 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Programming for Multivariate Time Series Prediction
Jun 09, 2023



We introduce the concept of programmable feature engineering for time series modeling and propose a feature programming framework. This framework generates large amounts of predictive features for noisy multivariate time series while allowing users to incorporate their inductive bias with minimal effort. The key motivation of our framework is to view any multivariate time series as a cumulative sum of fine-grained trajectory increments, with each increment governed by a novel spin-gas dynamical Ising model. This fine-grained perspective motivates the development of a parsimonious set of operators that summarize multivariate time series in an abstract fashion, serving as the foundation for large-scale automated feature engineering. Numerically, we validate the efficacy of our method on several synthetic and real-world noisy time series datasets.
Unsupervised Self-Driving Attention Prediction via Uncertainty Mining and Knowledge Embedding
Mar 22, 2023



Predicting attention regions of interest is an important yet challenging task for self-driving systems. Existing methodologies rely on large-scale labeled traffic datasets that are labor-intensive to obtain. Besides, the huge domain gap between natural scenes and traffic scenes in current datasets also limits the potential for model training. To address these challenges, we are the first to introduce an unsupervised way to predict self-driving attention by uncertainty modeling and driving knowledge integration. Our approach's Uncertainty Mining Branch (UMB) discovers commonalities and differences from multiple generated pseudo-labels achieved from models pre-trained on natural scenes by actively measuring the uncertainty. Meanwhile, our Knowledge Embedding Block (KEB) bridges the domain gap by incorporating driving knowledge to adaptively refine the generated pseudo-labels. Quantitative and qualitative results with equivalent or even more impressive performance compared to fully-supervised state-of-the-art approaches across all three public datasets demonstrate the effectiveness of the proposed method and the potential of this direction. The code will be made publicly available.
Interdisciplinary Discovery of Nanomaterials Based on Convolutional Neural Networks
Dec 06, 2022



The material science literature contains up-to-date and comprehensive scientific knowledge of materials. However, their content is unstructured and diverse, resulting in a significant gap in providing sufficient information for material design and synthesis. To this end, we used natural language processing (NLP) and computer vision (CV) techniques based on convolutional neural networks (CNN) to discover valuable experimental-based information about nanomaterials and synthesis methods in energy-material-related publications. Our first system, TextMaster, extracts opinions from texts and classifies them into challenges and opportunities, achieving 94% and 92% accuracy, respectively. Our second system, GraphMaster, realizes data extraction of tables and figures from publications with 98.3\% classification accuracy and 4.3% data extraction mean square error. Our results show that these systems could assess the suitability of materials for a certain application by evaluation of synthesis insights and case analysis with detailed references. This work offers a fresh perspective on mining knowledge from scientific literature, providing a wide swatch to accelerate nanomaterial research through CNN.
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022
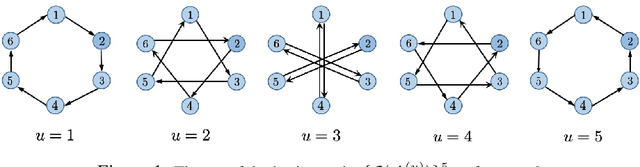
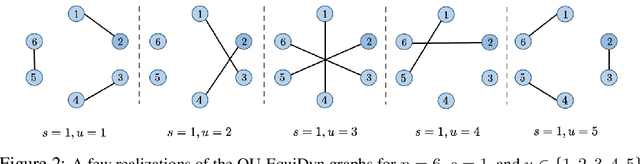

Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Causal Inference via Nonlinear Variable Decorrelation for Healthcare Applications
Sep 29, 2022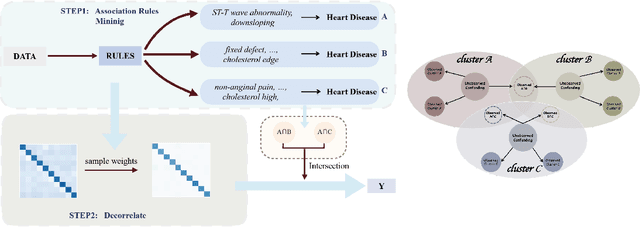
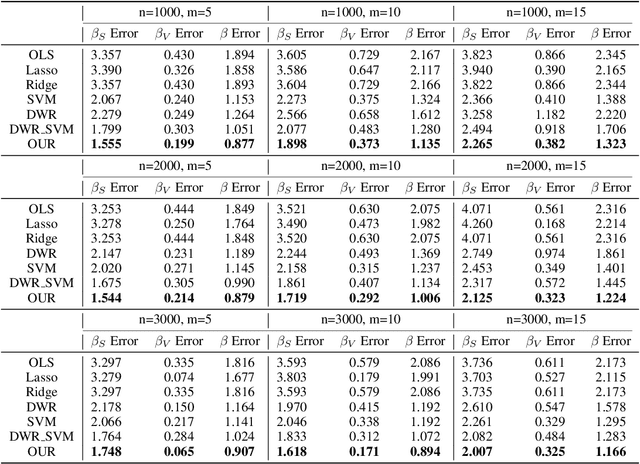
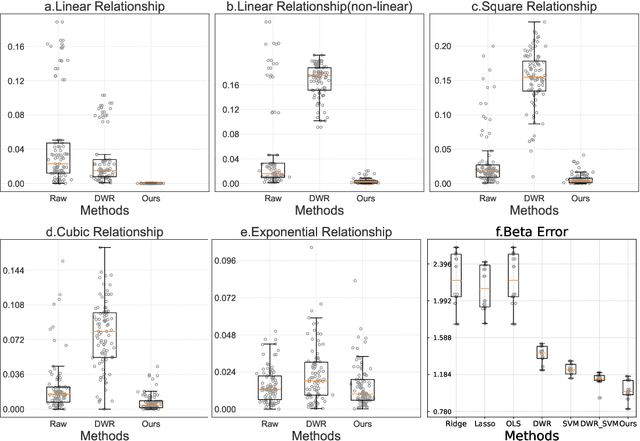
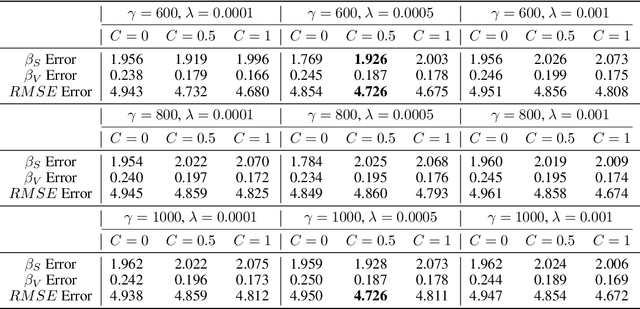
Causal inference and model interpretability research are gaining increasing attention, especially in the domains of healthcare and bioinformatics. Despite recent successes in this field, decorrelating features under nonlinear environments with human interpretable representations has not been adequately investigated. To address this issue, we introduce a novel method with a variable decorrelation regularizer to handle both linear and nonlinear confounding. Moreover, we employ association rules as new representations using association rule mining based on the original features to further proximate human decision patterns to increase model interpretability. Extensive experiments are conducted on four healthcare datasets (one synthetically generated and three real-world collections on different diseases). Quantitative results in comparison to baseline approaches on parameter estimation and causality computation indicate the model's superior performance. Furthermore, expert evaluation given by healthcare professionals validates the effectiveness and interpretability of the proposed model.
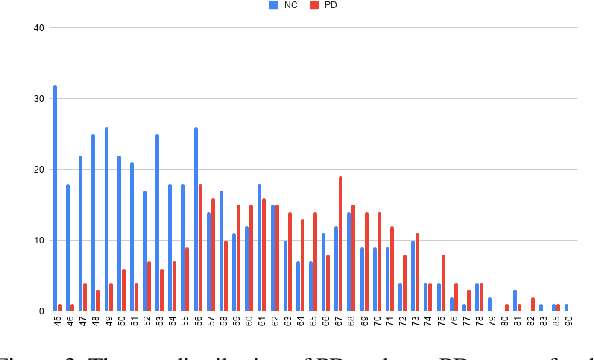
Remote Medication Status Prediction for Individuals with Parkinson's Disease using Time-series Data from Smartphones
Jul 26, 2022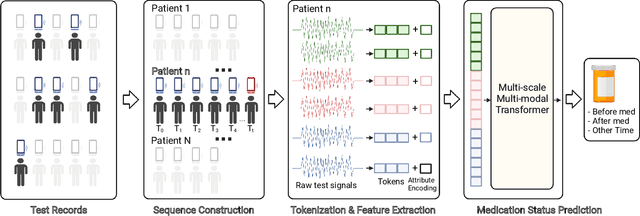
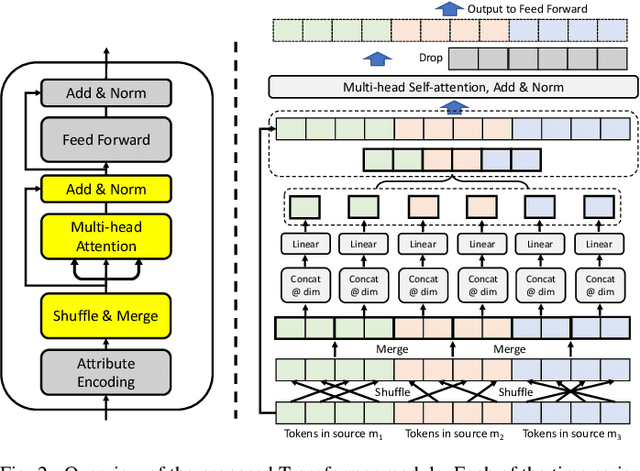
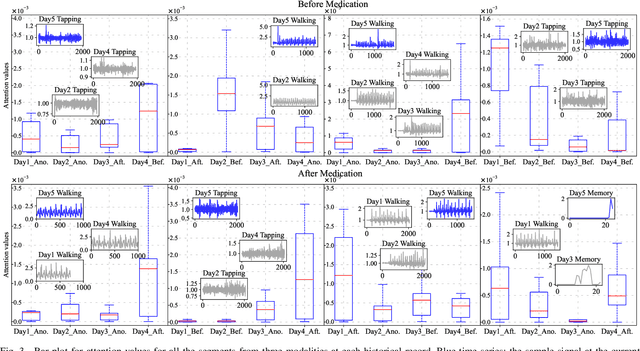
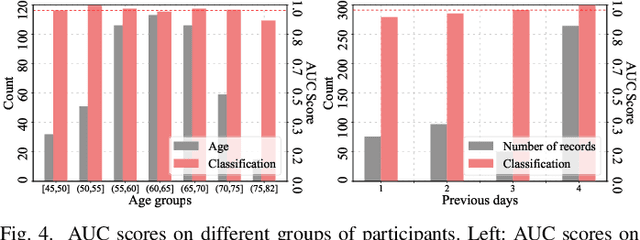
Medication for neurological diseases such as the Parkinson's disease usually happens remotely at home, away from hospitals. Such out-of-lab environments pose challenges in collecting timely and accurate health status data using the limited professional care devices for health condition analysis, medication adherence measurement and future dose or treatment planning. Individual differences in behavioral signals collected from wearable sensors also lead to difficulties in adopting current general machine learning analysis pipelines. To address these challenges, we present a method for predicting medication status of Parkinson's disease patients using the public mPower dataset, which contains 62,182 remote multi-modal test records collected on smartphones from 487 patients. The proposed method shows promising results in predicting three medication status objectively: Before Medication (AUC=0.95), After Medication (AUC=0.958), and Another Time (AUC=0.976) by examining patient-wise historical records with the attention weights learned through a Transformer model. We believe our method provides an innovative way for personalized remote health sensing in a timely and objective fashion which could benefit a broad range of similar applications.
Product Information Browsing Support System Using Analytic Hierarchy Process
Dec 17, 2021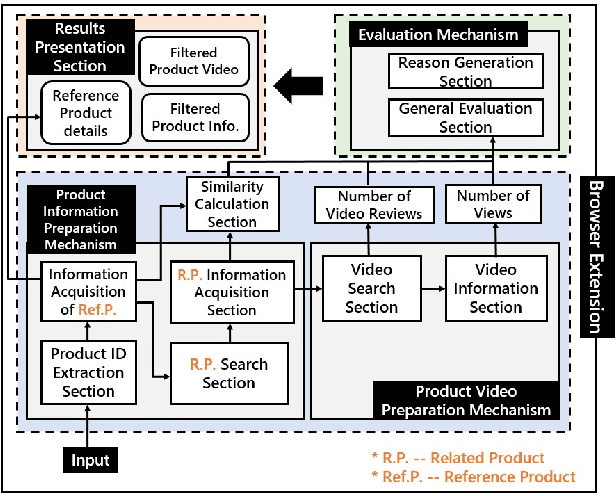
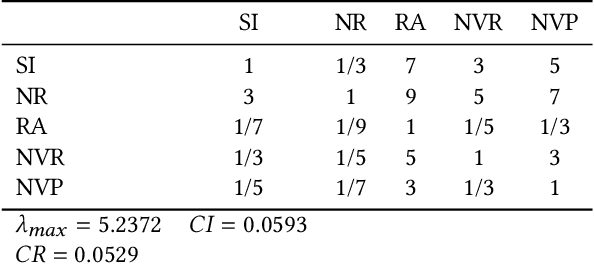

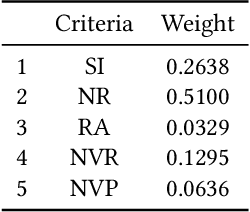
Large-scale e-commerce sites can collect and analyze a large number of user preferences and behaviors, and thus can recommend highly trusted products to users. However, it is very difficult for individuals or non-corporate groups to obtain large-scale user data. Therefore, we consider whether knowledge of the decision-making domain can be used to obtain user preferences and combine it with content-based filtering to design an information retrieval system. This study describes the process of building a product information browsing support system with high satisfaction based on product similarity and multiple other perspectives about products on the Internet. We present the architecture of the proposed system and explain the working principle of its constituent modules. Finally, we demonstrate the effectiveness of the proposed system through an evaluation experiment and a questionnaire.
Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization
Aug 13, 2021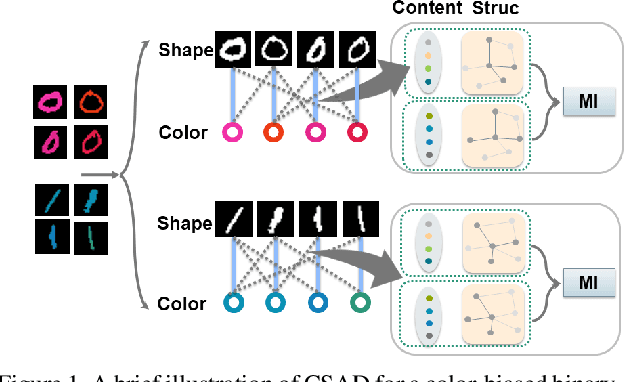
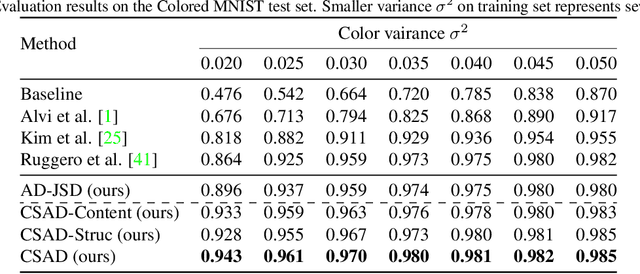
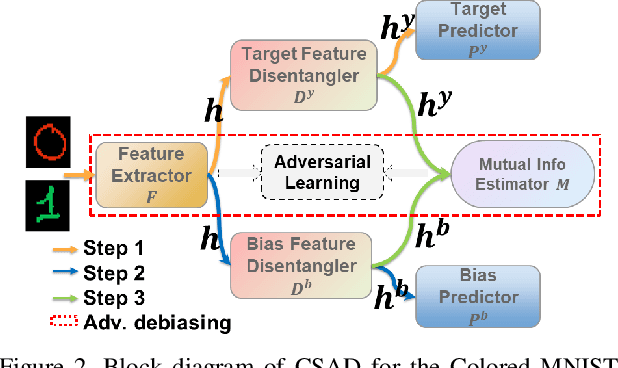
Deep learning algorithms mine knowledge from the training data and thus would likely inherit the dataset's bias information. As a result, the obtained model would generalize poorly and even mislead the decision process in real-life applications. We propose to remove the bias information misused by the target task with a cross-sample adversarial debiasing (CSAD) method. CSAD explicitly extracts target and bias features disentangled from the latent representation generated by a feature extractor and then learns to discover and remove the correlation between the target and bias features. The correlation measurement plays a critical role in adversarial debiasing and is conducted by a cross-sample neural mutual information estimator. Moreover, we propose joint content and local structural representation learning to boost mutual information estimation for better performance. We conduct thorough experiments on publicly available datasets to validate the advantages of the proposed method over state-of-the-art approaches.
ConTNet: Why not use convolution and transformer at the same time?
May 10, 2021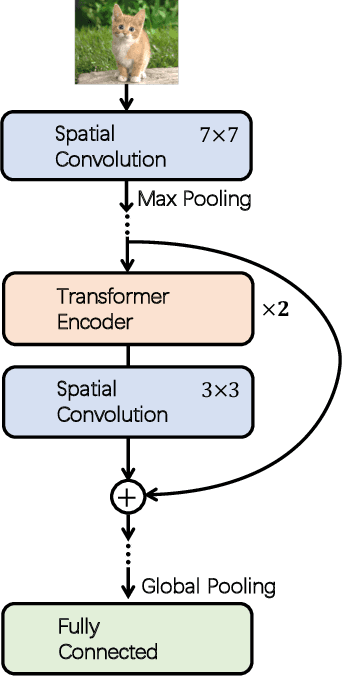
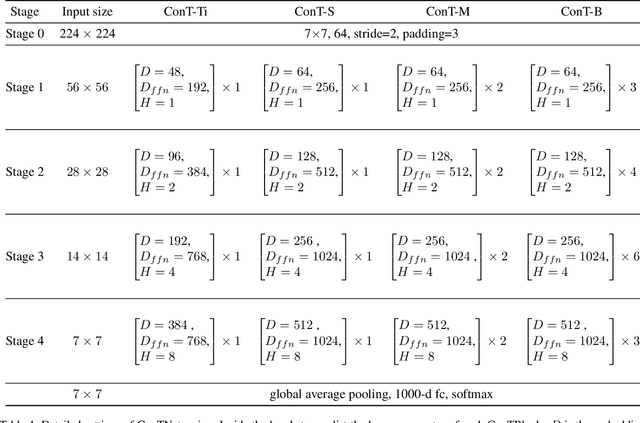

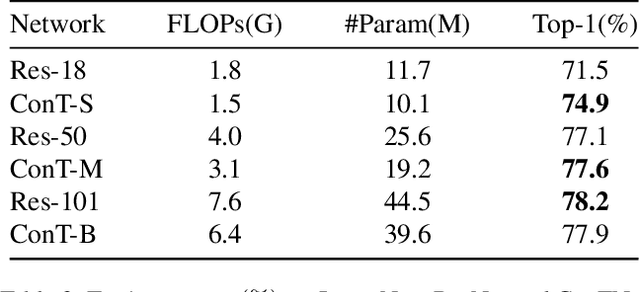
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
Scalable Semi-supervised Landmark Localization for X-ray Images using Few-shot Deep Adaptive Graph
Apr 29, 2021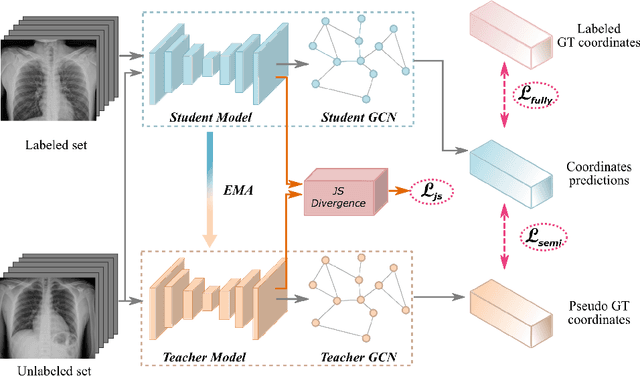
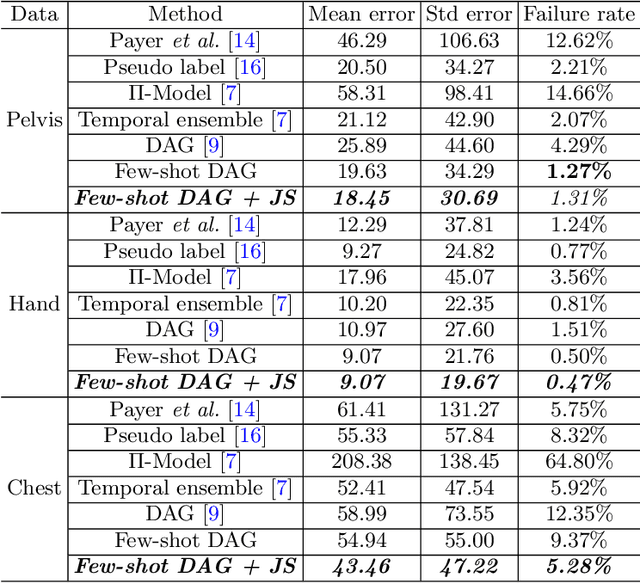
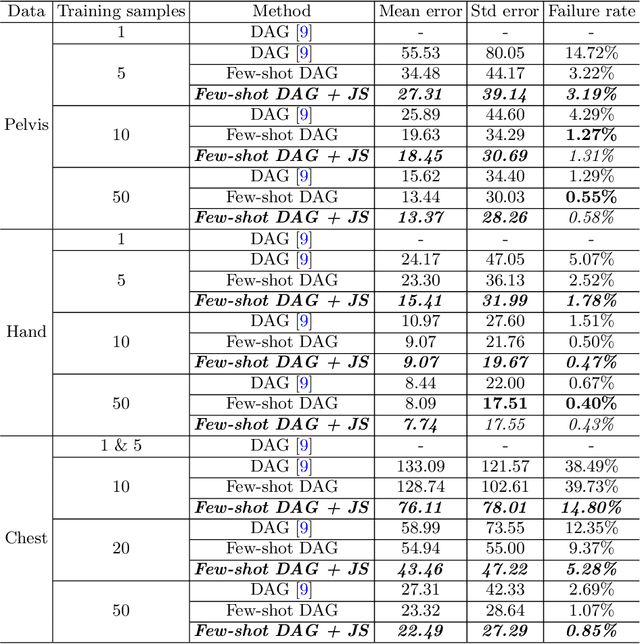
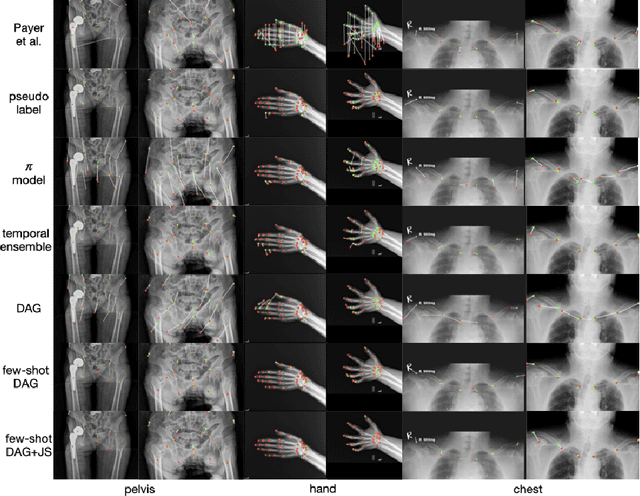
Landmark localization plays an important role in medical image analysis. Learning based methods, including CNN and GCN, have demonstrated the state-of-the-art performance. However, most of these methods are fully-supervised and heavily rely on manual labeling of a large training dataset. In this paper, based on a fully-supervised graph-based method, DAG, we proposed a semi-supervised extension of it, termed few-shot DAG, \ie five-shot DAG. It first trains a DAG model on the labeled data and then fine-tunes the pre-trained model on the unlabeled data with a teacher-student SSL mechanism. In addition to the semi-supervised loss, we propose another loss using JS divergence to regulate the consistency of the intermediate feature maps. We extensively evaluated our method on pelvis, hand and chest landmark detection tasks. Our experiment results demonstrate consistent and significant improvements over previous methods.