Fine-Tuning
Jun 14, 2025



The advent of parameter-efficient fine-tuning methods has significantly reduced the computational burden of adapting large-scale pretrained models to diverse downstream tasks. However, existing approaches often struggle to achieve robust performance under domain shifts while maintaining computational efficiency. To address this challenge, we propose Low-rAnk Regulated Gradient Projection (LARGO) algorithm that integrates dynamic constraints into low-rank adaptation methods. Specifically, LARGO incorporates parallel trainable gradient projections to dynamically regulate layer-wise updates, retaining the Out-Of-Distribution robustness of pretrained model while preserving inter-layer independence. Additionally, it ensures computational efficiency by mitigating the influence of gradient dependencies across layers during weight updates. Besides, through leveraging singular value decomposition of pretrained weights for structured initialization, we incorporate an SVD-based initialization strategy that minimizing deviation from pretrained knowledge. Through extensive experiments on diverse benchmarks, LARGO achieves state-of-the-art performance across in-domain and out-of-distribution scenarios, demonstrating improved robustness under domain shifts with significantly lower computational overhead compared to existing PEFT methods. The source code will be released soon.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.