 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Real-Time Execution of Transformer-based Large-scale Models on Mobile with Compiler-aware Neural Architecture Optimization
Sep 15, 2020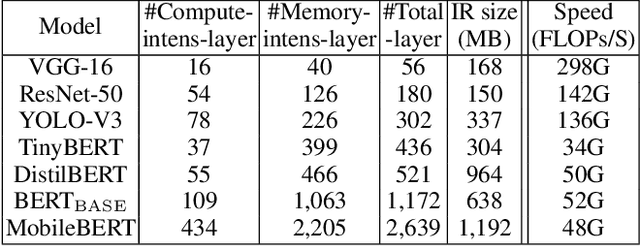
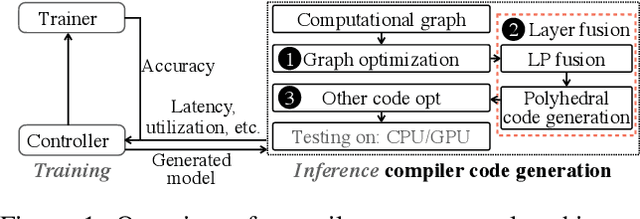
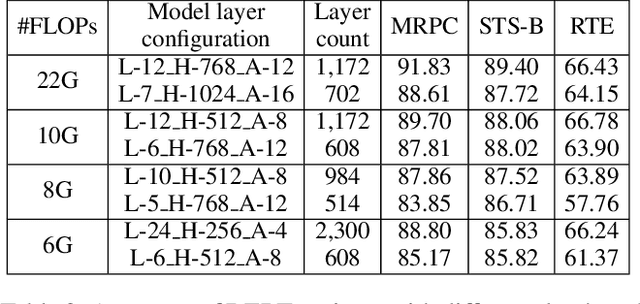
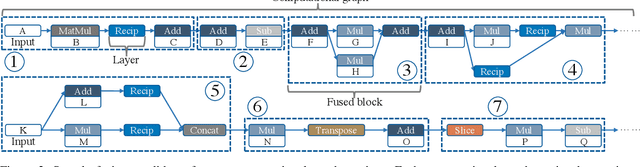
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this paper, we seek to find the best model structure of BERT for a given computation size to match specific devices. We propose the first compiler-aware neural architecture optimization framework (called CANAO). CANAO can guarantee the identified model to meet both resource and real-time specifications of mobile devices, thus achieving real-time execution of large transformer-based models like BERT variants. We evaluate our model on several NLP tasks, achieving competitive results on well-known benchmarks with lower latency on mobile devices. Specifically, our model is 5.2x faster on CPU and 4.1x faster on GPU with 0.5-2% accuracy loss compared with BERT-base. Our overall framework achieves up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss.
Towards Cardiac Intervention Assistance: Hardware-aware Neural Architecture Exploration for Real-Time 3D Cardiac Cine MRI Segmentation
Aug 17, 2020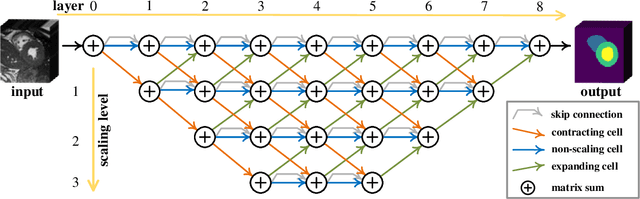
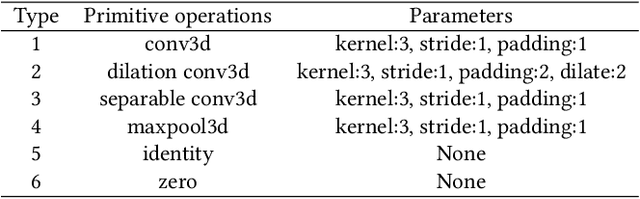
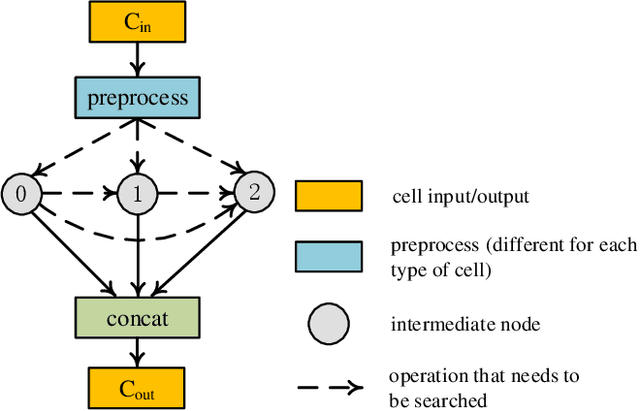
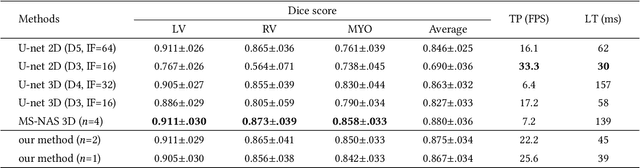
Real-time cardiac magnetic resonance imaging (MRI) plays an increasingly important role in guiding various cardiac interventions. In order to provide better visual assistance, the cine MRI frames need to be segmented on-the-fly to avoid noticeable visual lag. In addition, considering reliability and patient data privacy, the computation is preferably done on local hardware. State-of-the-art MRI segmentation methods mostly focus on accuracy only, and can hardly be adopted for real-time application or on local hardware. In this work, we present the first hardware-aware multi-scale neural architecture search (NAS) framework for real-time 3D cardiac cine MRI segmentation. The proposed framework incorporates a latency regularization term into the loss function to handle real-time constraints, with the consideration of underlying hardware. In addition, the formulation is fully differentiable with respect to the architecture parameters, so that stochastic gradient descent (SGD) can be used for optimization to reduce the computation cost while maintaining optimization quality. Experimental results on ACDC MICCAI 2017 dataset demonstrate that our hardware-aware multi-scale NAS framework can reduce the latency by up to 3.5 times and satisfy the real-time constraints, while still achieving competitive segmentation accuracy, compared with the state-of-the-art NAS segmentation framework.
Standing on the Shoulders of Giants: Hardware and Neural Architecture Co-Search with Hot Start
Jul 17, 2020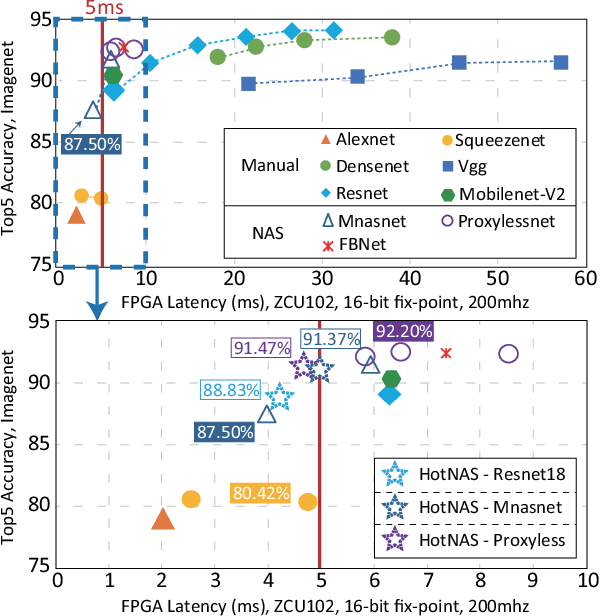
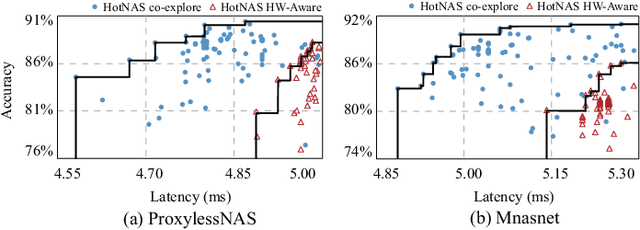
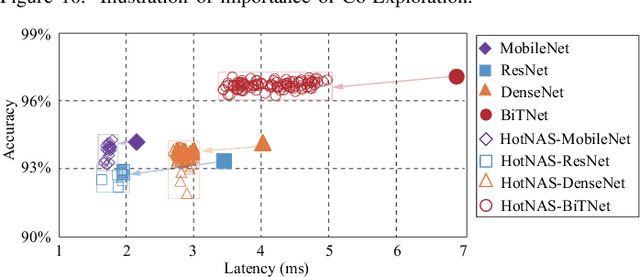
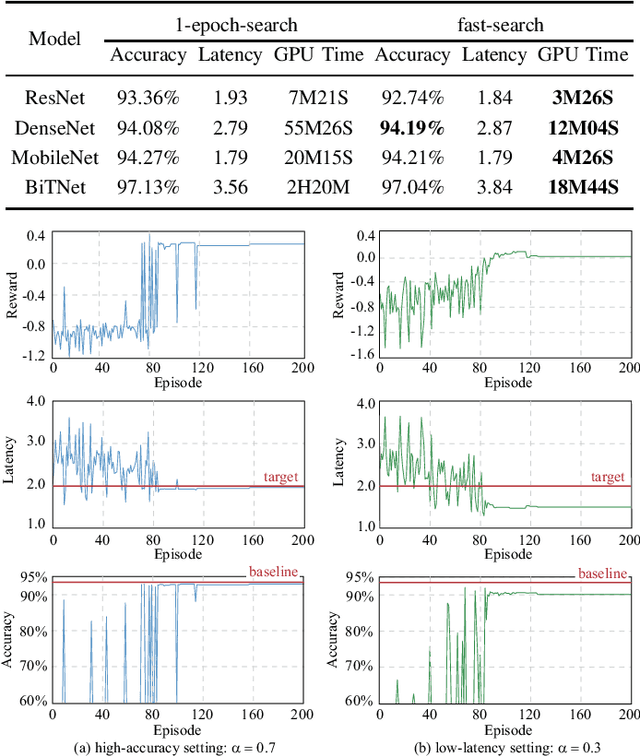
Hardware and neural architecture co-search that automatically generates Artificial Intelligence (AI) solutions from a given dataset is promising to promote AI democratization; however, the amount of time that is required by current co-search frameworks is in the order of hundreds of GPU hours for one target hardware. This inhibits the use of such frameworks on commodity hardware. The root cause of the low efficiency in existing co-search frameworks is the fact that they start from a "cold" state (i.e., search from scratch). In this paper, we propose a novel framework, namely HotNAS, that starts from a "hot" state based on a set of existing pre-trained models (a.k.a. model zoo) to avoid lengthy training time. As such, the search time can be reduced from 200 GPU hours to less than 3 GPU hours. In HotNAS, in addition to hardware design space and neural architecture search space, we further integrate a compression space to conduct model compressing during the co-search, which creates new opportunities to reduce latency but also brings challenges. One of the key challenges is that all of the above search spaces are coupled with each other, e.g., compression may not work without hardware design support. To tackle this issue, HotNAS builds a chain of tools to design hardware to support compression, based on which a global optimizer is developed to automatically co-search all the involved search spaces. Experiments on ImageNet dataset and Xilinx FPGA show that, within the timing constraint of 5ms, neural architectures generated by HotNAS can achieve up to 5.79% Top-1 and 3.97% Top-5 accuracy gain, compared with the existing ones.
BUNET: Blind Medical Image Segmentation Based on Secure UNET
Jul 14, 2020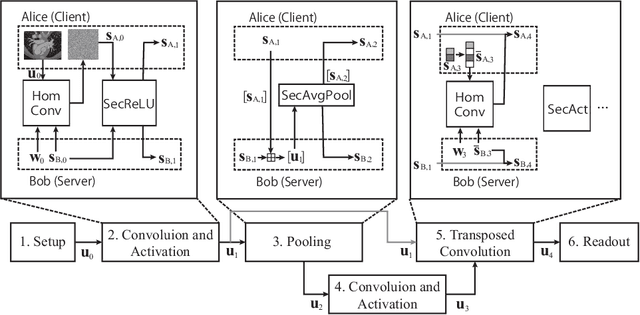
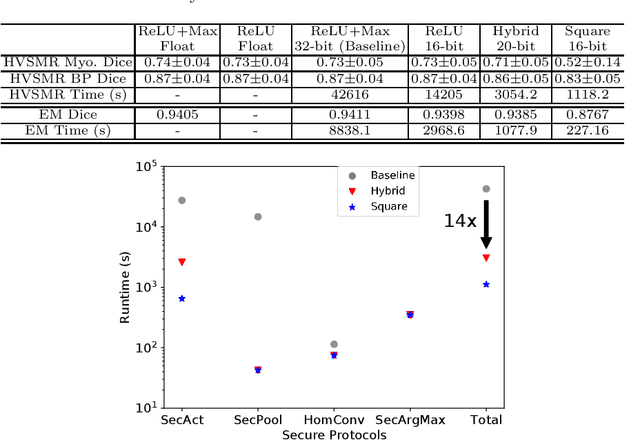
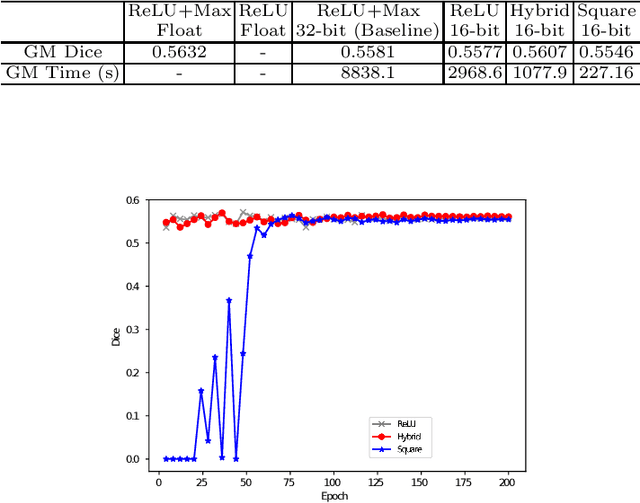
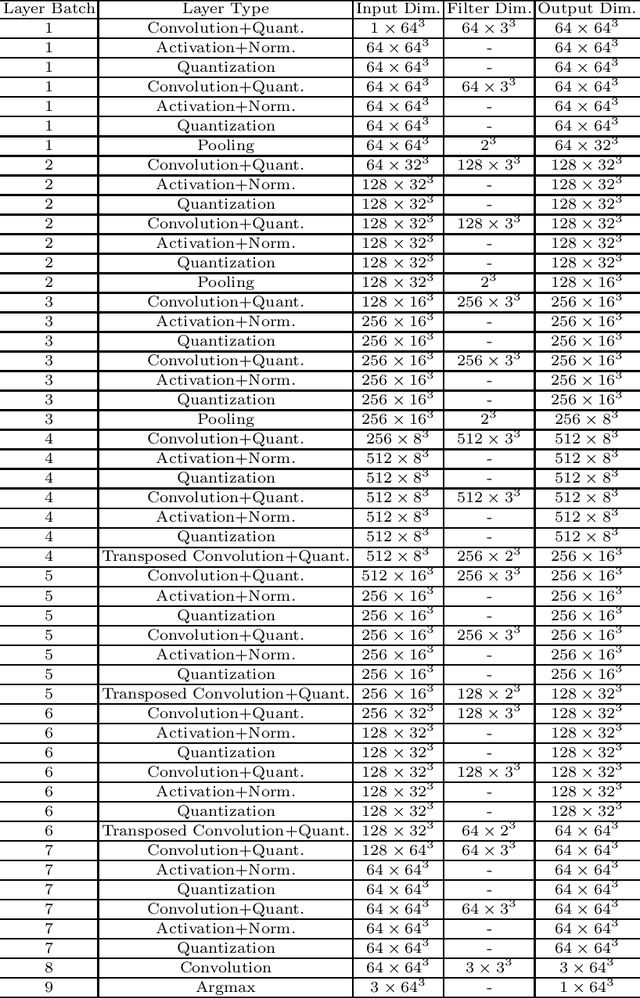
The strict security requirements placed on medical records by various privacy regulations become major obstacles in the age of big data. To ensure efficient machine learning as a service schemes while protecting data confidentiality, in this work, we propose blind UNET (BUNET), a secure protocol that implements privacy-preserving medical image segmentation based on the UNET architecture. In BUNET, we efficiently utilize cryptographic primitives such as homomorphic encryption and garbled circuits (GC) to design a complete secure protocol for the UNET neural architecture. In addition, we perform extensive architectural search in reducing the computational bottleneck of GC-based secure activation protocols with high-dimensional input data. In the experiment, we thoroughly examine the parameter space of our protocol, and show that we can achieve up to 14x inference time reduction compared to the-state-of-the-art secure inference technique on a baseline architecture with negligible accuracy degradation.
MS-NAS: Multi-Scale Neural Architecture Search for Medical Image Segmentation
Jul 13, 2020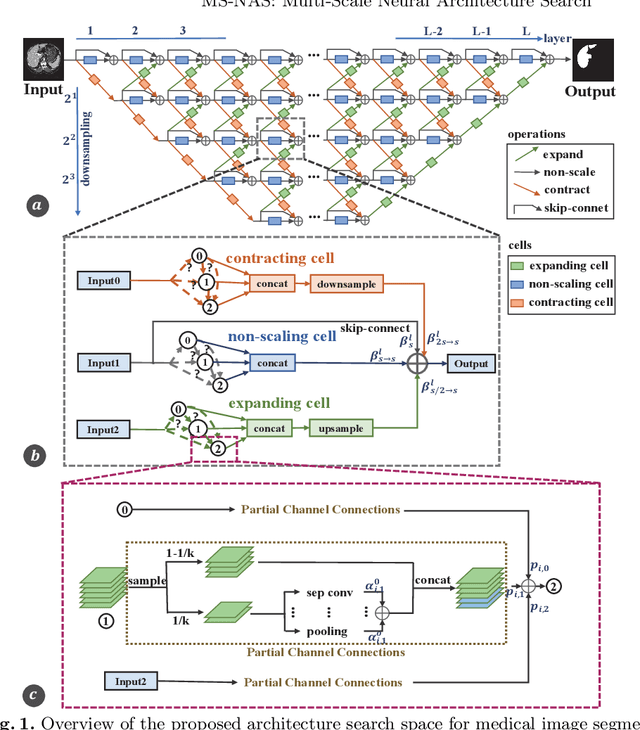

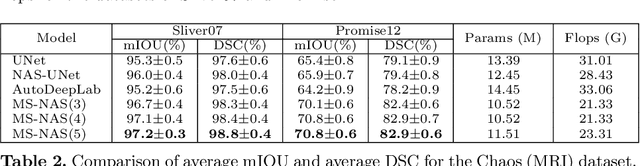
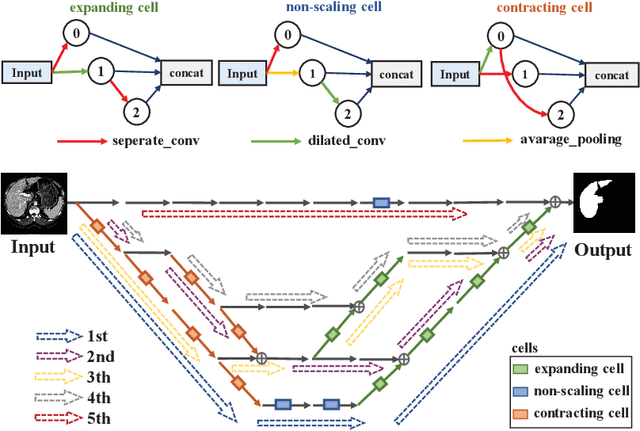
The recent breakthroughs of Neural Architecture Search (NAS) have motivated various applications in medical image segmentation. However, most existing work either simply rely on hyper-parameter tuning or stick to a fixed network backbone, thereby limiting the underlying search space to identify more efficient architecture. This paper presents a Multi-Scale NAS (MS-NAS) framework that is featured with multi-scale search space from network backbone to cell operation, and multi-scale fusion capability to fuse features with different sizes. To mitigate the computational overhead due to the larger search space, a partial channel connection scheme and a two-step decoding method are utilized to reduce computational overhead while maintaining optimization quality. Experimental results show that on various datasets for segmentation, MS-NAS outperforms the state-of-the-art methods and achieves 0.6-5.4% mIOU and 0.4-3.5% DSC improvements, while the computational resource consumption is reduced by 18.0-24.9%.
Can Quantum Computers Learn Like Classical Computers? A Co-Design Framework for Machine Learning and Quantum Circuits
Jun 26, 2020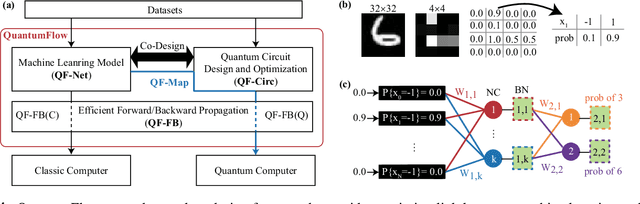
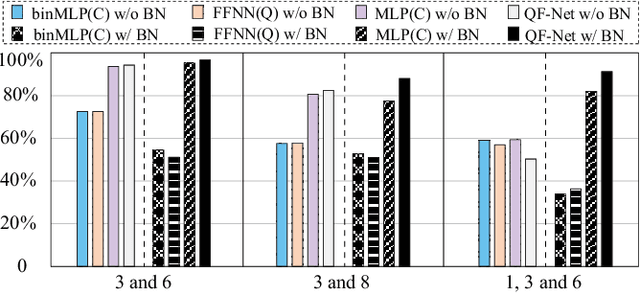
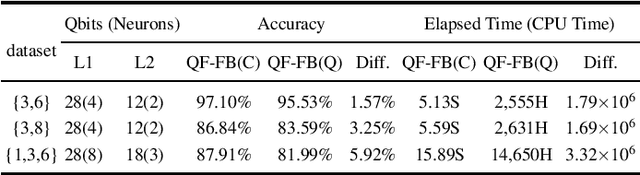
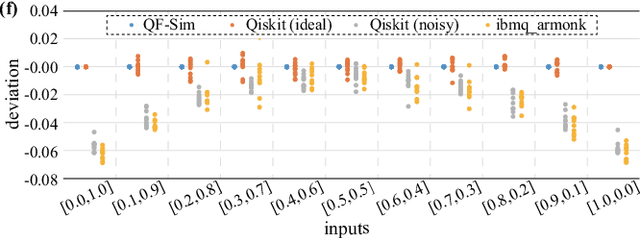
Despite the pursuit of quantum supremacy in various applications, the power of quantum computers in machine learning (such as neural network models) has mostly remained unknown, primarily due to a missing link that effectively designs a neural network model suitable for quantum circuit implementation. In this article, we present the first co-design framework, namely QuantumFlow, to fixed the missing link. QuantumFlow consists of a novel quantum-friendly neural network (QF-Net) design, an automatic tool (QF-Map) to generate the quantum circuit (QF-Circ) for QF-Net, and a theoretic-based execution engine (QF-FB) to efficiently support the training of QF-Net on a classical computer. We discover that, in order to make full use of the strength of quantum representation, data in QF-Net is best modeled as random variables rather than real numbers. Moreover, instead of using the classical batch normalization (which is key to achieve high accuracy for deep neural networks), a quantum-aware batch normalization method is proposed for QF-Net. Evaluation results show that QF-Net can achieve 97.01% accuracy in distinguishing digits 3 and 6 in the widely used MNIST dataset, which is 14.55% higher than the state-of-the-art quantum-aware implementation. A case study on a binary classification application is conducted. Running on IBM Quantum processor's "ibmq_essex" backend, a neural network designed by QuantumFlow can achieve 82% accuracy. To the best of our knowledge, QuantumFlow is the first framework that co-designs both the machine learning model and its quantum circuit.
NASS: Optimizing Secure Inference via Neural Architecture Search
Feb 16, 2020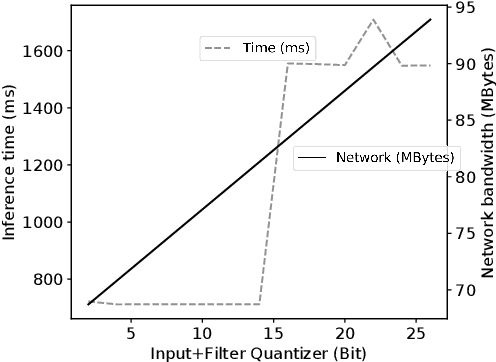
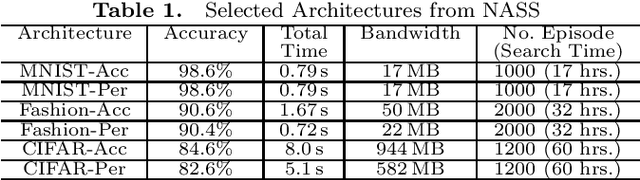
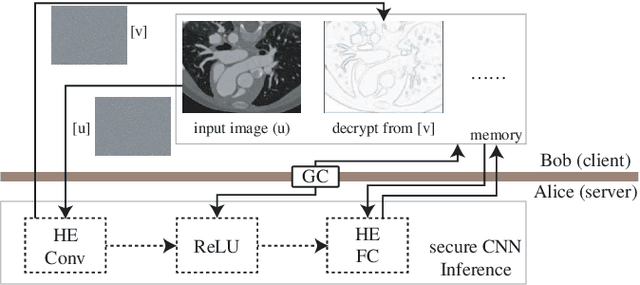
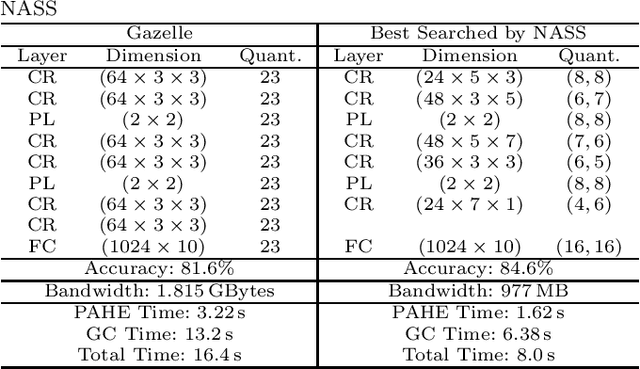
Due to increasing privacy concerns, neural network (NN) based secure inference (SI) schemes that simultaneously hide the client inputs and server models attract major research interests. While existing works focused on developing secure protocols for NN-based SI, in this work, we take a different approach. We propose NASS, an integrated framework to search for tailored NN architectures designed specifically for SI. In particular, we propose to model cryptographic protocols as design elements with associated reward functions. The characterized models are then adopted in a joint optimization with predicted hyperparameters in identifying the best NN architectures that balance prediction accuracy and execution efficiency. In the experiment, it is demonstrated that we can achieve the best of both worlds by using NASS, where the prediction accuracy can be improved from 81.6% to 84.6%, while the inference runtime is reduced by 2x and communication bandwidth by 1.9x on the CIFAR-10 dataset.
Co-Exploration of Neural Architectures and Heterogeneous ASIC Accelerator Designs Targeting Multiple Tasks
Feb 10, 2020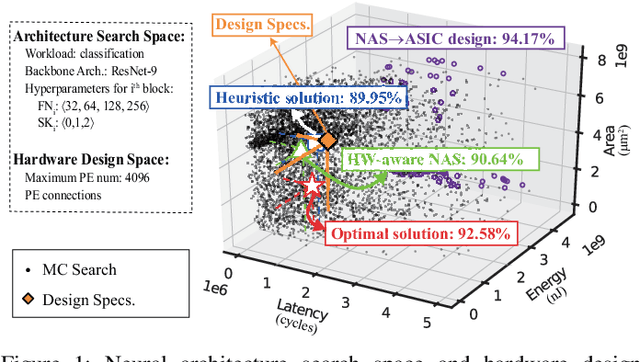
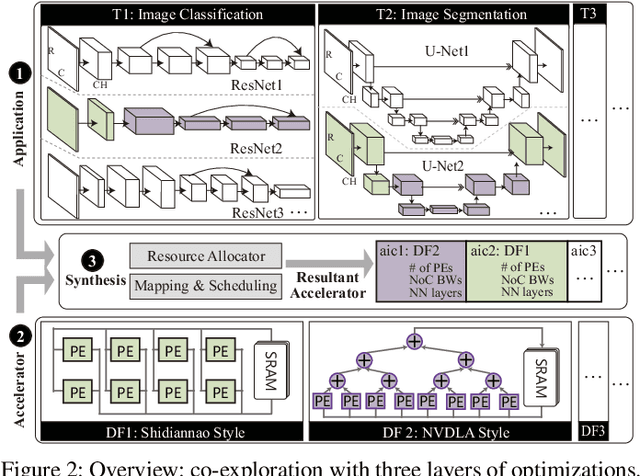
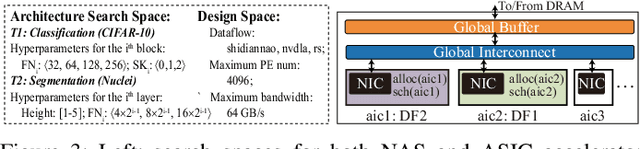
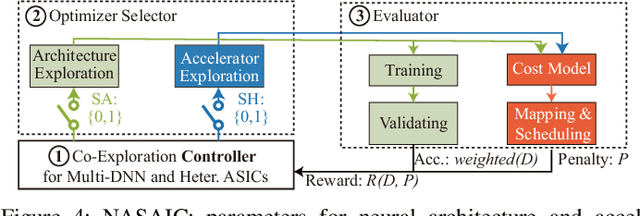
Neural Architecture Search (NAS) has demonstrated its power on various AI accelerating platforms such as Field Programmable Gate Arrays (FPGAs) and Graphic Processing Units (GPUs). However, it remains an open problem, how to integrate NAS with Application-Specific Integrated Circuits (ASICs), despite them being the most powerful AI accelerating platforms. The major bottleneck comes from the large design freedom associated with ASIC designs. Moreover, with the consideration that multiple DNNs will run in parallel for different workloads with diverse layer operations and sizes, integrating heterogeneous ASIC sub-accelerators for distinct DNNs in one design can significantly boost performance, and at the same time further complicate the design space. To address these challenges, in this paper we build ASIC template set based on existing successful designs, described by their unique dataflows, so that the design space is significantly reduced. Based on the templates, we further propose a framework, namely NASAIC, which can simultaneously identify multiple DNN architectures and the associated heterogeneous ASIC accelerator design, such that the design specifications (specs) can be satisfied, while the accuracy can be maximized. Experimental results show that compared with successive NAS and ASIC design optimizations which lead to design spec violations, NASAIC can guarantee the results to meet the design specs with 17.77%, 2.49x, and 2.32x reductions on latency, energy, and area and with 0.76% accuracy loss. To the best of the authors' knowledge, this is the first work on neural architecture and ASIC accelerator design co-exploration.
Device-Circuit-Architecture Co-Exploration for Computing-in-Memory Neural Accelerators
Oct 31, 2019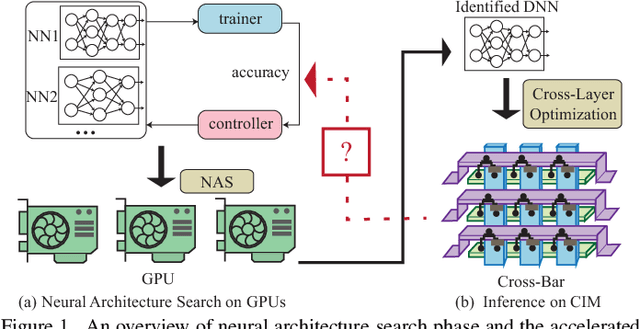
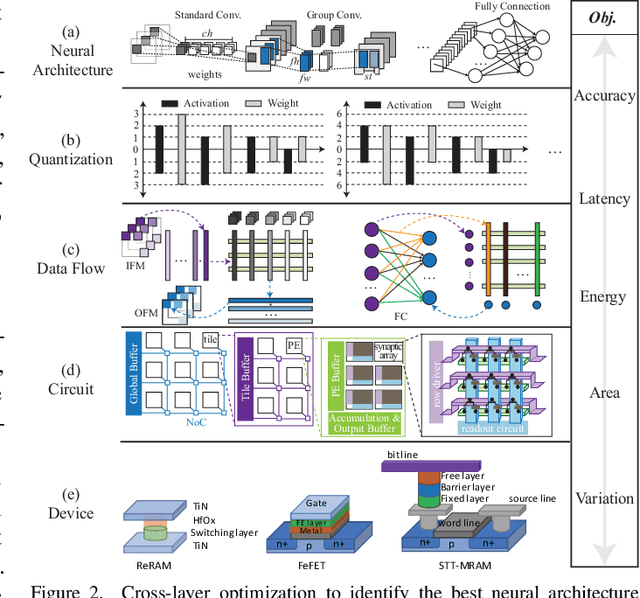
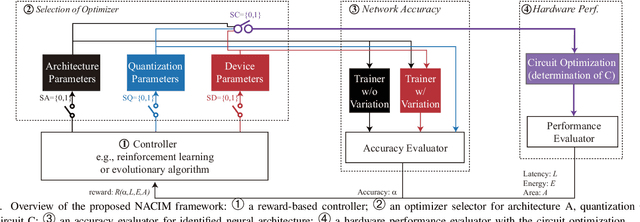
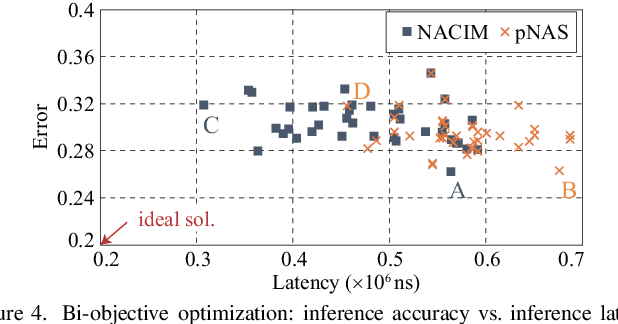
Co-exploration of neural architectures and hardware design is promising to simultaneously optimize network accuracy and hardware efficiency. However, state-of-the-art neural architecture search algorithms for the co-exploration are dedicated for the conventional von-neumann computing architecture, whose performance is heavily limited by the well-known memory wall. In this paper, we are the first to bring the computing-in-memory architecture, which can easily transcend the memory wall, to interplay with the neural architecture search, aiming to find the most efficient neural architectures with high network accuracy and maximized hardware efficiency. Such a novel combination makes opportunities to boost performance, but also brings a bunch of challenges. The design space spans across multiple layers from device type, circuit topology to neural architecture. In addition, the performance may degrade in the presence of device variation. To address these challenges, we propose a cross-layer exploration framework, namely NACIM, which jointly explores device, circuit and architecture design space and takes device variation into consideration to find the most robust neural architectures. Experimental results demonstrate that NACIM can find the robust neural network with 0.45% accuracy loss in the presence of device variation, compared with a 76.44% loss from the state-of-the-art NAS without consideration of variation; in addition, NACIM achieves an energy efficiency up to 16.3 TOPs/W, 3.17X higher than the state-of-the-art NAS.
On Neural Architecture Search for Resource-Constrained Hardware Platforms
Oct 31, 2019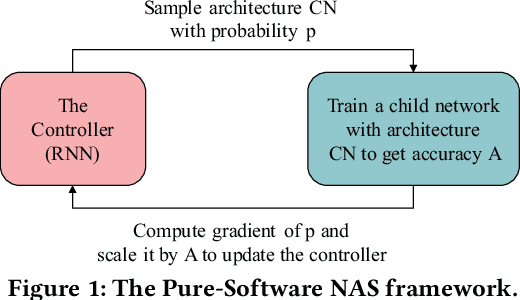
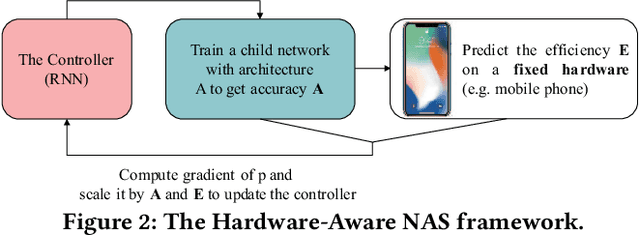

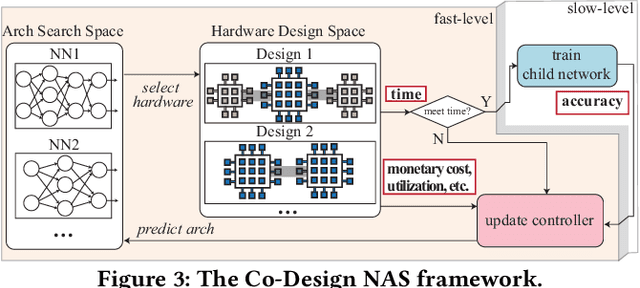
In the recent past, the success of Neural Architecture Search (NAS) has enabled researchers to broadly explore the design space using learning-based methods. Apart from finding better neural network architectures, the idea of automation has also inspired to improve their implementations on hardware. While some practices of hardware machine-learning automation have achieved remarkable performance, the traditional design concept is still followed: a network architecture is first structured with excellent test accuracy, and then compressed and optimized to fit into a target platform. Such a design flow will easily lead to inferior local-optimal solutions. To address this problem, we propose a new framework to jointly explore the space of neural architecture, hardware implementation, and quantization. Our objective is to find a quantized architecture with the highest accuracy that is implementable on given hardware specifications. We employ FPGAs to implement and test our designs with limited loop-up tables (LUTs) and required throughput. Compared to the separate design/searching methods, our framework has demonstrated much better performance under strict specifications and generated designs of higher accuracy by 18\% to 68\% in the task of classifying CIFAR10 images. With 30,000 LUTs, a light-weight design is found to achieve 82.98\% accuracy and 1293 images/second throughput, compared to which, under the same constraints, the traditional method even fails to find a valid solution.