 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Design Space of Reward Backpropagation for Flow Matching
Jun 09, 2026Aligning text-to-image flow matching models with human preferences via direct reward backpropagation is sample-efficient but hampered by two well-known pathologies: activations cannot be stored across the full sampling trajectory at modern model scale, and chained Jacobian products across steps inflate the reward gradient as it travels back to early indices. Connector-based methods, such as LeapAlign, address these issues by replacing the full backward trajectory with a short pinned path, highlighting a useful decoupling between sampling and optimization. However, the quality of the resulting gradient depends on how accurately this short path approximates the full rollout, especially over long intervals. We propose FlowBP, a unified surrogate-trajectory framework that treats the backward trajectory itself as the design object. FlowBP keeps a no-gradient cached rollout for sampling, then builds a lightweight backward surrogate from cached and selectively re-forwarded velocities. This view separates four choices: the reward-model input, active set, integration weights, and bridge coupling, and recovers prior direct-gradient methods as particular settings. Within this framework, we instantiate three variants: FlowBP-Sparse uses sparse Euler reconstruction, FlowBP-Bridge adds controlled bridge coupling, and FlowBP-Lagrange raises the order of leap quadrature. All three bound memory by the active-set size and limit gradient chaining to at most one Jacobian factor. Across SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base on preference, quality, and compositional metrics, the three variants improve over direct-gradient baselines on most metrics.
Reinforcing Few-step Generators via Reward-Tilted Distribution Matching
May 28, 2026Recent advances in few-step diffusion distillation have enabled efficient image generation, yet aligning these models with human preferences remains challenging. We propose Reward-Tilted Distribution Matching Distillation (RTDMD), a two-stage framework that unifies distribution matching distillation with reward-guided reinforcement learning for few-step flow generators. We show that minimizing the KL divergence to a reward-tilted teacher distribution naturally decomposes into a distribution matching term and a reward maximization term. In the first stage, we introduce Ambient-Consistent Distribution Matching Distillation (AC-DMD), which performs subinterval-wise distribution matching and augments the fake score objective with a consistency regularizer to help the fake score model track the shifting generator distribution under limited updates. In the second stage, we jointly optimize both terms: for the reward maximization term, we derive a hybrid policy gradient that combines a GRPO-style estimator for the stochastic intermediate transitions with direct reward backpropagation through the deterministic final step, and further introduce step-subset GRPO (SubGRPO) to reduce variance. Experiments on SD3, SD3.5, and FLUX.2 demonstrate that RTDMD establishes new state-of-the-art results across preference, aesthetic, and compositional metrics with only 4 inference steps, outperforming previous few-step text-to-image generation methods. Code and models are available at https://github.com/Harahan/RTDMD.
SGMD: Score Gradient Matching Distillation for Few-Step Video Diffusion Distillation
May 28, 2026Distribution Matching Distillation (DMD) is a widely used paradigm for accelerating inference in few-step video diffusion models. However, DMD-style video distillation faces two coupled challenges: the fake score must track a continuously evolving generator, making training costly when frequent updates are required, while reverse-KL-style matching can be mode-seeking and conservative for preserving strong motion dynamics. To address these issues, we propose \textbf{Score Gradient Matching Distillation (SGMD)}. SGMD adopts a fake-score perspective by directly optimizing the fake score toward the teacher, while using teacher stop-gradient Fisher as a stable distribution-matching objective. We provide a gradient analysis that motivates this objective choice under ideal tracking. Building on this, SGMD introduces a pair of dual potentials: negative-residual (NR) for outer-loop correction and residual-contraction (RC) for inner-loop tracking. Empirically, compared to DMD2, SGMD achieves an approximately $\sim 3\times$ training speedup and substantially improves motion dynamics for 4-step distilled models while preserving temporal consistency. A human study confirms that SGMD is preferred in motion quality and overall preference, while visual quality and text alignment remain comparable. Code is available at https://github.com/ModelTC/LightX2V.
Salt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
Apr 03, 2026Distilling video generation models to extremely low inference budgets (e.g., 2--4 NFEs) is crucial for real-time deployment, yet remains challenging. Trajectory-style consistency distillation often becomes conservative under complex video dynamics, yielding an over-smoothed appearance and weak motion. Distribution matching distillation (DMD) can recover sharp, mode-seeking samples, but its local training signals do not explicitly regularize how denoising updates compose across timesteps, making composed rollouts prone to drift. To overcome this challenge, we propose Self-Consistent Distribution Matching Distillation (SC-DMD), which explicitly regularizes the endpoint-consistent composition of consecutive denoising updates. For real-time autoregressive video generation, we further treat the KV cache as a quality parameterized condition and propose Cache-Distribution-Aware training. This training scheme applies SC-DMD over multi-step rollouts and introduces a cache-conditioned feature alignment objective that steers low-quality outputs toward high-quality references. Across extensive experiments on both non-autoregressive backbones (e.g., Wan~2.1) and autoregressive real-time paradigms (e.g., Self Forcing), our method, dubbed \textbf{Salt}, consistently improves low-NFE video generation quality while remaining compatible with diverse KV-cache memory mechanisms. Source code will be released at \href{https://github.com/XingtongGe/Salt}{https://github.com/XingtongGe/Salt}.
Real-Time Human Frontal View Synthesis from a Single Image
Mar 16, 2026Photorealistic human novel view synthesis from a single image is crucial for democratizing immersive 3D telepresence, eliminating the need for complex multi-camera setups. However, current rendering-centric methods prioritize visual fidelity over explicit geometric understanding and struggle with intricate regions like faces and hands, leading to temporal instability. Meanwhile, human-centric frameworks suffer from memory bottlenecks since they typically rely on an auxiliary model to provide informative structural priors for geometric modeling, which limits real-time performance. To address these challenges, we propose PrismMirror, a geometry-guided framework for instant frontal view synthesis from a single image. By avoiding external geometric modeling and focusing on frontal view synthesis, our model optimizes visual integrity for telepresence. Specifically, PrismMirror introduces a novel cascade learning strategy that enables coarse-to-fine geometric feature learning. It first directly learns coarse geometric features, such as SMPL-X meshes and point clouds, and then refines textures through rendering supervision. To achieve real-time efficiency, we distill this unified framework into a lightweight linear attention model. Notably, PrismMirror is the first monocular human frontal view synthesis model that achieves real-time inference at 24 FPS, significantly outperforming previous methods in both visual authenticity and structural accuracy.
Flash-VAED: Plug-and-Play VAE Decoders for Efficient Video Generation
Feb 22, 2026Latent diffusion models have enabled high-quality video synthesis, yet their inference remains costly and time-consuming. As diffusion transformers become increasingly efficient, the latency bottleneck inevitably shifts to VAE decoders. To reduce their latency while maintaining quality, we propose a universal acceleration framework for VAE decoders that preserves full alignment with the original latent distribution. Specifically, we propose (1) an independence-aware channel pruning method to effectively mitigate severe channel redundancy, and (2) a stage-wise dominant operator optimization strategy to address the high inference cost of the widely used causal 3D convolutions in VAE decoders. Based on these innovations, we construct a Flash-VAED family. Moreover, we design a three-phase dynamic distillation framework that efficiently transfers the capabilities of the original VAE decoder to Flash-VAED. Extensive experiments on Wan and LTX-Video VAE decoders demonstrate that our method outperforms baselines in both quality and speed, achieving approximately a 6$\times$ speedup while maintaining the reconstruction performance up to 96.9%. Notably, Flash-VAED accelerates the end-to-end generation pipeline by up to 36% with negligible quality drops on VBench-2.0.
Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025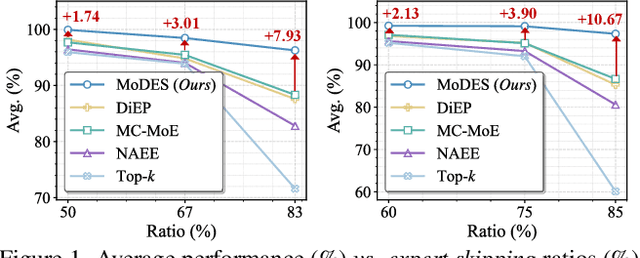
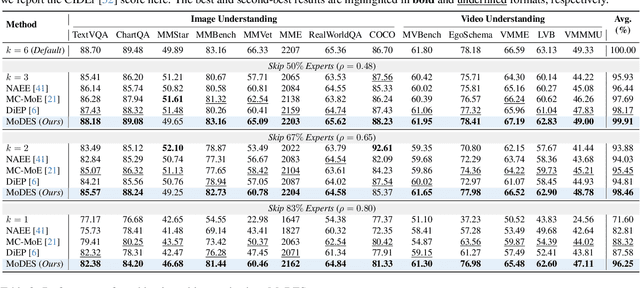
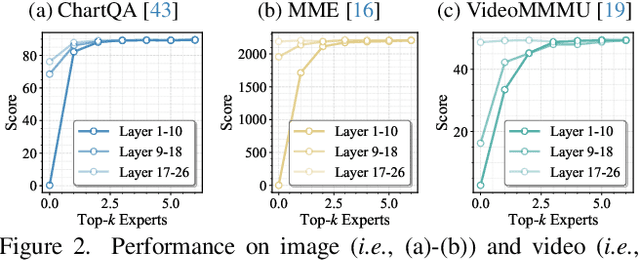
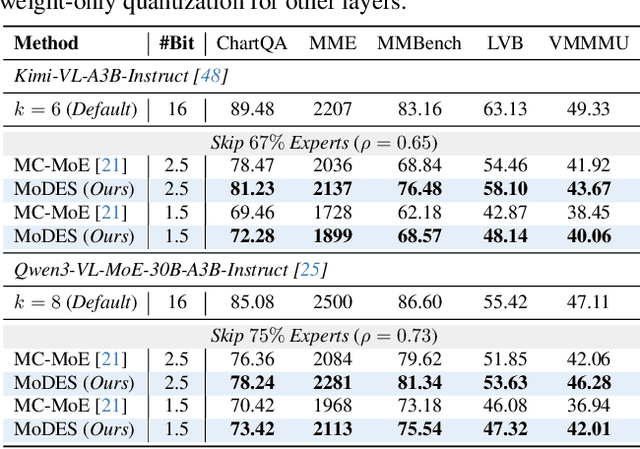
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
LLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.