 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Forgetting: Attack Unlearned Diffusion via Initial Latent Variable Optimization
Jan 30, 2026Although unlearning-based defenses claim to purge Not-Safe-For-Work (NSFW) concepts from diffusion models (DMs), we reveals that this "forgetting" is largely an illusion. Unlearning partially disrupts the mapping between linguistic symbols and the underlying knowledge, which remains intact as dormant memories. We find that the distributional discrepancy in the denoising process serves as a measurable indicator of how much of the mapping is retained, also reflecting the strength of unlearning. Inspired by this, we propose IVO (Initial Latent Variable Optimization), a concise and powerful attack framework that reactivates these dormant memories by reconstructing the broken mappings. Through Image Inversion}, Adversarial Optimization and Reused Attack, IVO optimizes initial latent variables to realign the noise distribution of unlearned models with their original unsafe states. Extensive experiments across 8 widely used unlearning techniques demonstrate that IVO achieves superior attack success rates and strong semantic consistency, exposing fundamental flaws in current defenses. The code is available at anonymous.4open.science/r/IVO/. Warning: This paper has unsafe images that may offend some readers.
SoLA-Vision: Fine-grained Layer-wise Linear Softmax Hybrid Attention
Jan 16, 2026Standard softmax self-attention excels in vision tasks but incurs quadratic complexity O(N^2), limiting high-resolution deployment. Linear attention reduces the cost to O(N), yet its compressed state representations can impair modeling capacity and accuracy. We present an analytical study that contrasts linear and softmax attention for visual representation learning from a layer-stacking perspective. We further conduct systematic experiments on layer-wise hybridization patterns of linear and softmax attention. Our results show that, compared with rigid intra-block hybrid designs, fine-grained layer-wise hybridization can match or surpass performance while requiring fewer softmax layers. Building on these findings, we propose SoLA-Vision (Softmax-Linear Attention Vision), a flexible layer-wise hybrid attention backbone that enables fine-grained control over how linear and softmax attention are integrated. By strategically inserting a small number of global softmax layers, SoLA-Vision achieves a strong trade-off between accuracy and computational cost. On ImageNet-1K, SoLA-Vision outperforms purely linear and other hybrid attention models. On dense prediction tasks, it consistently surpasses strong baselines by a considerable margin. Code will be released.
Integrating Diverse Assignment Strategies into DETRs
Jan 14, 2026Label assignment is a critical component in object detectors, particularly within DETR-style frameworks where the one-to-one matching strategy, despite its end-to-end elegance, suffers from slow convergence due to sparse supervision. While recent works have explored one-to-many assignments to enrich supervisory signals, they often introduce complex, architecture-specific modifications and typically focus on a single auxiliary strategy, lacking a unified and scalable design. In this paper, we first systematically investigate the effects of ``one-to-many'' supervision and reveal a surprising insight that performance gains are driven not by the sheer quantity of supervision, but by the diversity of the assignment strategies employed. This finding suggests that a more elegant, parameter-efficient approach is attainable. Building on this insight, we propose LoRA-DETR, a flexible and lightweight framework that seamlessly integrates diverse assignment strategies into any DETR-style detector. Our method augments the primary network with multiple Low-Rank Adaptation (LoRA) branches during training, each instantiating a different one-to-many assignment rule. These branches act as auxiliary modules that inject rich, varied supervisory gradients into the main model and are discarded during inference, thus incurring no additional computational cost. This design promotes robust joint optimization while maintaining the architectural simplicity of the original detector. Extensive experiments on different baselines validate the effectiveness of our approach. Our work presents a new paradigm for enhancing detectors, demonstrating that diverse ``one-to-many'' supervision can be integrated to achieve state-of-the-art results without compromising model elegance.
Yggdrasil: Bridging Dynamic Speculation and Static Runtime for Latency-Optimal Tree-Based LLM Decoding
Dec 29, 2025Speculative decoding improves LLM inference by generating and verifying multiple tokens in parallel, but existing systems suffer from suboptimal performance due to a mismatch between dynamic speculation and static runtime assumptions. We present Yggdrasil, a co-designed system that enables latency-optimal speculative decoding through context-aware tree drafting and compiler-friendly execution. Yggdrasil introduces an equal-growth tree structure for static graph compatibility, a latency-aware optimization objective for draft selection, and stage-based scheduling to reduce overhead. Yggdrasil supports unmodified LLMs and achieves up to $3.98\times$ speedup over state-of-the-art baselines across multiple hardware setups.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


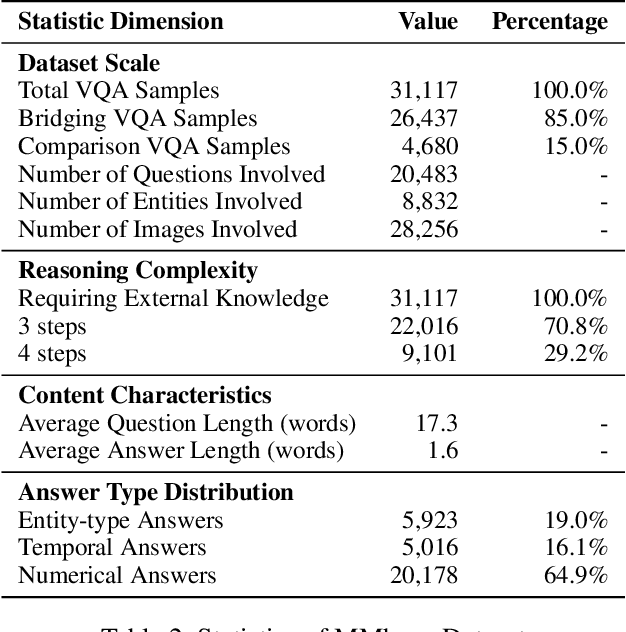
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
Online Segment Any 3D Thing as Instance Tracking
Dec 08, 2025Online, real-time, and fine-grained 3D segmentation constitutes a fundamental capability for embodied intelligent agents to perceive and comprehend their operational environments. Recent advancements employ predefined object queries to aggregate semantic information from Vision Foundation Models (VFMs) outputs that are lifted into 3D point clouds, facilitating spatial information propagation through inter-query interactions. Nevertheless, perception is an inherently dynamic process, rendering temporal understanding a critical yet overlooked dimension within these prevailing query-based pipelines. Therefore, to further unlock the temporal environmental perception capabilities of embodied agents, our work reconceptualizes online 3D segmentation as an instance tracking problem (AutoSeg3D). Our core strategy involves utilizing object queries for temporal information propagation, where long-term instance association promotes the coherence of features and object identities, while short-term instance update enriches instant observations. Given that viewpoint variations in embodied robotics often lead to partial object visibility across frames, this mechanism aids the model in developing a holistic object understanding beyond incomplete instantaneous views. Furthermore, we introduce spatial consistency learning to mitigate the fragmentation problem inherent in VFMs, yielding more comprehensive instance information for enhancing the efficacy of both long-term and short-term temporal learning. The temporal information exchange and consistency learning facilitated by these sparse object queries not only enhance spatial comprehension but also circumvent the computational burden associated with dense temporal point cloud interactions. Our method establishes a new state-of-the-art, surpassing ESAM by 2.8 AP on ScanNet200 and delivering consistent gains on ScanNet, SceneNN, and 3RScan datasets.
Integer Binary-Range Alignment Neuron for Spiking Neural Networks
Jun 06, 2025Spiking Neural Networks (SNNs) are noted for their brain-like computation and energy efficiency, but their performance lags behind Artificial Neural Networks (ANNs) in tasks like image classification and object detection due to the limited representational capacity. To address this, we propose a novel spiking neuron, Integer Binary-Range Alignment Leaky Integrate-and-Fire to exponentially expand the information expression capacity of spiking neurons with only a slight energy increase. This is achieved through Integer Binary Leaky Integrate-and-Fire and range alignment strategy. The Integer Binary Leaky Integrate-and-Fire allows integer value activation during training and maintains spike-driven dynamics with binary conversion expands virtual timesteps during inference. The range alignment strategy is designed to solve the spike activation limitation problem where neurons fail to activate high integer values. Experiments show our method outperforms previous SNNs, achieving 74.19% accuracy on ImageNet and 66.2% mAP@50 and 49.1% mAP@50:95 on COCO, surpassing previous bests with the same architecture by +3.45% and +1.6% and +1.8%, respectively. Notably, our SNNs match or exceed ANNs' performance with the same architecture, and the energy efficiency is improved by 6.3${\times}$.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
PFSD: A Multi-Modal Pedestrian-Focus Scene Dataset for Rich Tasks in Semi-Structured Environments
Feb 24, 2025Recent advancements in autonomous driving perception have revealed exceptional capabilities within structured environments dominated by vehicular traffic. However, current perception models exhibit significant limitations in semi-structured environments, where dynamic pedestrians with more diverse irregular movement and occlusion prevail. We attribute this shortcoming to the scarcity of high-quality datasets in semi-structured scenes, particularly concerning pedestrian perception and prediction. In this work, we present the multi-modal Pedestrian-Focused Scene Dataset(PFSD), rigorously annotated in semi-structured scenes with the format of nuScenes. PFSD provides comprehensive multi-modal data annotations with point cloud segmentation, detection, and object IDs for tracking. It encompasses over 130,000 pedestrian instances captured across various scenarios with varying densities, movement patterns, and occlusions. Furthermore, to demonstrate the importance of addressing the challenges posed by more diverse and complex semi-structured environments, we propose a novel Hybrid Multi-Scale Fusion Network (HMFN). Specifically, to detect pedestrians in densely populated and occluded scenarios, our method effectively captures and fuses multi-scale features using a meticulously designed hybrid framework that integrates sparse and vanilla convolutions. Extensive experiments on PFSD demonstrate that HMFN attains improvement in mean Average Precision (mAP) over existing methods, thereby underscoring its efficacy in addressing the challenges of 3D pedestrian detection in complex semi-structured environments. Coding and benchmark are available.