 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Methodologies: Scaling Test Time Computation without Training
Jun 08, 2025Large Language Models (LLMs) often struggle with complex reasoning tasks due to insufficient in-depth insights in their training data, which are typically absent in publicly available documents. This paper introduces the Chain of Methodologies (CoM), an innovative and intuitive prompting framework that enhances structured thinking by integrating human methodological insights, enabling LLMs to tackle complex tasks with extended reasoning. CoM leverages the metacognitive abilities of advanced LLMs, activating systematic reasoning throught user-defined methodologies without explicit fine-tuning. Experiments show that CoM surpasses competitive baselines, demonstrating the potential of training-free prompting methods as robust solutions for complex reasoning tasks and bridging the gap toward human-level reasoning through human-like methodological insights.
Reinforcing Video Reasoning with Focused Thinking
May 30, 2025Recent advancements in reinforcement learning, particularly through Group Relative Policy Optimization (GRPO), have significantly improved multimodal large language models for complex reasoning tasks. However, two critical limitations persist: 1) they often produce unfocused, verbose reasoning chains that obscure salient spatiotemporal cues and 2) binary rewarding fails to account for partially correct answers, resulting in high reward variance and inefficient learning. In this paper, we propose TW-GRPO, a novel framework that enhances visual reasoning with focused thinking and dense reward granularity. Specifically, we employs a token weighting mechanism that prioritizes tokens with high informational density (estimated by intra-group variance), suppressing redundant tokens like generic reasoning prefixes. Furthermore, we reformulate RL training by shifting from single-choice to multi-choice QA tasks, where soft rewards enable finer-grained gradient estimation by distinguishing partial correctness. Additionally, we propose question-answer inversion, a data augmentation strategy to generate diverse multi-choice samples from existing benchmarks. Experiments demonstrate state-of-the-art performance on several video reasoning and general understanding benchmarks. Notably, TW-GRPO achieves 50.4\% accuracy on CLEVRER (18.8\% improvement over Video-R1) and 65.8\% on MMVU. Our codes are available at \href{https://github.com/longmalongma/TW-GRPO}{https://github.com/longmalongma/TW-GRPO}.
Long-RVOS: A Comprehensive Benchmark for Long-term Referring Video Object Segmentation
May 19, 2025Referring video object segmentation (RVOS) aims to identify, track and segment the objects in a video based on language descriptions, which has received great attention in recent years. However, existing datasets remain focus on short video clips within several seconds, with salient objects visible in most frames. To advance the task towards more practical scenarios, we introduce \textbf{Long-RVOS}, a large-scale benchmark for long-term referring video object segmentation. Long-RVOS contains 2,000+ videos of an average duration exceeding 60 seconds, covering a variety of objects that undergo occlusion, disappearance-reappearance and shot changing. The objects are manually annotated with three different types of descriptions to individually evaluate the understanding of static attributes, motion patterns and spatiotemporal relationships. Moreover, unlike previous benchmarks that rely solely on the per-frame spatial evaluation, we introduce two new metrics to assess the temporal and spatiotemporal consistency. We benchmark 6 state-of-the-art methods on Long-RVOS. The results show that current approaches struggle severely with the long-video challenges. To address this, we further propose ReferMo, a promising baseline method that integrates motion information to expand the temporal receptive field, and employs a local-to-global architecture to capture both short-term dynamics and long-term dependencies. Despite simplicity, ReferMo achieves significant improvements over current methods in long-term scenarios. We hope that Long-RVOS and our baseline can drive future RVOS research towards tackling more realistic and long-form videos.
ActionArt: Advancing Multimodal Large Models for Fine-Grained Human-Centric Video Understanding
Apr 25, 2025



Fine-grained understanding of human actions and poses in videos is essential for human-centric AI applications. In this work, we introduce ActionArt, a fine-grained video-caption dataset designed to advance research in human-centric multimodal understanding. Our dataset comprises thousands of videos capturing a broad spectrum of human actions, human-object interactions, and diverse scenarios, each accompanied by detailed annotations that meticulously label every limb movement. We develop eight sub-tasks to evaluate the fine-grained understanding capabilities of existing large multimodal models across different dimensions. Experimental results indicate that, while current large multimodal models perform commendably on various tasks, they often fall short in achieving fine-grained understanding. We attribute this limitation to the scarcity of meticulously annotated data, which is both costly and difficult to scale manually. Since manual annotations are costly and hard to scale, we propose proxy tasks to enhance the model perception ability in both spatial and temporal dimensions. These proxy tasks are carefully crafted to be driven by data automatically generated from existing MLLMs, thereby reducing the reliance on costly manual labels. Experimental results show that the proposed proxy tasks significantly narrow the gap toward the performance achieved with manually annotated fine-grained data.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025



This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
Modeling Multiple Normal Action Representations for Error Detection in Procedural Tasks
Apr 02, 2025



Error detection in procedural activities is essential for consistent and correct outcomes in AR-assisted and robotic systems. Existing methods often focus on temporal ordering errors or rely on static prototypes to represent normal actions. However, these approaches typically overlook the common scenario where multiple, distinct actions are valid following a given sequence of executed actions. This leads to two issues: (1) the model cannot effectively detect errors using static prototypes when the inference environment or action execution distribution differs from training; and (2) the model may also use the wrong prototypes to detect errors if the ongoing action label is not the same as the predicted one. To address this problem, we propose an Adaptive Multiple Normal Action Representation (AMNAR) framework. AMNAR predicts all valid next actions and reconstructs their corresponding normal action representations, which are compared against the ongoing action to detect errors. Extensive experiments demonstrate that AMNAR achieves state-of-the-art performance, highlighting the effectiveness of AMNAR and the importance of modeling multiple valid next actions in error detection. The code is available at https://github.com/iSEE-Laboratory/AMNAR.
Decoupled Distillation to Erase: A General Unlearning Method for Any Class-centric Tasks
Mar 31, 2025In this work, we present DEcoupLEd Distillation To Erase (DELETE), a general and strong unlearning method for any class-centric tasks. To derive this, we first propose a theoretical framework to analyze the general form of unlearning loss and decompose it into forgetting and retention terms. Through the theoretical framework, we point out that a class of previous methods could be mainly formulated as a loss that implicitly optimizes the forgetting term while lacking supervision for the retention term, disturbing the distribution of pre-trained model and struggling to adequately preserve knowledge of the remaining classes. To address it, we refine the retention term using "dark knowledge" and propose a mask distillation unlearning method. By applying a mask to separate forgetting logits from retention logits, our approach optimizes both the forgetting and refined retention components simultaneously, retaining knowledge of the remaining classes while ensuring thorough forgetting of the target class. Without access to the remaining data or intervention (i.e., used in some works), we achieve state-of-the-art performance across various benchmarks. What's more, DELETE is a general solution that can be applied to various downstream tasks, including face recognition, backdoor defense, and semantic segmentation with great performance.
ReferDINO-Plus: 2nd Solution for 4th PVUW MeViS Challenge at CVPR 2025
Mar 30, 2025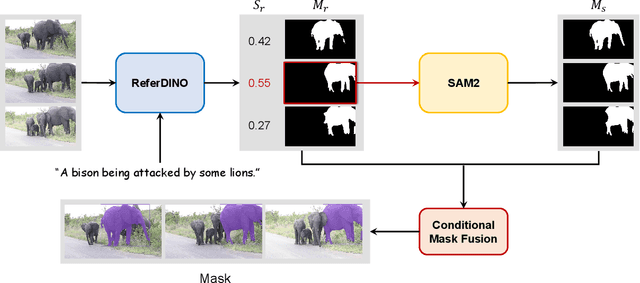
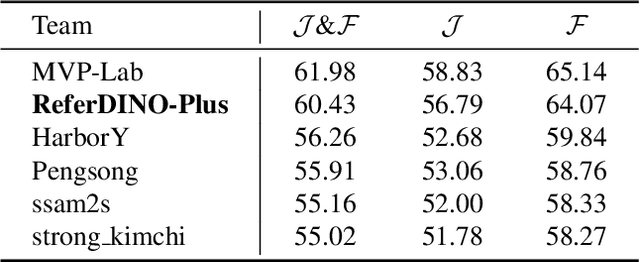

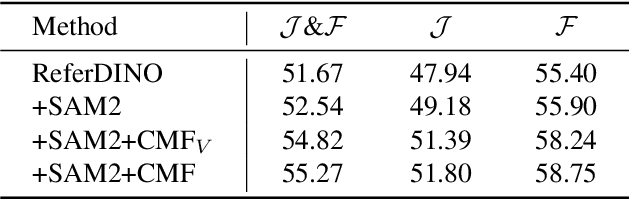
Referring Video Object Segmentation (RVOS) aims to segment target objects throughout a video based on a text description. This task has attracted increasing attention in the field of computer vision due to its promising applications in video editing and human-agent interaction. Recently, ReferDINO has demonstrated promising performance in this task by adapting object-level vision-language knowledge from pretrained foundational image models. In this report, we further enhance its capabilities by incorporating the advantages of SAM2 in mask quality and object consistency. In addition, to effectively balance performance between single-object and multi-object scenarios, we introduce a conditional mask fusion strategy that adaptively fuses the masks from ReferDINO and SAM2. Our solution, termed ReferDINO-Plus, achieves 60.43 \(\mathcal{J}\&\mathcal{F}\) on MeViS test set, securing 2nd place in the MeViS PVUW challenge at CVPR 2025. The code is available at: https://github.com/iSEE-Laboratory/ReferDINO-Plus.
Efficient Explicit Joint-level Interaction Modeling with Mamba for Text-guided HOI Generation
Mar 29, 2025



We propose a novel approach for generating text-guided human-object interactions (HOIs) that achieves explicit joint-level interaction modeling in a computationally efficient manner. Previous methods represent the entire human body as a single token, making it difficult to capture fine-grained joint-level interactions and resulting in unrealistic HOIs. However, treating each individual joint as a token would yield over twenty times more tokens, increasing computational overhead. To address these challenges, we introduce an Efficient Explicit Joint-level Interaction Model (EJIM). EJIM features a Dual-branch HOI Mamba that separately and efficiently models spatiotemporal HOI information, as well as a Dual-branch Condition Injector for integrating text semantics and object geometry into human and object motions. Furthermore, we design a Dynamic Interaction Block and a progressive masking mechanism to iteratively filter out irrelevant joints, ensuring accurate and nuanced interaction modeling. Extensive quantitative and qualitative evaluations on public datasets demonstrate that EJIM surpasses previous works by a large margin while using only 5\% of the inference time. Code is available \href{https://github.com/Huanggh531/EJIM}{here}.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.