 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Label Refinery for Unsupervised Domain Adaptation on Cross-dataset 3D Object Detection
Apr 30, 2024



Recent self-training techniques have shown notable improvements in unsupervised domain adaptation for 3D object detection (3D UDA). These techniques typically select pseudo labels, i.e., 3D boxes, to supervise models for the target domain. However, this selection process inevitably introduces unreliable 3D boxes, in which 3D points cannot be definitively assigned as foreground or background. Previous techniques mitigate this by reweighting these boxes as pseudo labels, but these boxes can still poison the training process. To resolve this problem, in this paper, we propose a novel pseudo label refinery framework. Specifically, in the selection process, to improve the reliability of pseudo boxes, we propose a complementary augmentation strategy. This strategy involves either removing all points within an unreliable box or replacing it with a high-confidence box. Moreover, the point numbers of instances in high-beam datasets are considerably higher than those in low-beam datasets, also degrading the quality of pseudo labels during the training process. We alleviate this issue by generating additional proposals and aligning RoI features across different domains. Experimental results demonstrate that our method effectively enhances the quality of pseudo labels and consistently surpasses the state-of-the-art methods on six autonomous driving benchmarks. Code will be available at https://github.com/Zhanwei-Z/PERE.
Model Compression and Efficient Inference for Large Language Models: A Survey
Feb 15, 2024



Transformer based large language models have achieved tremendous success. However, the significant memory and computational costs incurred during the inference process make it challenging to deploy large models on resource-constrained devices. In this paper, we investigate compression and efficient inference methods for large language models from an algorithmic perspective. Regarding taxonomy, similar to smaller models, compression and acceleration algorithms for large language models can still be categorized into quantization, pruning, distillation, compact architecture design, dynamic networks. However, Large language models have two prominent characteristics compared to smaller models: (1) Most of compression algorithms require finetuning or even retraining the model after compression. The most notable aspect of large models is the very high cost associated with model finetuning or training. Therefore, many algorithms for large models, such as quantization and pruning, start to explore tuning-free algorithms. (2) Large models emphasize versatility and generalization rather than performance on a single task. Hence, many algorithms, such as knowledge distillation, focus on how to preserving their versatility and generalization after compression. Since these two characteristics were not very pronounced in early large models, we further distinguish large language models into medium models and ``real'' large models. Additionally, we also provide an introduction to some mature frameworks for efficient inference of large models, which can support basic compression or acceleration algorithms, greatly facilitating model deployment for users.
Regulating Intermediate 3D Features for Vision-Centric Autonomous Driving
Dec 19, 2023



Multi-camera perception tasks have gained significant attention in the field of autonomous driving. However, existing frameworks based on Lift-Splat-Shoot (LSS) in the multi-camera setting cannot produce suitable dense 3D features due to the projection nature and uncontrollable densification process. To resolve this problem, we propose to regulate intermediate dense 3D features with the help of volume rendering. Specifically, we employ volume rendering to process the dense 3D features to obtain corresponding 2D features (e.g., depth maps, semantic maps), which are supervised by associated labels in the training. This manner regulates the generation of dense 3D features on the feature level, providing appropriate dense and unified features for multiple perception tasks. Therefore, our approach is termed Vampire, stands for "Volume rendering As Multi-camera Perception Intermediate feature REgulator". Experimental results on the Occ3D and nuScenes datasets demonstrate that Vampire facilitates fine-grained and appropriate extraction of dense 3D features, and is competitive with existing SOTA methods across diverse downstream perception tasks like 3D occupancy prediction, LiDAR segmentation and 3D objection detection, while utilizing moderate GPU resources. We provide a video demonstration in the supplementary materials and Codes are available at github.com/cskkxjk/Vampire.
To be or not to be? an exploration of continuously controllable prompt engineering
Nov 16, 2023



As the use of large language models becomes more widespread, techniques like parameter-efficient fine-tuning and other methods for controlled generation are gaining traction for customizing models and managing their outputs. However, the challenge of precisely controlling how prompts influence these models is an area ripe for further investigation. In response, we introduce ControlPE (Continuously Controllable Prompt Engineering). ControlPE enables finer adjustments to prompt effects, complementing existing prompt engineering, and effectively controls continuous targets. This approach harnesses the power of LoRA (Low-Rank Adaptation) to create an effect akin to prompt weighting, enabling fine-tuned adjustments to the impact of prompts. Our methodology involves generating specialized datasets for prompt distillation, incorporating these prompts into the LoRA model, and carefully adjusting LoRA merging weight to regulate the influence of prompts. This provides a dynamic and adaptable tool for prompt control. Through our experiments, we have validated the practicality and efficacy of ControlPE. It proves to be a promising solution for control a variety of prompts, ranging from generating short responses prompts, refusal prompts to chain-of-thought prompts.
Few-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023



Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.
Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks
Sep 29, 2023In light of recent advancements in generative AI models, it has become essential to distinguish genuine content from AI-generated one to prevent the malicious usage of fake materials as authentic ones and vice versa. Various techniques have been introduced for identifying AI-generated images, with watermarking emerging as a promising approach. In this paper, we analyze the robustness of various AI-image detectors including watermarking and classifier-based deepfake detectors. For watermarking methods that introduce subtle image perturbations (i.e., low perturbation budget methods), we reveal a fundamental trade-off between the evasion error rate (i.e., the fraction of watermarked images detected as non-watermarked ones) and the spoofing error rate (i.e., the fraction of non-watermarked images detected as watermarked ones) upon an application of a diffusion purification attack. In this regime, we also empirically show that diffusion purification effectively removes watermarks with minimal changes to images. For high perturbation watermarking methods where notable changes are applied to images, the diffusion purification attack is not effective. In this case, we develop a model substitution adversarial attack that can successfully remove watermarks. Moreover, we show that watermarking methods are vulnerable to spoofing attacks where the attacker aims to have real images (potentially obscene) identified as watermarked ones, damaging the reputation of the developers. In particular, by just having black-box access to the watermarking method, we show that one can generate a watermarked noise image which can be added to the real images to have them falsely flagged as watermarked ones. Finally, we extend our theory to characterize a fundamental trade-off between the robustness and reliability of classifier-based deep fake detectors and demonstrate it through experiments.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
Aug 18, 2023



In the field of monocular 3D detection, it is common practice to utilize scene geometric clues to enhance the detector's performance. However, many existing works adopt these clues explicitly such as estimating a depth map and back-projecting it into 3D space. This explicit methodology induces sparsity in 3D representations due to the increased dimensionality from 2D to 3D, and leads to substantial information loss, especially for distant and occluded objects. To alleviate this issue, we propose MonoNeRD, a novel detection framework that can infer dense 3D geometry and occupancy. Specifically, we model scenes with Signed Distance Functions (SDF), facilitating the production of dense 3D representations. We treat these representations as Neural Radiance Fields (NeRF) and then employ volume rendering to recover RGB images and depth maps. To the best of our knowledge, this work is the first to introduce volume rendering for M3D, and demonstrates the potential of implicit reconstruction for image-based 3D perception. Extensive experiments conducted on the KITTI-3D benchmark and Waymo Open Dataset demonstrate the effectiveness of MonoNeRD. Codes are available at https://github.com/cskkxjk/MonoNeRD.
A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation
Aug 01, 2023
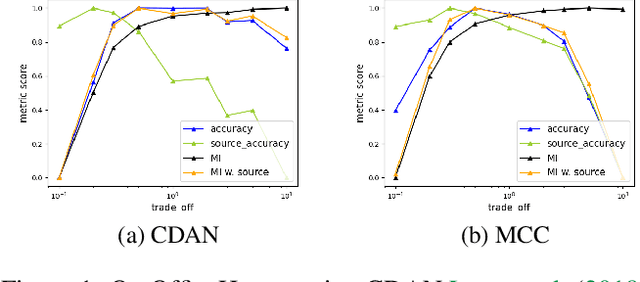
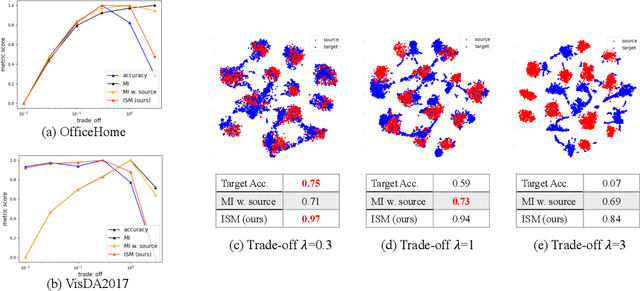
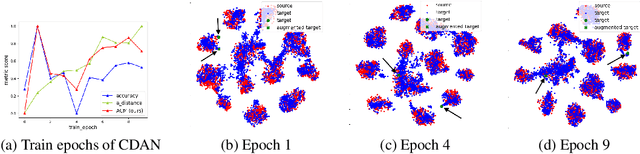
Unsupervised domain adaptation (UDA) methods facilitate the transfer of models to target domains without labels. However, these methods necessitate a labeled target validation set for hyper-parameter tuning and model selection. In this paper, we aim to find an evaluation metric capable of assessing the quality of a transferred model without access to target validation labels. We begin with the metric based on mutual information of the model prediction. Through empirical analysis, we identify three prevalent issues with this metric: 1) It does not account for the source structure. 2) It can be easily attacked. 3) It fails to detect negative transfer caused by the over-alignment of source and target features. To address the first two issues, we incorporate source accuracy into the metric and employ a new MLP classifier that is held out during training, significantly improving the result. To tackle the final issue, we integrate this enhanced metric with data augmentation, resulting in a novel unsupervised UDA metric called the Augmentation Consistency Metric (ACM). Additionally, we empirically demonstrate the shortcomings of previous experiment settings and conduct large-scale experiments to validate the effectiveness of our proposed metric. Furthermore, we employ our metric to automatically search for the optimal hyper-parameter set, achieving superior performance compared to manually tuned sets across four common benchmarks. Codes will be available soon.
On Practical Aspects of Aggregation Defenses against Data Poisoning Attacks
Jun 28, 2023The increasing access to data poses both opportunities and risks in deep learning, as one can manipulate the behaviors of deep learning models with malicious training samples. Such attacks are known as data poisoning. Recent advances in defense strategies against data poisoning have highlighted the effectiveness of aggregation schemes in achieving state-of-the-art results in certified poisoning robustness. However, the practical implications of these approaches remain unclear. Here we focus on Deep Partition Aggregation, a representative aggregation defense, and assess its practical aspects, including efficiency, performance, and robustness. For evaluations, we use ImageNet resized to a resolution of 64 by 64 to enable evaluations at a larger scale than previous ones. Firstly, we demonstrate a simple yet practical approach to scaling base models, which improves the efficiency of training and inference for aggregation defenses. Secondly, we provide empirical evidence supporting the data-to-complexity ratio, i.e. the ratio between the data set size and sample complexity, as a practical estimation of the maximum number of base models that can be deployed while preserving accuracy. Last but not least, we point out how aggregation defenses boost poisoning robustness empirically through the poisoning overfitting phenomenon, which is the key underlying mechanism for the empirical poisoning robustness of aggregations. Overall, our findings provide valuable insights for practical implementations of aggregation defenses to mitigate the threat of data poisoning.