 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Responsibility-Attributed Adversarial Scenarios for Testing Autonomous Vehicles
May 13, 2026Establishing trustworthy safety assurance for autonomous driving systems (ADSs) requires evidence that failures arise from avoidable system deficiencies rather than unavoidable traffic conflicts. Current adversarial simulation methods can efficiently expose collisions, but generally lack mechanisms to distinguish these fundamentally different failure modes. Here we present CARS (Context-Aware, Responsibility-attributed Scenario generation), a framework that integrates responsibility attribution directly into adversarial scenario generation. CARS combines context-aware adversary selection with a generative adversarial policy optimized in closed-loop simulation to construct collision scenarios that are both physically feasible and diagnostically attributable. Across benchmark datasets spanning heterogeneous national traffic environments, CARS consistently discovers feasible collision scenarios with high attribution rates under multiple regulation-prescribed careful and competent driver models. By coupling adversarial generation with normative responsibility assessment, CARS moves simulation testing beyond collision discovery toward the construction of interpretable, regulation-aligned safety evidence for scalable ADS validation.
Multi-Scale Representations by Varying Window Attention for Semantic Segmentation
Apr 26, 2024Multi-scale learning is central to semantic segmentation. We visualize the effective receptive field (ERF) of canonical multi-scale representations and point out two risks in learning them: scale inadequacy and field inactivation. A novel multi-scale learner, varying window attention (VWA), is presented to address these issues. VWA leverages the local window attention (LWA) and disentangles LWA into the query window and context window, allowing the context's scale to vary for the query to learn representations at multiple scales. However, varying the context to large-scale windows (enlarging ratio R) can significantly increase the memory footprint and computation cost (R^2 times larger than LWA). We propose a simple but professional re-scaling strategy to zero the extra induced cost without compromising performance. Consequently, VWA uses the same cost as LWA to overcome the receptive limitation of the local window. Furthermore, depending on VWA and employing various MLPs, we introduce a multi-scale decoder (MSD), VWFormer, to improve multi-scale representations for semantic segmentation. VWFormer achieves efficiency competitive with the most compute-friendly MSDs, like FPN and MLP decoder, but performs much better than any MSDs. For instance, using nearly half of UPerNet's computation, VWFormer outperforms it by 1.0%-2.5% mIoU on ADE20K. With little extra overhead, ~10G FLOPs, Mask2Former armed with VWFormer improves by 1.0%-1.3%. The code and models are available at https://github.com/yan-hao-tian/vw
Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Jan 05, 2022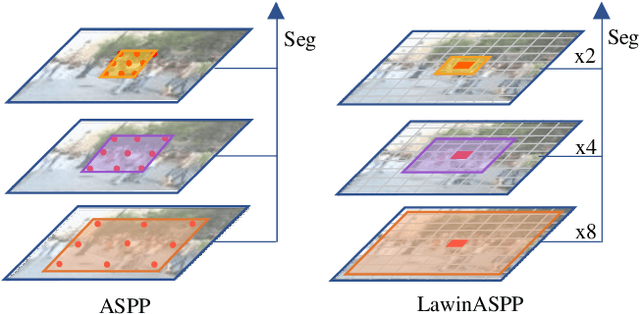
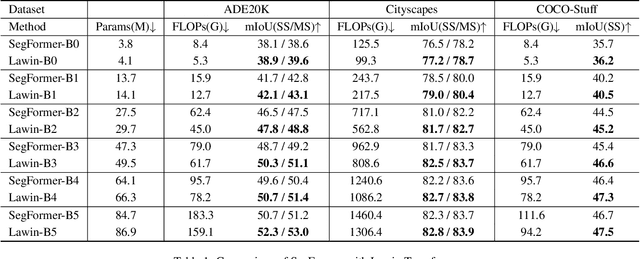
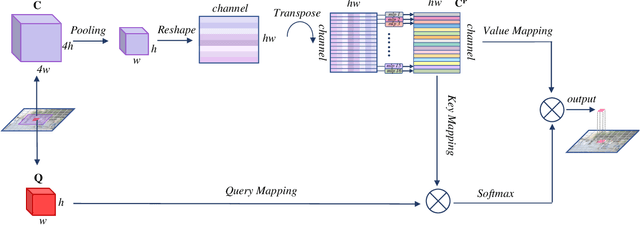
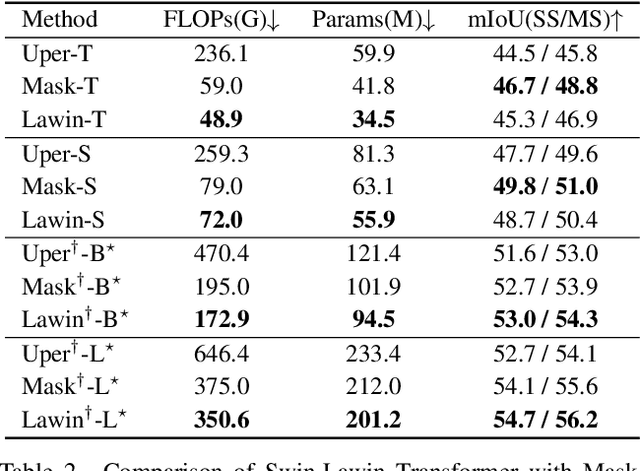
Multi-scale representations are crucial for semantic segmentation. The community has witnessed the flourish of semantic segmentation convolutional neural networks (CNN) exploiting multi-scale contextual information. Motivated by that the vision transformer (ViT) is powerful in image classification, some semantic segmentation ViTs are recently proposed, most of them attaining impressive results but at a cost of computational economy. In this paper, we succeed in introducing multi-scale representations into semantic segmentation ViT via window attention mechanism and further improves the performance and efficiency. To this end, we introduce large window attention which allows the local window to query a larger area of context window at only a little computation overhead. By regulating the ratio of the context area to the query area, we enable the large window attention to capture the contextual information at multiple scales. Moreover, the framework of spatial pyramid pooling is adopted to collaborate with the large window attention, which presents a novel decoder named large window attention spatial pyramid pooling (LawinASPP) for semantic segmentation ViT. Our resulting ViT, Lawin Transformer, is composed of an efficient hierachical vision transformer (HVT) as encoder and a LawinASPP as decoder. The empirical results demonstrate that Lawin Transformer offers an improved efficiency compared to the existing method. Lawin Transformer further sets new state-of-the-art performance on Cityscapes (84.4\% mIoU), ADE20K (56.2\% mIoU) and COCO-Stuff datasets. The code will be released at https://github.com/yan-hao-tian/lawin.
ConTNet: Why not use convolution and transformer at the same time?
May 10, 2021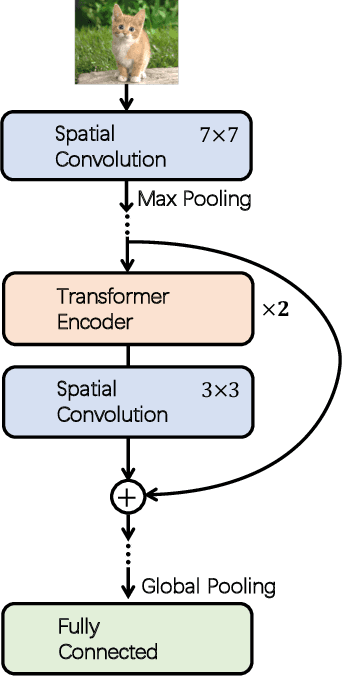
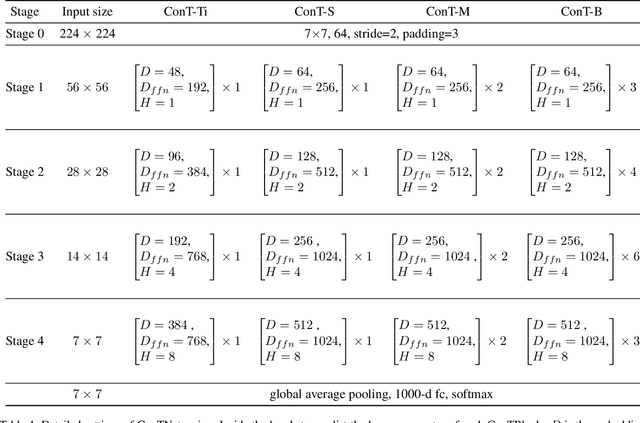

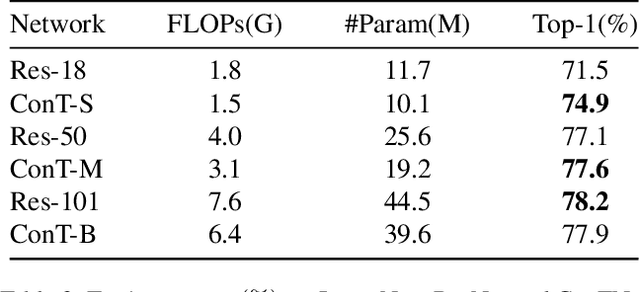
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design