 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTubeRMC: Tube-conditioned Reconstruction with Mutual Constraints for Weakly-supervised Spatio-Temporal Video Grounding
Nov 13, 2025Spatio-Temporal Video Grounding (STVG) aims to localize a spatio-temporal tube that corresponds to a given language query in an untrimmed video. This is a challenging task since it involves complex vision-language understanding and spatiotemporal reasoning. Recent works have explored weakly-supervised setting in STVG to eliminate reliance on fine-grained annotations like bounding boxes or temporal stamps. However, they typically follow a simple late-fusion manner, which generates tubes independent of the text description, often resulting in failed target identification and inconsistent target tracking. To address this limitation, we propose a Tube-conditioned Reconstruction with Mutual Constraints (\textbf{TubeRMC}) framework that generates text-conditioned candidate tubes with pre-trained visual grounding models and further refine them via tube-conditioned reconstruction with spatio-temporal constraints. Specifically, we design three reconstruction strategies from temporal, spatial, and spatio-temporal perspectives to comprehensively capture rich tube-text correspondences. Each strategy is equipped with a Tube-conditioned Reconstructor, utilizing spatio-temporal tubes as condition to reconstruct the key clues in the query. We further introduce mutual constraints between spatial and temporal proposals to enhance their quality for reconstruction. TubeRMC outperforms existing methods on two public benchmarks VidSTG and HCSTVG. Further visualization shows that TubeRMC effectively mitigates both target identification errors and inconsistent tracking.
Long-RVOS: A Comprehensive Benchmark for Long-term Referring Video Object Segmentation
May 19, 2025Referring video object segmentation (RVOS) aims to identify, track and segment the objects in a video based on language descriptions, which has received great attention in recent years. However, existing datasets remain focus on short video clips within several seconds, with salient objects visible in most frames. To advance the task towards more practical scenarios, we introduce \textbf{Long-RVOS}, a large-scale benchmark for long-term referring video object segmentation. Long-RVOS contains 2,000+ videos of an average duration exceeding 60 seconds, covering a variety of objects that undergo occlusion, disappearance-reappearance and shot changing. The objects are manually annotated with three different types of descriptions to individually evaluate the understanding of static attributes, motion patterns and spatiotemporal relationships. Moreover, unlike previous benchmarks that rely solely on the per-frame spatial evaluation, we introduce two new metrics to assess the temporal and spatiotemporal consistency. We benchmark 6 state-of-the-art methods on Long-RVOS. The results show that current approaches struggle severely with the long-video challenges. To address this, we further propose ReferMo, a promising baseline method that integrates motion information to expand the temporal receptive field, and employs a local-to-global architecture to capture both short-term dynamics and long-term dependencies. Despite simplicity, ReferMo achieves significant improvements over current methods in long-term scenarios. We hope that Long-RVOS and our baseline can drive future RVOS research towards tackling more realistic and long-form videos.
ReferDINO: Referring Video Object Segmentation with Visual Grounding Foundations
Jan 24, 2025



Referring video object segmentation (RVOS) aims to segment target objects throughout a video based on a text description. Despite notable progress in recent years, current RVOS models remain struggle to handle complicated object descriptions due to their limited video-language understanding. To address this limitation, we present \textbf{ReferDINO}, an end-to-end RVOS model that inherits strong vision-language understanding from the pretrained visual grounding foundation models, and is further endowed with effective temporal understanding and object segmentation capabilities. In ReferDINO, we contribute three technical innovations for effectively adapting the foundation models to RVOS: 1) an object-consistent temporal enhancer that capitalizes on the pretrained object-text representations to enhance temporal understanding and object consistency; 2) a grounding-guided deformable mask decoder that integrates text and grounding conditions to generate accurate object masks; 3) a confidence-aware query pruning strategy that significantly improves the object decoding efficiency without compromising performance. We conduct extensive experiments on five public RVOS benchmarks to demonstrate that our proposed ReferDINO outperforms state-of-the-art methods significantly. Project page: \url{https://isee-laboratory.github.io/ReferDINO}
SAUGE: Taming SAM for Uncertainty-Aligned Multi-Granularity Edge Detection
Dec 17, 2024Edge labels are typically at various granularity levels owing to the varying preferences of annotators, thus handling the subjectivity of per-pixel labels has been a focal point for edge detection. Previous methods often employ a simple voting strategy to diminish such label uncertainty or impose a strong assumption of labels with a pre-defined distribution, e.g., Gaussian. In this work, we unveil that the segment anything model (SAM) provides strong prior knowledge to model the uncertainty in edge labels. Our key insight is that the intermediate SAM features inherently correspond to object edges at various granularities, which reflects different edge options due to uncertainty. Therefore, we attempt to align uncertainty with granularity by regressing intermediate SAM features from different layers to object edges at multi-granularity levels. In doing so, the model can fully and explicitly explore diverse ``uncertainties'' in a data-driven fashion. Specifically, we inject a lightweight module (~ 1.5% additional parameters) into the frozen SAM to progressively fuse and adapt its intermediate features to estimate edges from coarse to fine. It is crucial to normalize the granularity level of human edge labels to match their innate uncertainty. For this, we simply perform linear blending to the real edge labels at hand to create pseudo labels with varying granularities. Consequently, our uncertainty-aligned edge detector can flexibly produce edges at any desired granularity (including an optimal one). Thanks to SAM, our model uniquely demonstrates strong generalizability for cross-dataset edge detection. Extensive experimental results on BSDS500, Muticue and NYUDv2 validate our model's superiority.
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Aug 07, 2024



Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
Ranking Distillation for Open-Ended Video Question Answering with Insufficient Labels
Mar 21, 2024



This paper focuses on open-ended video question answering, which aims to find the correct answers from a large answer set in response to a video-related question. This is essentially a multi-label classification task, since a question may have multiple answers. However, due to annotation costs, the labels in existing benchmarks are always extremely insufficient, typically one answer per question. As a result, existing works tend to directly treat all the unlabeled answers as negative labels, leading to limited ability for generalization. In this work, we introduce a simple yet effective ranking distillation framework (RADI) to mitigate this problem without additional manual annotation. RADI employs a teacher model trained with incomplete labels to generate rankings for potential answers, which contain rich knowledge about label priority as well as label-associated visual cues, thereby enriching the insufficient labeling information. To avoid overconfidence in the imperfect teacher model, we further present two robust and parameter-free ranking distillation approaches: a pairwise approach which introduces adaptive soft margins to dynamically refine the optimization constraints on various pairwise rankings, and a listwise approach which adopts sampling-based partial listwise learning to resist the bias in teacher ranking. Extensive experiments on five popular benchmarks consistently show that both our pairwise and listwise RADIs outperform state-of-the-art methods. Further analysis demonstrates the effectiveness of our methods on the insufficient labeling problem.
Siamese Learning with Joint Alignment and Regression for Weakly-Supervised Video Paragraph Grounding
Mar 18, 2024



Video Paragraph Grounding (VPG) is an emerging task in video-language understanding, which aims at localizing multiple sentences with semantic relations and temporal order from an untrimmed video. However, existing VPG approaches are heavily reliant on a considerable number of temporal labels that are laborious and time-consuming to acquire. In this work, we introduce and explore Weakly-Supervised Video Paragraph Grounding (WSVPG) to eliminate the need of temporal annotations. Different from previous weakly-supervised grounding frameworks based on multiple instance learning or reconstruction learning for two-stage candidate ranking, we propose a novel siamese learning framework that jointly learns the cross-modal feature alignment and temporal coordinate regression without timestamp labels to achieve concise one-stage localization for WSVPG. Specifically, we devise a Siamese Grounding TRansformer (SiamGTR) consisting of two weight-sharing branches for learning complementary supervision. An Augmentation Branch is utilized for directly regressing the temporal boundaries of a complete paragraph within a pseudo video, and an Inference Branch is designed to capture the order-guided feature correspondence for localizing multiple sentences in a normal video. We demonstrate by extensive experiments that our paradigm has superior practicability and flexibility to achieve efficient weakly-supervised or semi-supervised learning, outperforming state-of-the-art methods trained with the same or stronger supervision.
STVGFormer: Spatio-Temporal Video Grounding with Static-Dynamic Cross-Modal Understanding
Jul 06, 2022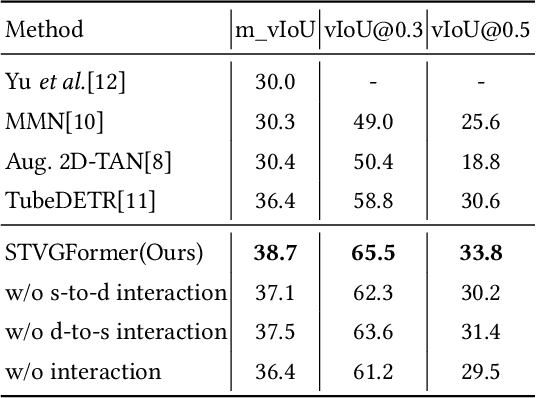
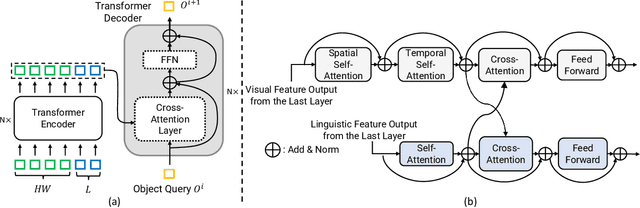
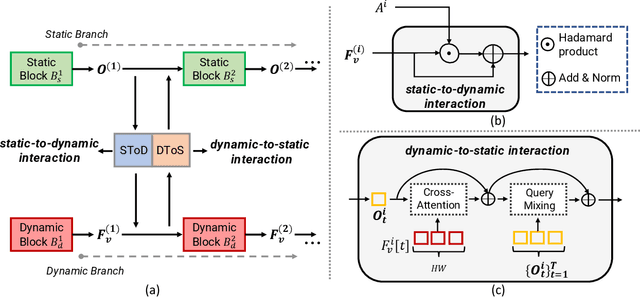
In this technical report, we introduce our solution to human-centric spatio-temporal video grounding task. We propose a concise and effective framework named STVGFormer, which models spatiotemporal visual-linguistic dependencies with a static branch and a dynamic branch. The static branch performs cross-modal understanding in a single frame and learns to localize the target object spatially according to intra-frame visual cues like object appearances. The dynamic branch performs cross-modal understanding across multiple frames. It learns to predict the starting and ending time of the target moment according to dynamic visual cues like motions. Both the static and dynamic branches are designed as cross-modal transformers. We further design a novel static-dynamic interaction block to enable the static and dynamic branches to transfer useful and complementary information from each other, which is shown to be effective to improve the prediction on hard cases. Our proposed method achieved 39.6% vIoU and won the first place in the HC-STVG track of the 4th Person in Context Challenge.
Augmented 2D-TAN: A Two-stage Approach for Human-centric Spatio-Temporal Video Grounding
Jun 20, 2021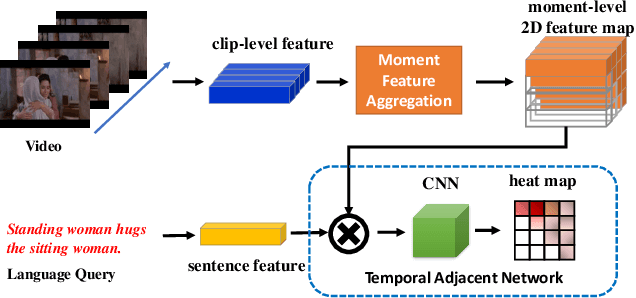
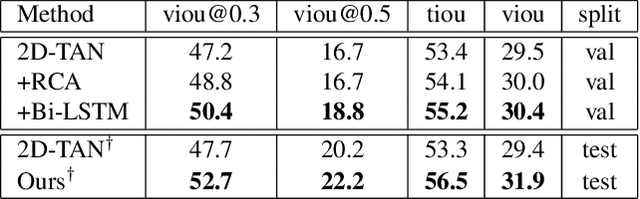
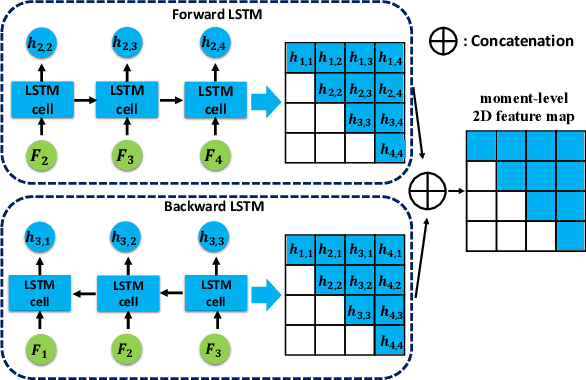
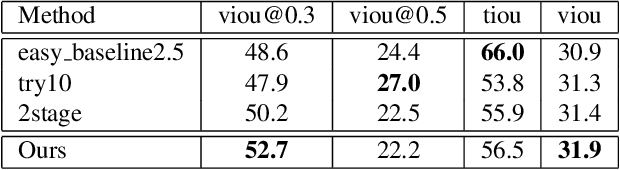
We propose an effective two-stage approach to tackle the problem of language-based Human-centric Spatio-Temporal Video Grounding (HC-STVG) task. In the first stage, we propose an Augmented 2D Temporal Adjacent Network (Augmented 2D-TAN) to temporally ground the target moment corresponding to the given description. Primarily, we improve the original 2D-TAN from two aspects: First, a temporal context-aware Bi-LSTM Aggregation Module is developed to aggregate clip-level representations, replacing the original max-pooling. Second, we propose to employ Random Concatenation Augmentation (RCA) mechanism during the training phase. In the second stage, we use pretrained MDETR model to generate per-frame bounding boxes via language query, and design a set of hand-crafted rules to select the best matching bounding box outputted by MDETR for each frame within the grounded moment.